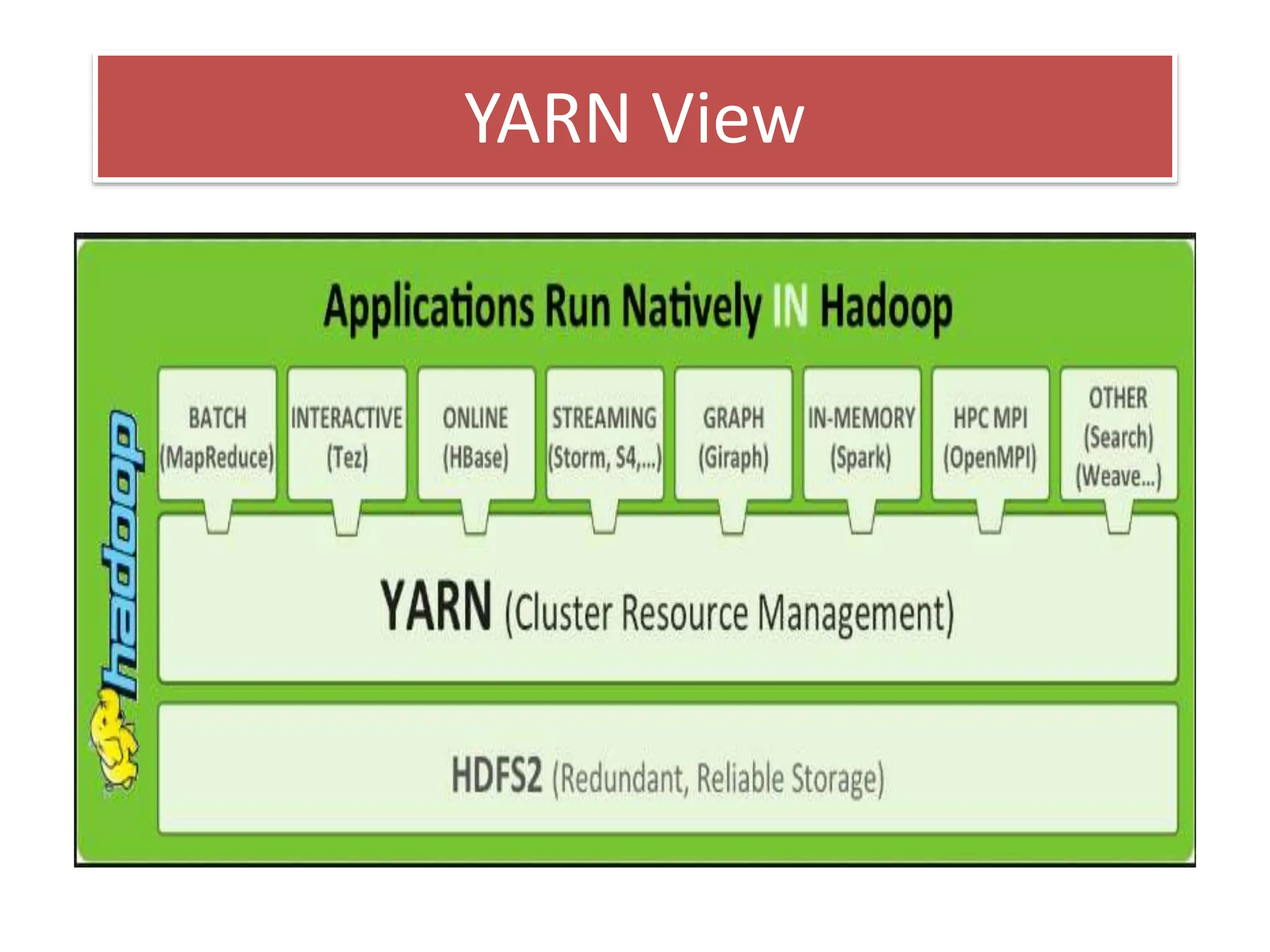
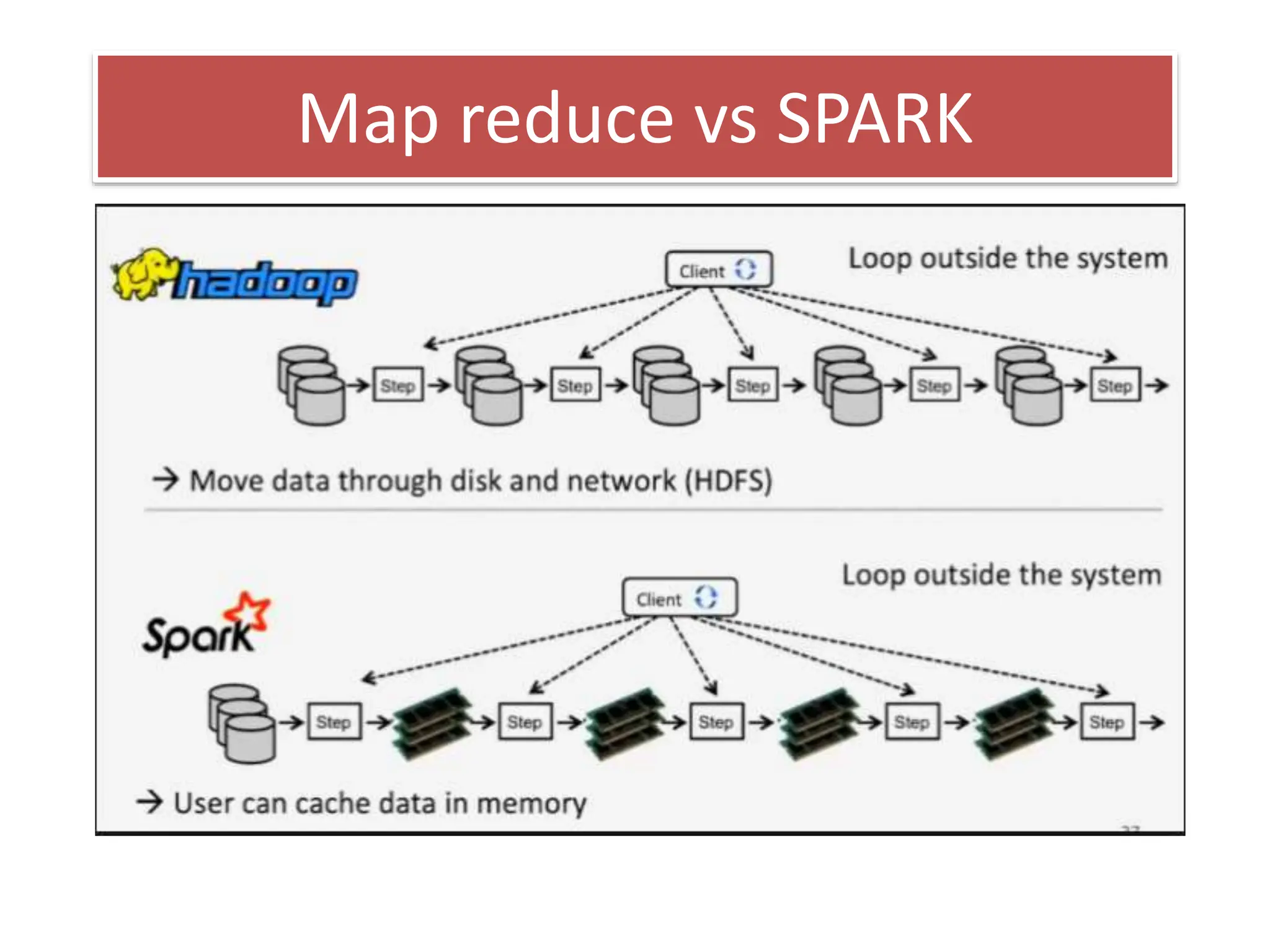
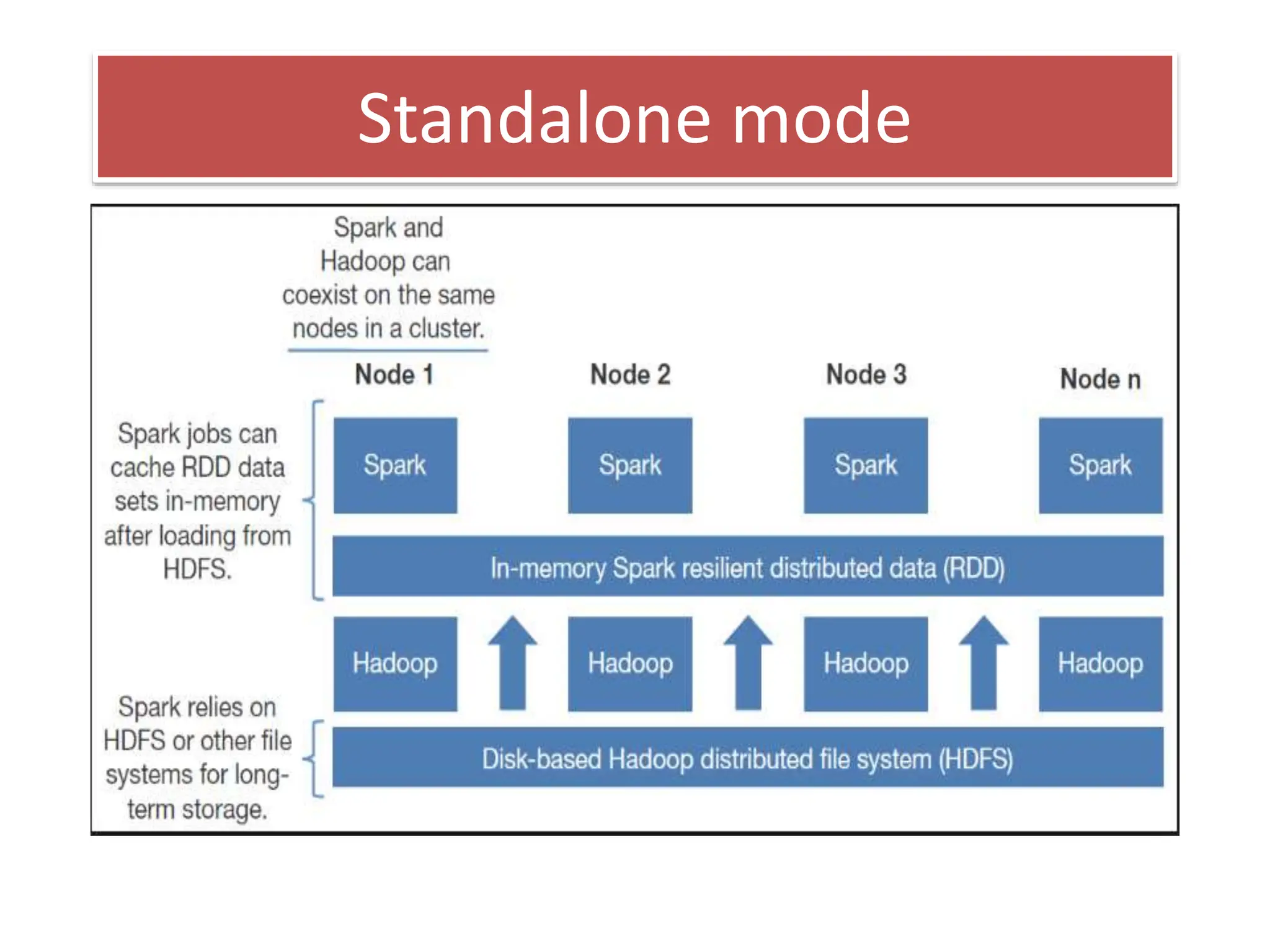
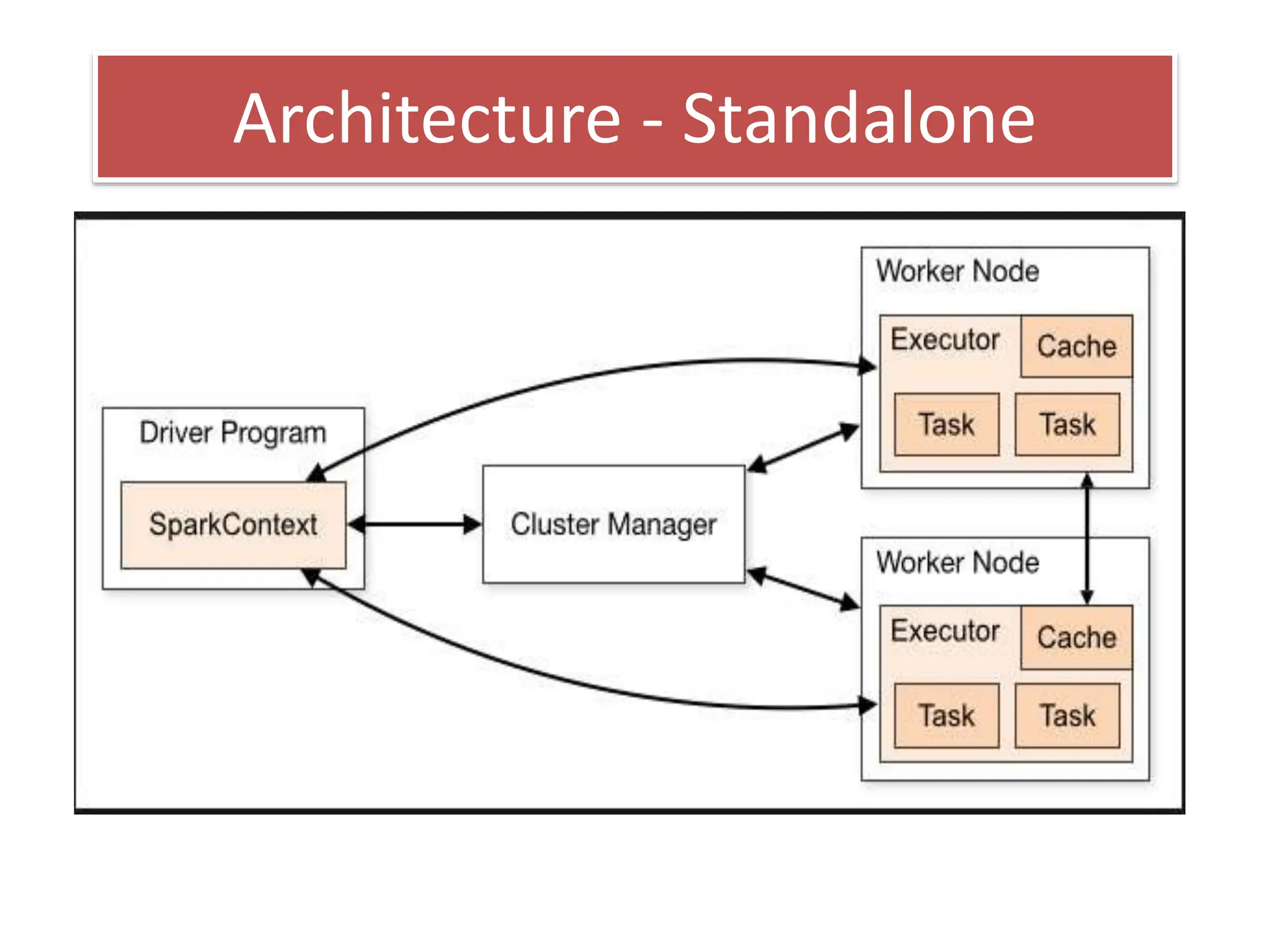
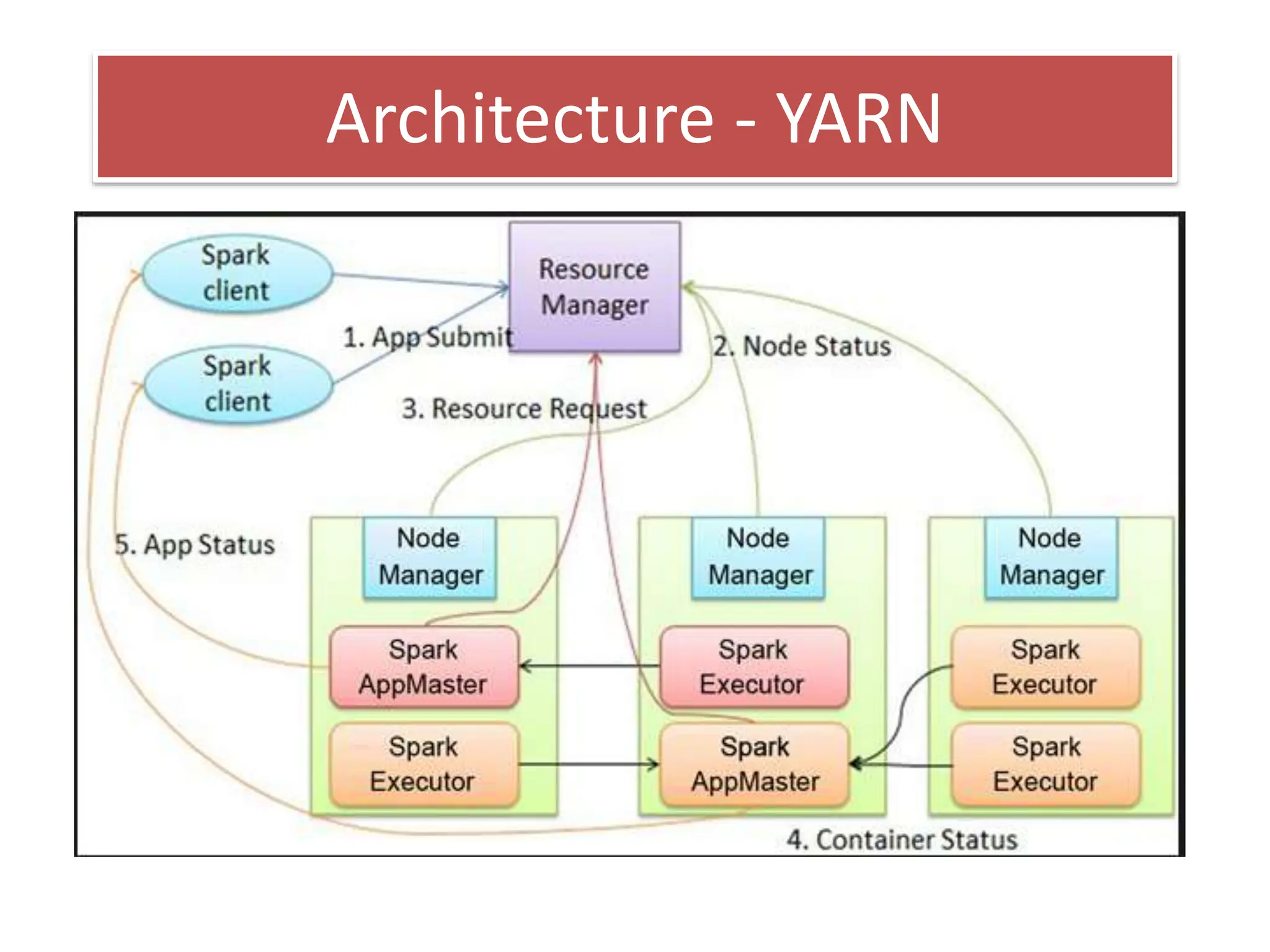
This document discusses Apache Spark, a fast and general engine for large-scale data processing. It provides three key advantages over MapReduce: in-memory processing which is 10-100x faster, support for interactive queries, and integration of streaming, SQL, machine learning, and graph processing. The core abstraction in Spark is the Resilient Distributed Dataset (RDD), which allows data to be partitioned across clusters and cached in memory for faster shared access compared to MapReduce's disk-based approach.


































![[@NaukriEngineering] Apache Spark](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkppt-170105054406-thumbnail.jpg?width=640&height=640&fit=bounds)

















![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jovan Bogicevic - Legacy to AI-Driven Defense: Transforming D...](https://cdn.slidesharecdn.com/ss_thumbnails/rsarluadt563hntyfc8q-3-251211083849-3e7bc4c0-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Marko Krstic - Understanding the AI Threat Landscape - Risks,...](https://cdn.slidesharecdn.com/ss_thumbnails/tiyim1ins5jvbrvzpzla-2-251209104645-c69d3553-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Sara Polak - The Archaeology of Innovation: AI as the Next Cr...](https://cdn.slidesharecdn.com/ss_thumbnails/7ecbscdnt8mlcuqbd2ln-2-sara-polak-ai-creative-industries-251208152533-aa1fcf54-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Dobrica Cosic - Savings by the Second: How Dynamic Pricing an...](https://cdn.slidesharecdn.com/ss_thumbnails/znp09f3smtqz3w2sq6wn-1-dobrica-cosic-savings-by-the-second-how-dynamic-pricing-and-smart-data-are-bu-251208151905-26e6f41e-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Imai Jen-La Plante - The New Generation: AI and the Future of...](https://cdn.slidesharecdn.com/ss_thumbnails/kxi8t2l5rggivgcenyba-1-jenlaplante-dsc-251208152532-d1e076c2-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Aleksandra Dragicevic - AI-Boosted Research in Healthcare: Fr...](https://cdn.slidesharecdn.com/ss_thumbnails/iqwngszurf2r7pi1lnnj-4-aleksandra-dragicevic-ad-dsc-europe-conference-20-251208151905-37c3238a-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Bassam Maharmeh - Artificial Intelligence: Opportunities and ...](https://cdn.slidesharecdn.com/ss_thumbnails/thhfmr2fqpawzj7hsjpg-5-251211083048-2c23204f-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Vladimir Jelic - The AI-Driven Security Shift From Reactive D...](https://cdn.slidesharecdn.com/ss_thumbnails/6g5gj25mtjwayniqem1t-6-251209104645-7a5a5fc6-thumbnail.jpg?width=640&height=640&fit=bounds)