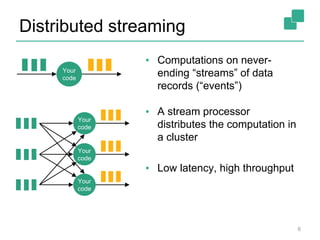
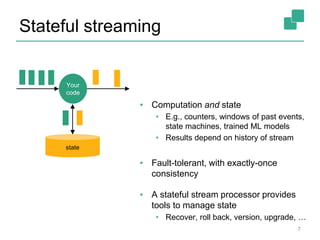
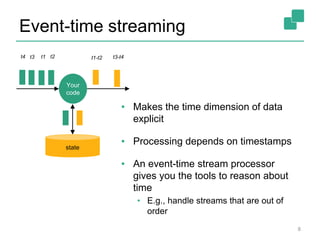
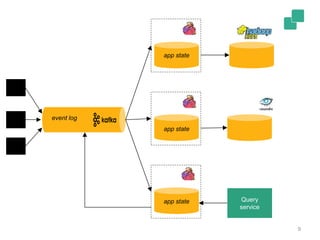
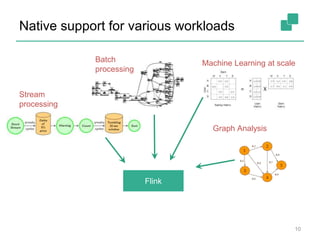
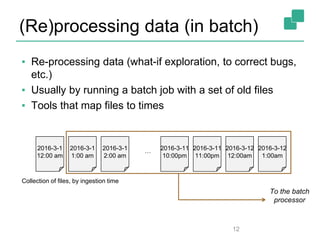
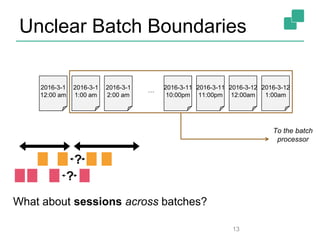
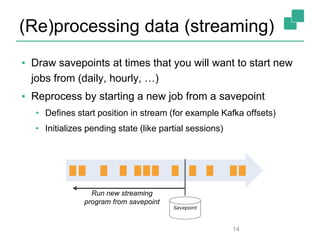
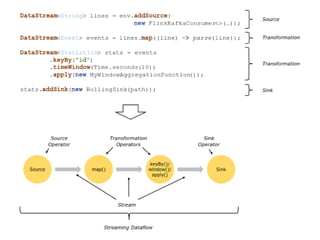
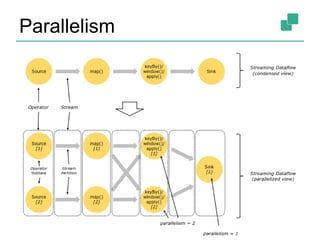
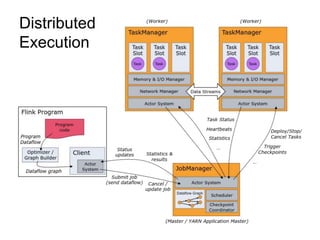
Apache Flink is a stream processing framework that enables real-time data analysis and processing of continuous data streams with low latency and high throughput. It allows for stateful processing and accurate event-time handling, making it suitable for various applications such as real-time business monitoring and data analytics. The framework supports both real-time and historical data processing from a single application, enhancing the robustness of continuous applications.