Downloaded 14 times




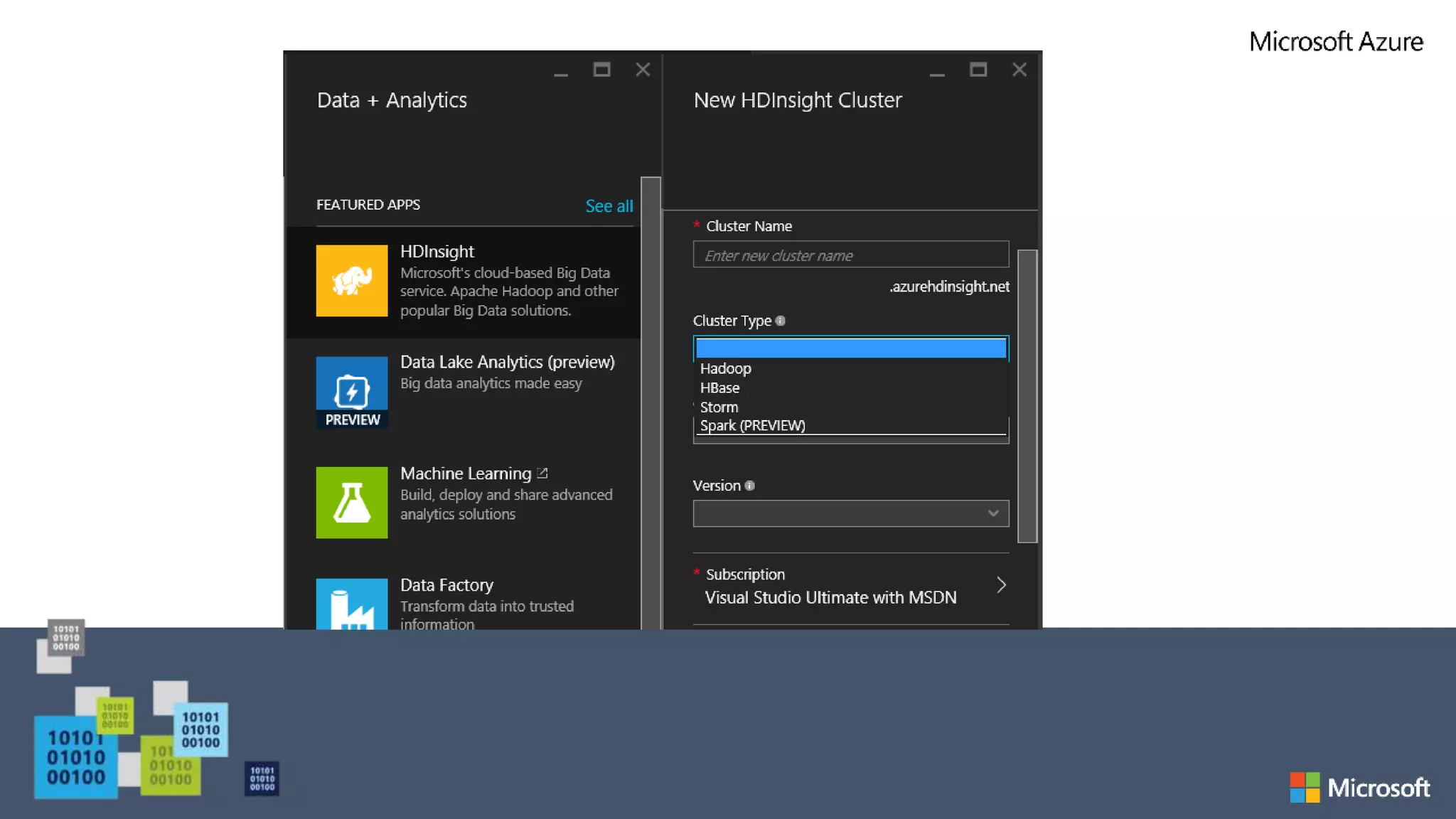













The document provides an overview of Azure HDInsight, Microsoft's cloud implementation of the Hadoop ecosystem, detailing its components such as HBase, Storm, and Spark. It explains the functionalities of these tools for managing and processing large-scale data, emphasizing the advantages of using HDInsight in terms of hardware maintenance and programming flexibility. Additionally, it highlights the capabilities of HBase as a NoSQL database and Apache Hive for querying and analyzing data, along with the real-time data processing powers of Apache Storm.




























































![[Azureビッグデータ関連サービスとHortonworks勉強会] Azure HDInsight](https://cdn.slidesharecdn.com/ss_thumbnails/20160719hortonworksmeetuphdinsight-160721074805-thumbnail.jpg?width=640&height=640&fit=bounds)









































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)