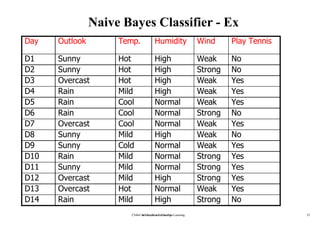
1. Bayesian learning methods are relevant to machine learning for two reasons: they provide practical classification algorithms like naive Bayes, and provide a useful perspective for understanding many learning algorithms.
2. Bayesian learning allows combining observed data with prior knowledge to determine the probability of hypotheses. It provides optimal decision making and can accommodate probabilistic predictions.
3. While Bayesian methods may require estimating probabilities and have high computational costs, they provide a standard for measuring other practical methods.





















![Basic Concepts from Probability Theory
ANormal Distribution (Gaussian Distribution)
is a bell-shaped distribution defined by the
probability density function
• ANormal distribution is fully determined by two parameters in the formula: and .
• If the random variable X follows a normal distribution:
- The probability that X will fall into the interval (a, b) is
- The expected, or mean value of X, E[X] =
- The variance of X, Var(X) = 2
- The standard deviation of X, x =
•The Central Limit Theorem states that the sum of a large number of independent, identically
distributed random variables follows a distribution that is approximately Normal.
Machine Learning 25](https://image.slidesharecdn.com/lec04-bayesianlearning-240108045325-d65c97c6/85/BayesianLearning-in-machine-Learning-12-25-320.jpg)