



















![@Netflix Season-2
Cloud Database Engineering
[CDE]](https://image.slidesharecdn.com/netflix-at-disney-09-26-2014-141003123508-phpapp02/85/Netflix-at-disney-09-26-2014-24-320.jpg)













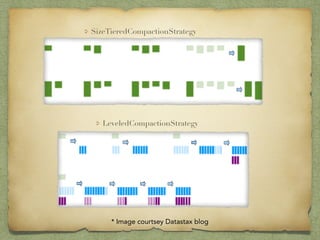











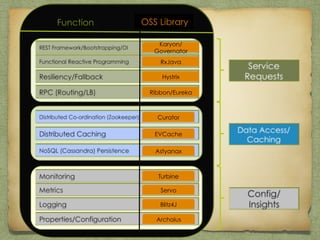
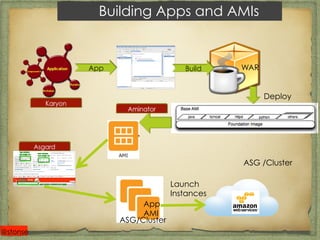
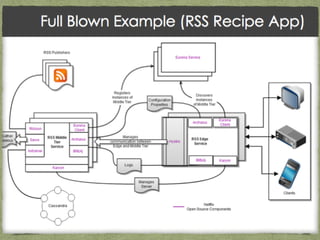
The document covers best practices for cloud data persistence at Netflix, particularly focusing on using Cassandra in a microservices architecture. It discusses architectural challenges, fault tolerance, and the importance of eventual consistency in distributed systems, along with specific Cassandra configurations and operational guidelines. Additionally, it highlights the significance of automation and monitoring in managing large-scale data systems, such as performance metrics and repair strategies.





































































