


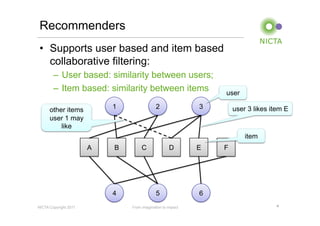


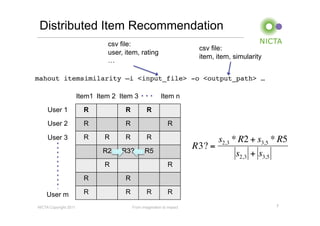




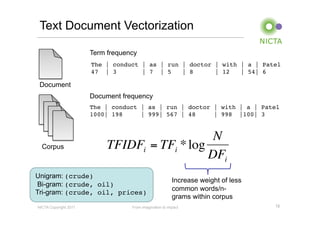





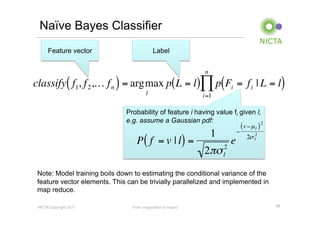




Mahout is a machine learning library that provides implementations of common machine learning algorithms like recommender systems, clustering, and classification. It started as a subproject of Apache Lucene in 2008 and became a top-level Apache project in 2010. Mahout algorithms can run locally or on Hadoop for distributed processing of large datasets. Key areas Mahout supports include recommender systems, clustering algorithms like k-means, and classification using algorithms like naive Bayes.






























![Modul kelompok viii_-_copy_-_copy[1]](https://cdn.slidesharecdn.com/ss_thumbnails/modulkelompokviii-copy-copy1-161201082028-thumbnail.jpg?width=640&height=640&fit=bounds)















































