Downloaded 23 times





















![[local]:5432 ars@ars:5434=# table shardman.partitions;
part_name | node_id | relation
---------------------+---------+------------------
pgbench_accounts_0 | 1 | pgbench_accounts
pgbench_accounts_1 | 2 | pgbench_accounts
pgbench_accounts_2 | 3 | pgbench_accounts
...
Example
30](https://image.slidesharecdn.com/1-171113154405/85/pg-shardman-PostgreSQL-postgres-fdw-pg-pathman-Postgres-Professional-30-320.jpg)
![[local]:5432 ars@ars:5434=# table shardman.replicas;
part_name | node_id | relation
---------------------+---------+------------------
pgbench_accounts_0 | 2 | pgbench_accounts
pgbench_accounts_1 | 3 | pgbench_accounts
pgbench_accounts_2 | 1 | pgbench_accounts
...
Example
31](https://image.slidesharecdn.com/1-171113154405/85/pg-shardman-PostgreSQL-postgres-fdw-pg-pathman-Postgres-Professional-31-320.jpg)



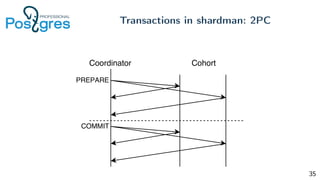

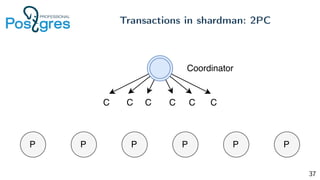
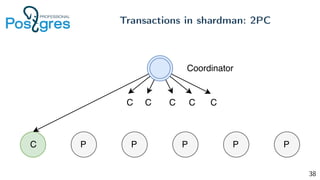
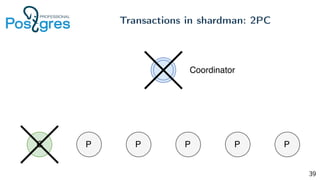


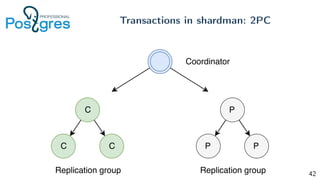


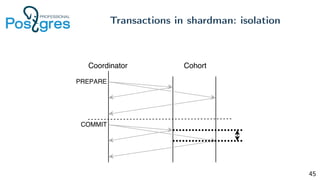


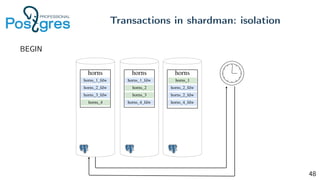
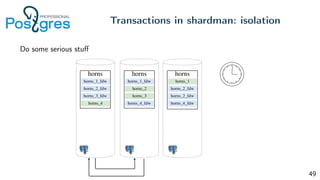
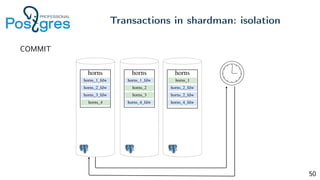
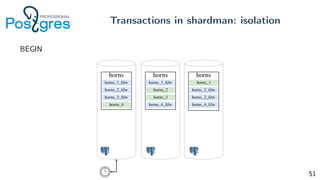
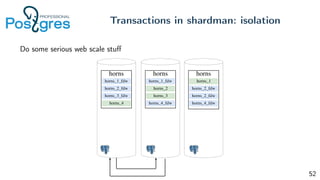



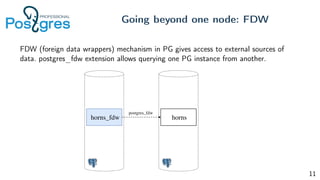
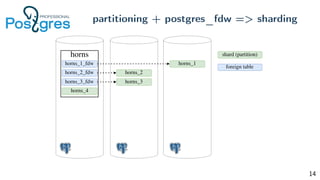
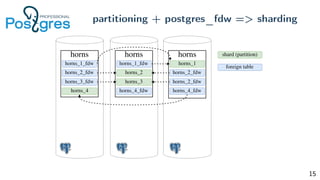
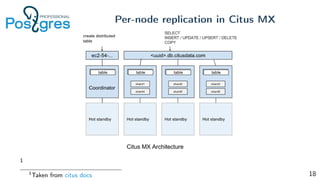
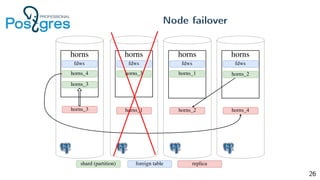
Pg_shardman provides PostgreSQL sharding via partitioning and foreign data wrappers (FDW), with high availability through logical replication and ACID transactions. It aims for horizontal scalability of reads and writes with an OLTP workload. Key features include hash-sharding data across nodes, replication for high availability, and distributed two-phase commit with a distributed snapshot manager to provide transactions across shards. It utilizes partitioning, FDW, and logical replication capabilities in PostgreSQL to provide a sharded cluster with transactions.











![[232] 성능어디까지쥐어짜봤니 송태웅](https://cdn.slidesharecdn.com/ss_thumbnails/232-161025013504-thumbnail.jpg?width=640&height=640&fit=bounds)











































































