1) The document discusses big data, including how it is defined, challenges of working with large datasets, and solutions like Hadoop.
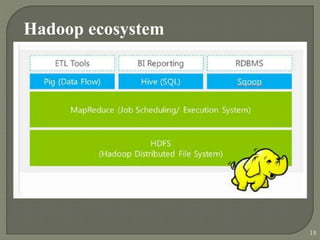
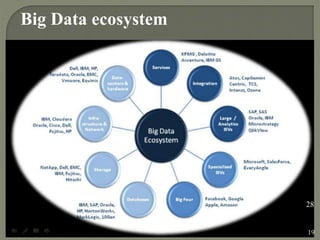
2) It explains that big data refers to datasets that are too large to be handled by traditional database tools due to their scale, diversity and complexity. Hadoop is presented as a solution for reliably storing and processing big data across clusters of commodity servers.
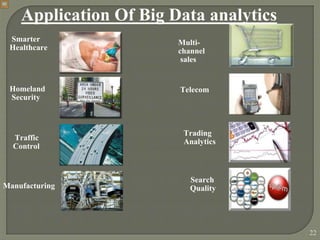
3) Benefits of analyzing big data are outlined, such as gaining insights, competitive advantages and better decision making. Applications of big data analytics are also mentioned in areas like healthcare, security, manufacturing and more.