Download as PDF, PPTX






















![Business Value
29
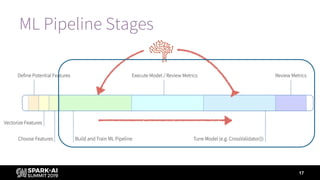
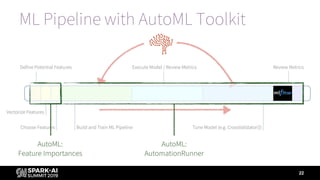
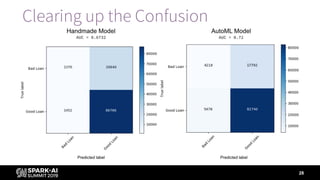
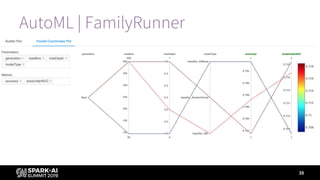
Prediction
Label (Is
Bad Loan)
Short Description Long Description
1 1 Loss Avoided Correctly found bad loans
1 0 Profit Forfeited Incorrectly labeled bad loans
0 1 Loss Still Incurred Incorrectly labeled good loans
0 0 Profit Retained Correctly found good loans
Business value = - (loss avoided – profit forfeited) = -([1, 1] - [1, 0])](https://image.slidesharecdn.com/summiteu19dennyleemarygracemoesta-191202225830/85/Augmenting-Machine-Learning-with-Databricks-Labs-AutoML-Toolkit-29-320.jpg)
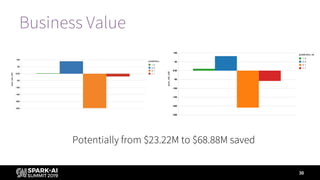









The document outlines a presentation at the Spark + AI Summit discussing the application of Databricks' AutoML toolkit for automating machine learning tasks, particularly hyperparameter optimization and model selection. Speakers Mary Grace Moesta and Denny Lee emphasize the toolkit's capabilities in improving model performance and efficiency, showcased through a case study that resulted in significant cost savings. It also highlights upcoming features in the AutoML roadmap, aimed at enhancing user experience and functionalities.
























![[Warsaw 26.06.2018] SDL Threat Modeling principles](https://cdn.slidesharecdn.com/ss_thumbnails/warsaw26-180628121942-thumbnail.jpg?width=640&height=640&fit=bounds)






























































