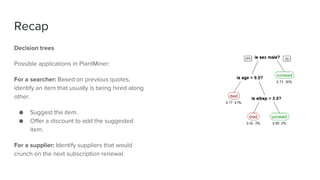
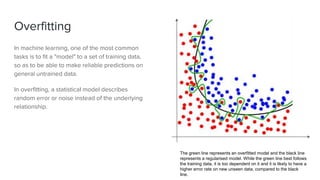
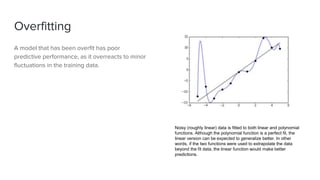
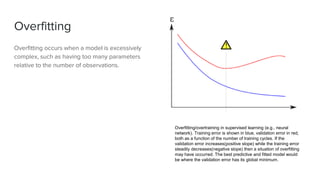
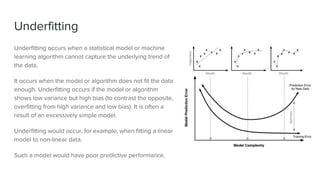
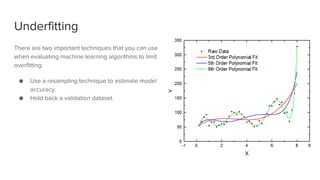
The document discusses key concepts in machine learning, including generalization, overfitting, underfitting, and various algorithms such as Bayesian methods. It highlights techniques for evaluating algorithms, such as k-fold cross-validation and the use of validation datasets. Additionally, it provides insights into real-world applications of machine learning and notable personalities in the field.