Download as PDF, PPTX























![Vector clocks
* Voldemort
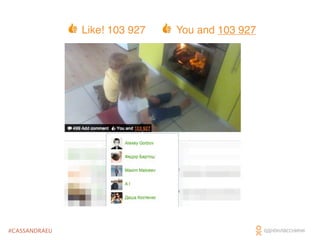
- byte[] key -> byte[] value + VC
- Coordination logic on clients
- Pluggable storage engines
* Plugged
- CS 0.6 SSTables persistance
- Fronted by specialized cache
we love caches
#CASSANDRAEU](https://image.slidesharecdn.com/beingcloserto-cassandrasummiteu-noani-131018025517-phpapp02/85/Being-closer-to-Cassandra-by-Oleg-Anastasyev-Talk-at-Cassandra-Summit-EU-2013-30-320.jpg)

![Why cassandra ?
* Reusable distributed DB components
fast persistance, gossip,
Reliable Async Messaging, Fail detectors,
Topology, Seq scans, ...
* Has structure
beyond byte[] key -> byte[] value
* Delivered promises
* Implemented in Java
#CASSANDRAEU](https://image.slidesharecdn.com/beingcloserto-cassandrasummiteu-noani-131018025517-phpapp02/85/Being-closer-to-Cassandra-by-Oleg-Anastasyev-Talk-at-Cassandra-Summit-EU-2013-32-320.jpg)


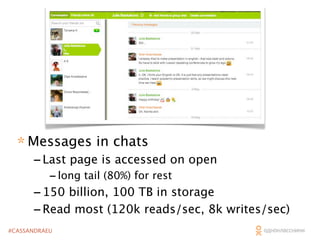
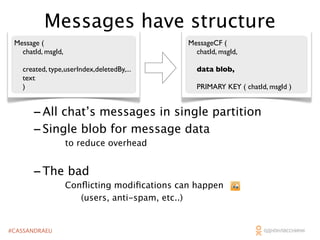
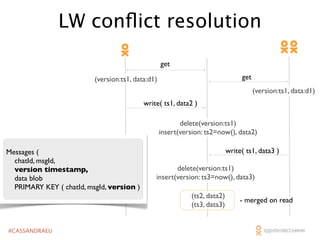
The document outlines the architecture and performance of Odnoklassniki's social network platform, which operates on a massive scale with 40 million daily active users and 80 million monthly active users. It discusses the implementation of Cassandra for handling various data tasks such as likes and messages, highlighting strategies for optimizing reads, writes, and conflict resolution. Key technical details include Cassandra's data structures, read latency management, and the integration of custom caching solutions to enhance performance.















































































