Download to read offline








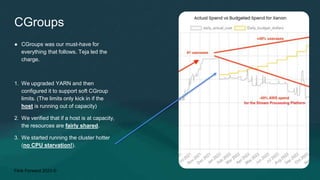

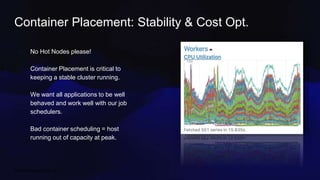
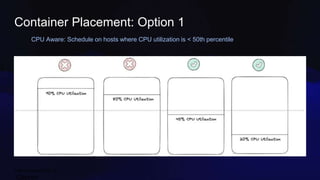



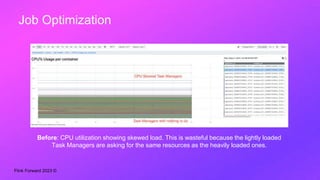
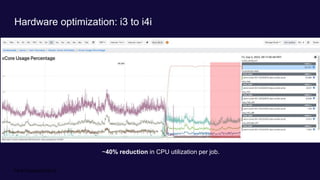

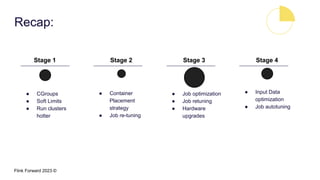
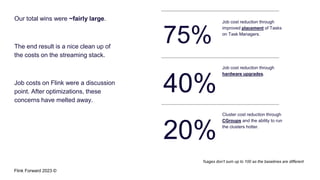



Divye Kapoor discusses how Pinterest tuned their Flink clusters to reduce per-job costs by 50-90%, achieving a typical reduction of around 75%. Key strategies included utilizing cgroups for resource management, optimizing job configurations, improving container placement, and hardware upgrades. The results showed significant cost savings and enhanced cluster stability, allowing Pinterest to absorb increased workloads efficiently.



















































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)
