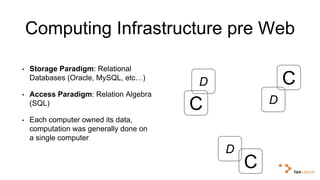
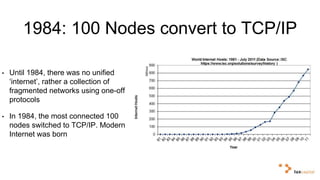
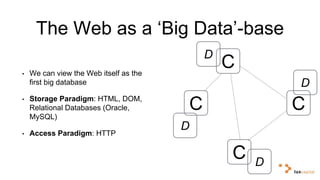
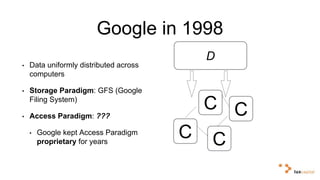
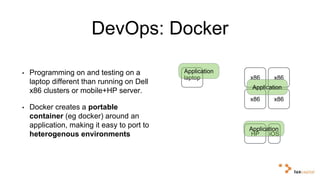
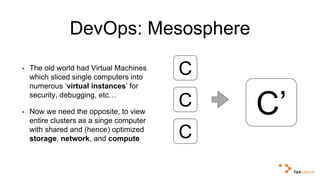
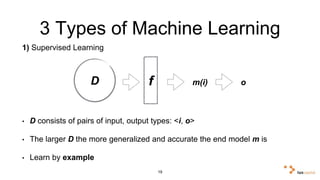
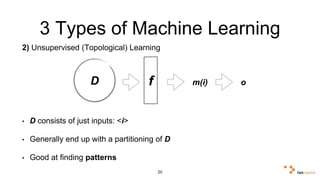
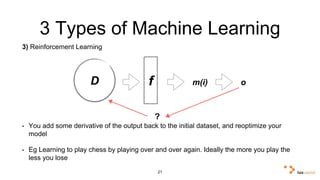
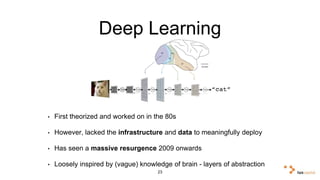
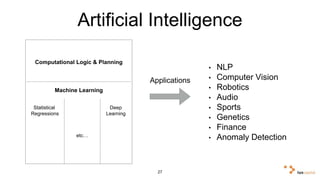
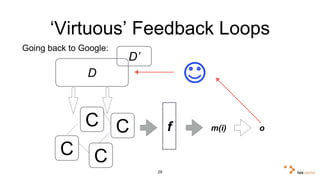
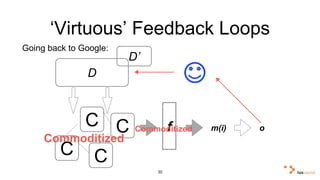
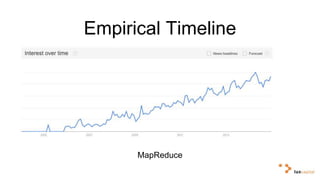
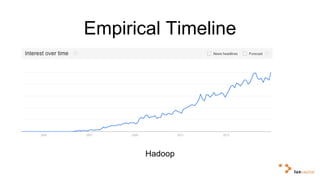
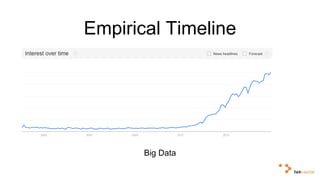
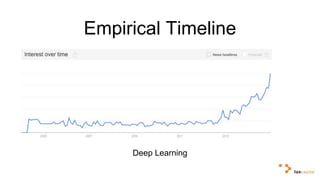
Big data and artificial intelligence have developed through an iterative process where increased data leads to improved infrastructure which then enables the collection of even more data. This virtuous cycle began with the rise of the internet and web data in the 1990s. Modern frameworks like Hadoop and algorithms like MapReduce established the infrastructure needed to analyze large, distributed datasets and fuel machine learning applications. Deep learning techniques are now widely used for tasks involving images, text, video and other complex data types, with many companies seeking to gain advantages by leveraging proprietary datasets.







































































![[DSC Europe 22] On the Aspects of Artificial Intelligence and Robotic Autonom...](https://cdn.slidesharecdn.com/ss_thumbnails/pushandutta-artificialintelligenceinrobotautonomy-221130084927-d0f4c0c6-thumbnail.jpg?width=640&height=640&fit=bounds)



























