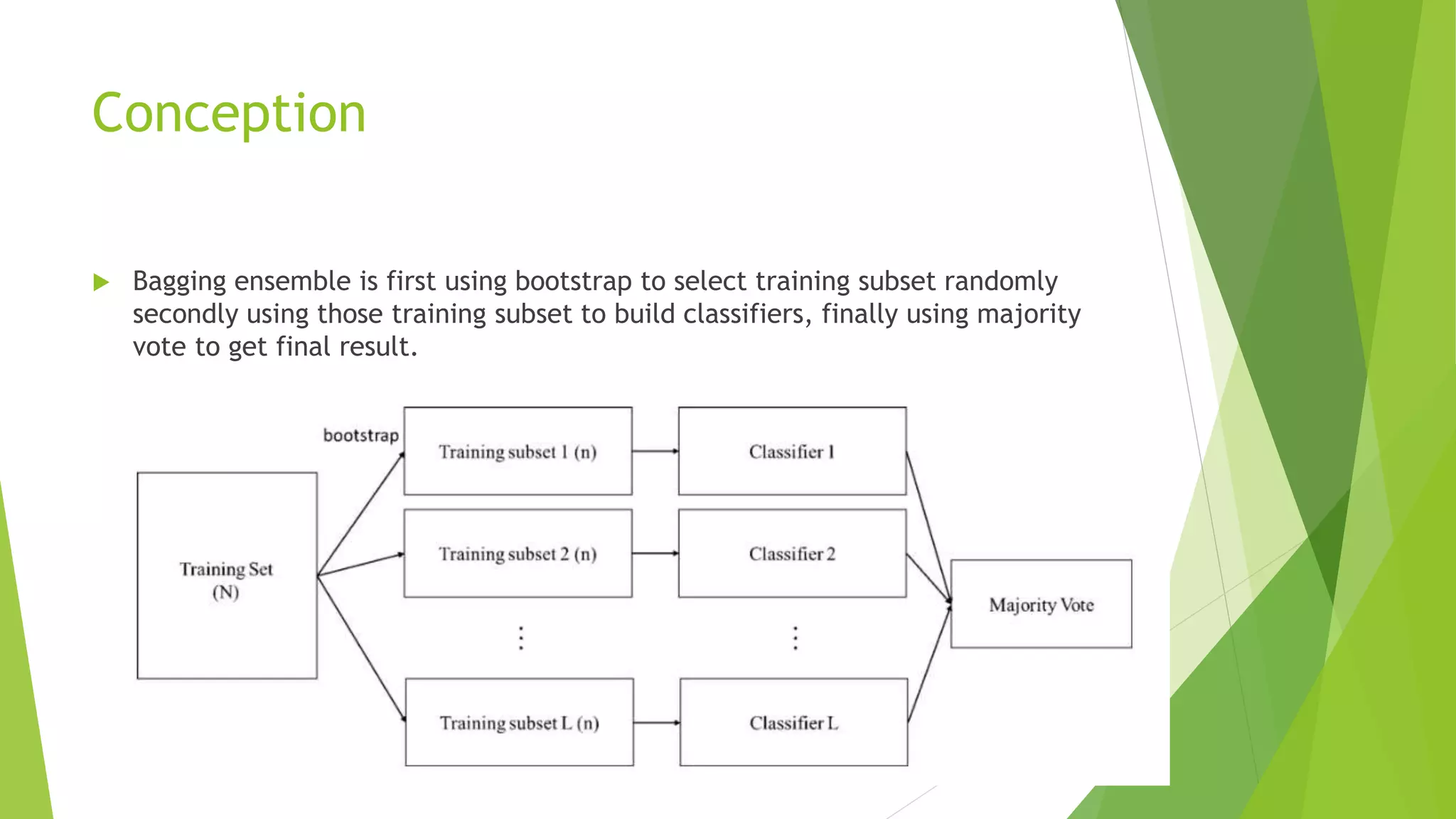
The document discusses bagging ensemble techniques. It explains that bagging aims to reduce variance by training multiple classifiers on randomly sampled subsets of the training data and combining their predictions through majority voting. This technique is effective for models that have high variance and low bias by generating diverse models that stabilize the prediction.