Downloaded 11 times






![12
BASE CLASSES
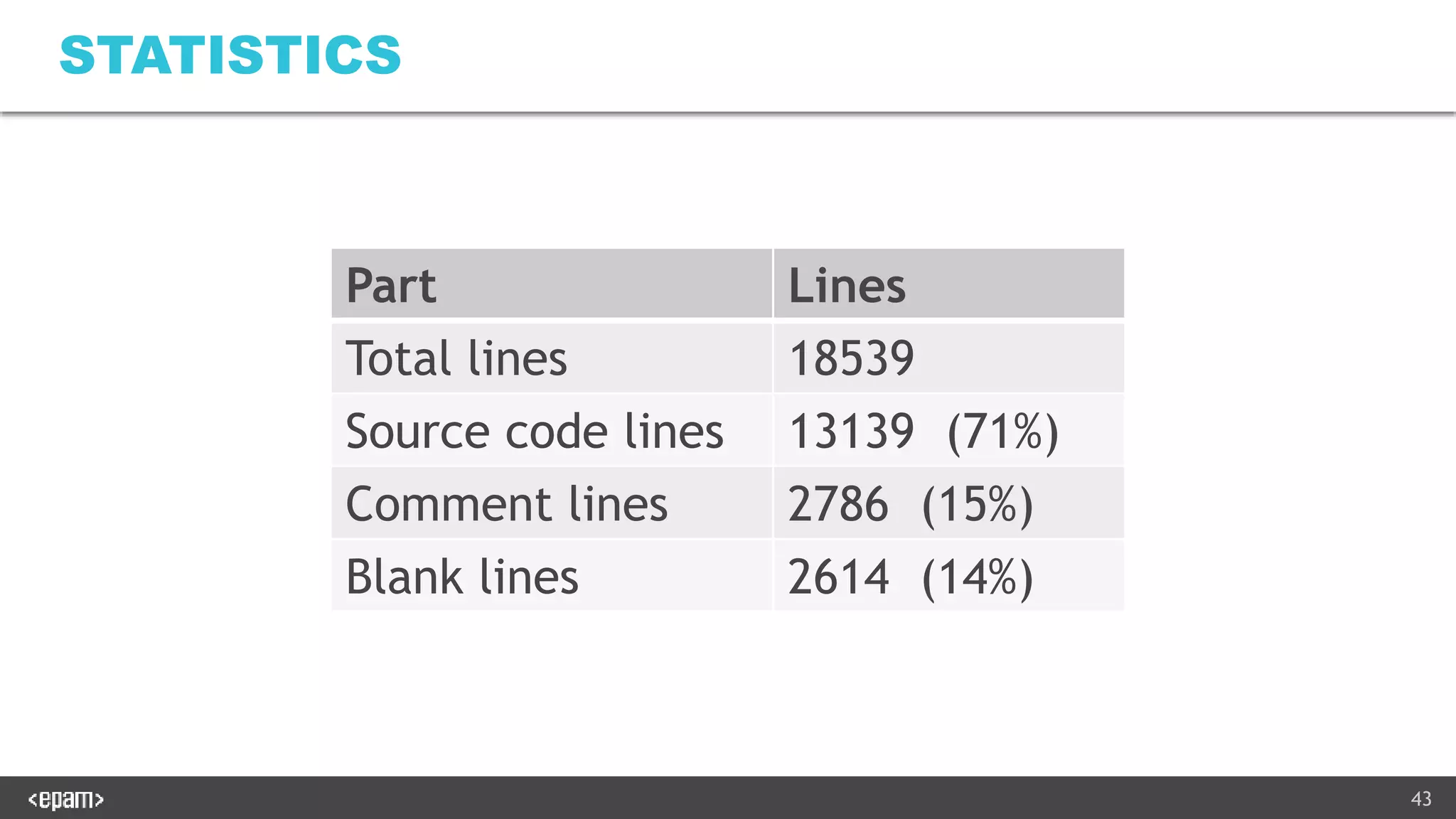
VIN Supplier_ID Repair code ATA cat. ATA subcat Qty
1HGBH41JXM
N109186
123456 REP 74 001003 1
[Same columns] Make Model Fuel Type … Supplier City
[Same columns] BMW X5 petrol … San Francisco
FeatureRecord - container for
features
FeatureRecordGroupedSet –
grouping by any field (in our
case – by order id)
Transformers – enrich FR with features:
• LookupTransformer – adds new columns
• ApplicableTransformer – stops processing
if some field is not in the lookup table
• OilGroupTransformer – groups similar
records
• Etc. (many others exist)
Make_BMW Make_Ford … Quantity … Prediction
1.0 0 … 1 … $55
MultiModel:
vectorizes the feature record and
does prediction](https://image.slidesharecdn.com/productionalizingmlv2-181124214520/75/Productionalizing-ML-Real-Experience-12-2048.jpg)

















![46
RUNNING NOTEBOOKS OFFLINE
How nbrun works:
• Nbformat – https://github.com/jupyter/nbformat
for reading/writing ipynb, inserting/editing cells
• Nbconvert – https://github.com/jupyter/nbconvert
for running the notebook with a specified kernel and getting the output
Applied tricks:
• Override nbconvert.preprocessors.ExecutePreprocessor:
• preprocess_cell: to measure execution time and add
cell.metadata["ExecuteTime"] = {"end_time": time_end, "start_time": time_start}
• run_cell: to log the execution start/end and result just into console output of nbrun.py
• preprocess: to fix the bugs with shutting down the kernel process in the case if we couldn’t
connect to it, to change the timeout for kernel start and to do the “retry” starting if something
failed (what happens quite often with “heavy” kernels like PySpark).](https://image.slidesharecdn.com/productionalizingmlv2-181124214520/75/Productionalizing-ML-Real-Experience-46-2048.jpg)








![56
HIGH LEVEL API
Goals:
• to simplify usage of Sparks dataframes/SQL
• Implicit caching defaults for common operations
• to minimize errors.
Commonly used functions:
• load_df(db_name, table_name, ...), save_df(df, db_name, table_name, ...)
• change_df(a_select_cols, a_drop, a_replace, a_rename, a_add, a_distinct, a_order_by, a_drop_end, a_filter_df,
a_filter_columns, a_filter_not_df, a_filter_not_columns, a_where)
• join_df, group_by
• filter_by_where, filter_by_df, filter_by_not_df, filter_by_threshold, filter_duplicates
Example: new_df = change_df(df, a_add={"new_col": "case when col > 0.0 then 1 else 0 end"})
instead of new_df = df.withColumn("new_col", F.when(df["col"] > 0.0, 1).otherwise(0))](https://image.slidesharecdn.com/productionalizingmlv2-181124214520/75/Productionalizing-ML-Real-Experience-56-2048.jpg)

![58
NOTEBOOK KERNEL PARAMETERS
Marked are those parameters which we strongly advice to apply for a standalone Spark cluster:
{
"display_name": "pyspark cluster - ibobak - 3e 3c",
"language": "python",
"argv": ["/opt/conda/envs/py27/bin/python", "-m", "ipykernel_launcher", "-f", "{connection_file}"],
"env": {
"SPARK_HOME":"/opt/spark",
"PYTHONPATH":"/opt/spark/python/lib/py4j-0.10.4-src.zip:/opt/spark/python",
"PYTHONSTARTUP":"/opt/spark/python/pyspark/shell.py",
"PYSPARK_SUBMIT_ARGS":" --packages com.databricks:spark-avro_2.11:3.2.0
--driver-memory 5G --executor-memory 10G --num-executors 3 --executor-cores 3 --total-executor-cores 9
--master spark://10.4.12.36:7077
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer --conf spark.kryoserializer.buffer.max=1024m
--conf spark.driver.extraJavaOptions="-Xss16m" --conf spark.executor.extraJavaOptions="-Xss16m"
--conf spark.cassandra.output.consistency.level=ALL --conf spark.cassandra.input.consistency.level=ALL pyspark-shell"
}
}
All three params num-executors, executor-cores and total-executor-cores must be specified (otherwise the number of cores
will be unpredictable). Serialization parameters are strongly advices to speed up the dataframe caching. –Xss16m is advices
to avoid stackoverflow errors. Cassandra parameters are needed when you use writes to Cassandra and don’t want a
situation when records are lost after saving and re-loading them.](https://image.slidesharecdn.com/productionalizingmlv2-181124214520/75/Productionalizing-ML-Real-Experience-58-2048.jpg)




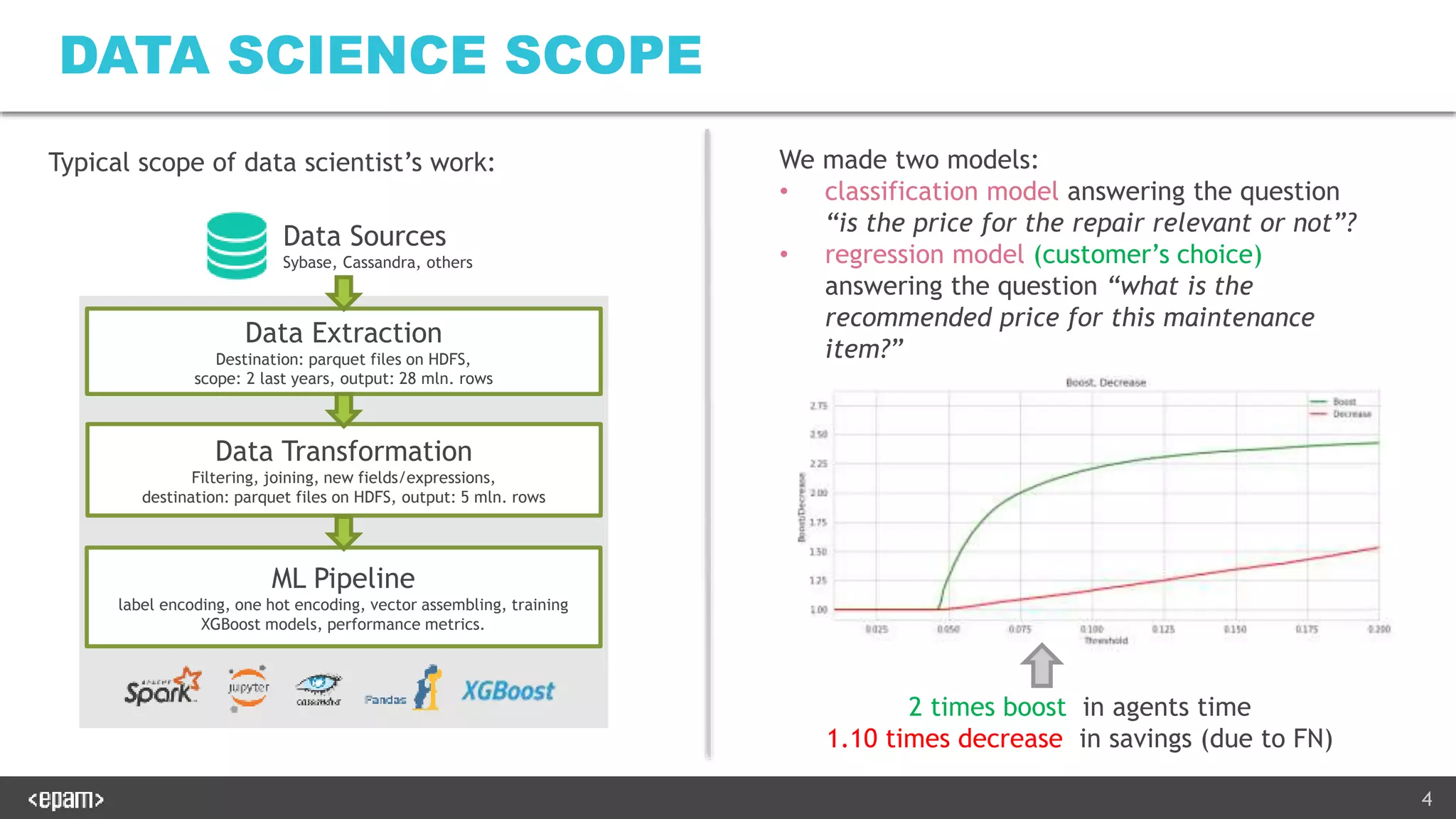
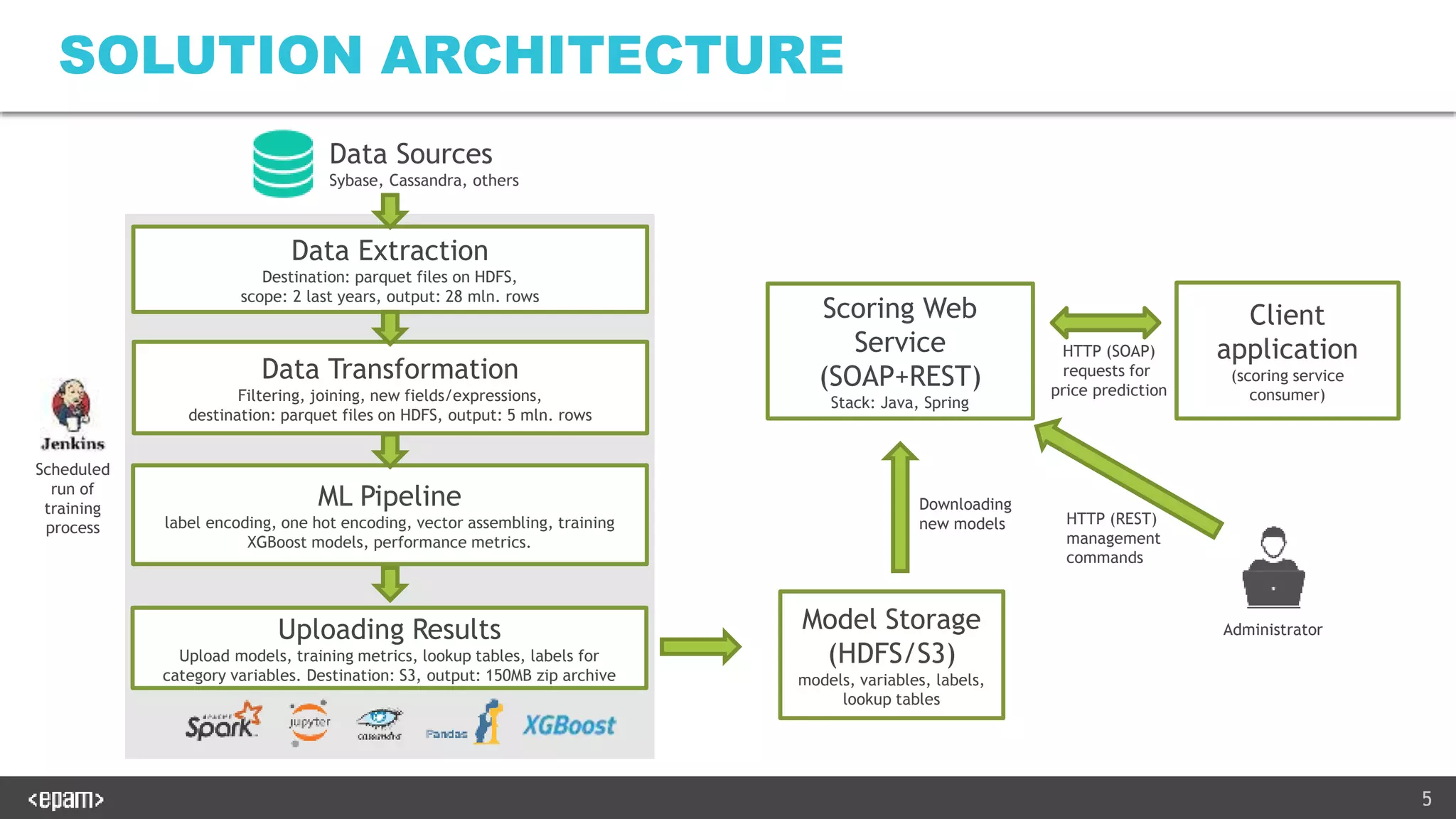
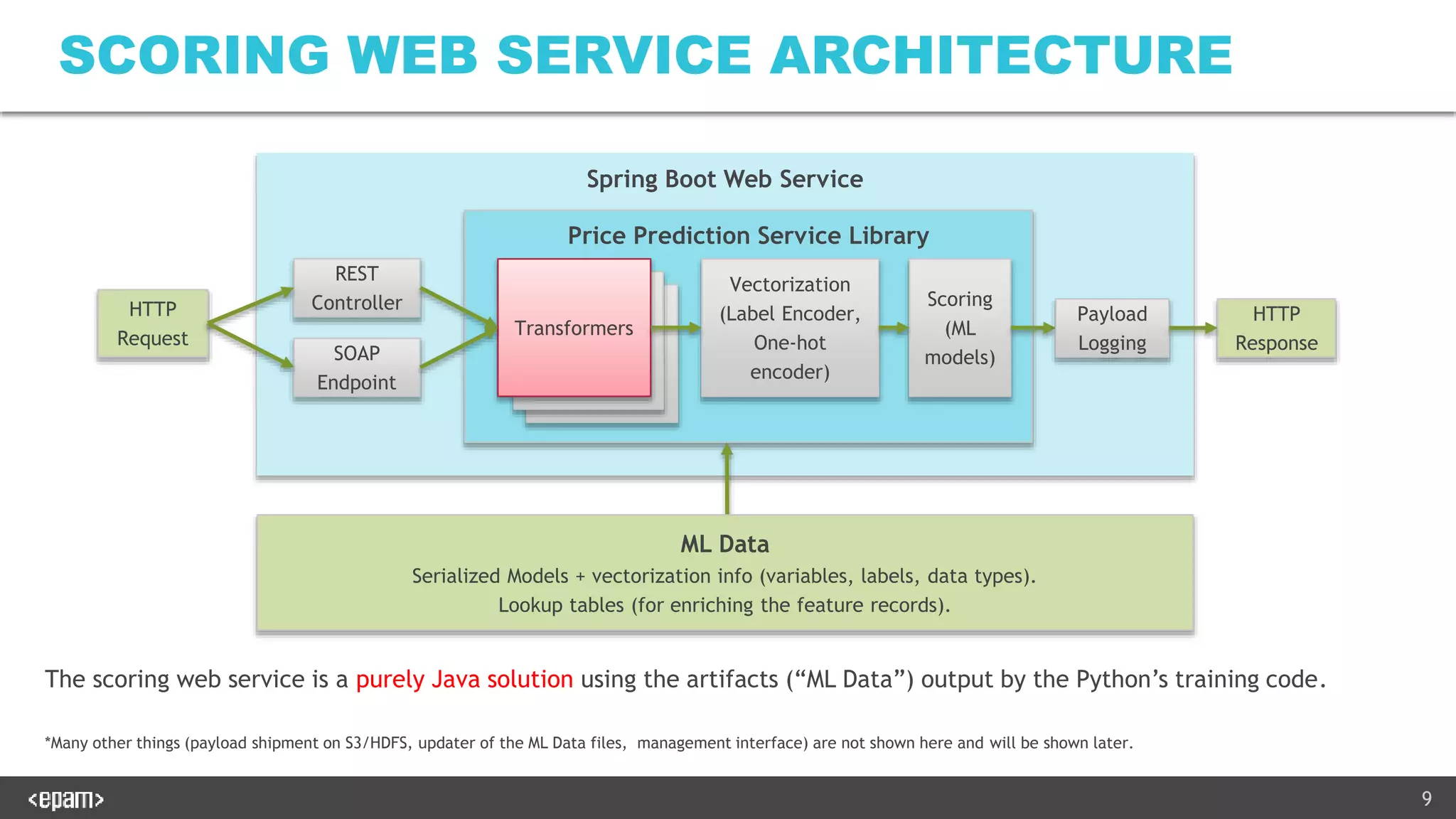
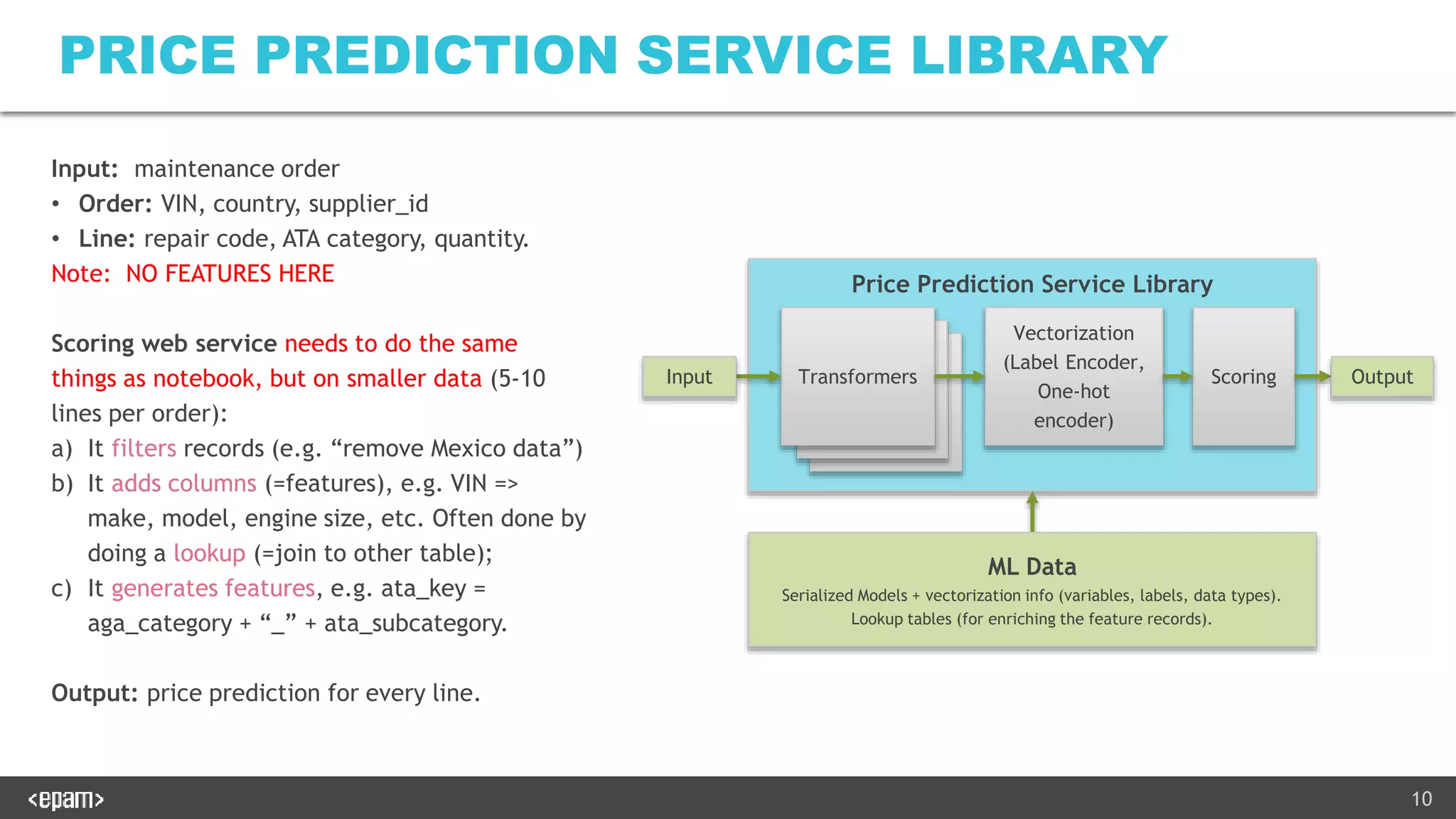
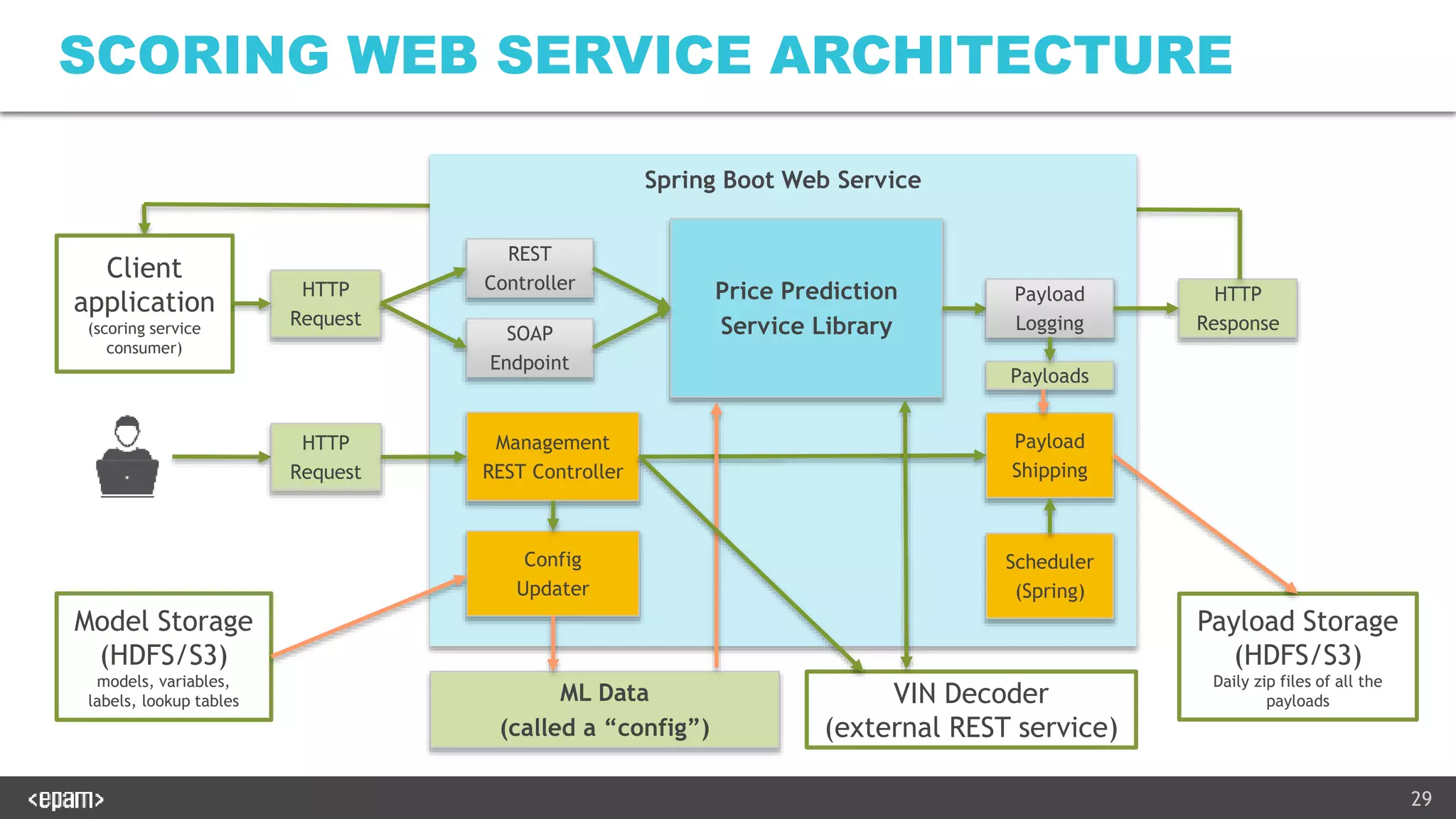
The document describes productionalizing a machine learning model for price prediction that was initially developed using Python notebooks. Key aspects include: 1) The ML pipeline extracts data from various sources, transforms it, trains XGBoost models for price classification and regression, and uploads results to S3. 2) A Java-based web service was developed to serve predictions using the trained models. It performs the same data transformations and vectorization as the notebooks using Java libraries. 3) Extensive unit and integration tests were written to ensure the web service produces identical results to the Python notebooks on both the training and test data. The tests load models and configuration from a zip file produced by the notebooks.









![[AI] ML Operationalization with Microsoft Azure](https://cdn.slidesharecdn.com/ss_thumbnails/wds-mlops-trainer-kyle-akepanidtaworn-v03-190924094657-thumbnail.jpg?width=640&height=640&fit=bounds)































![[DSC Europe 22] Engineers guide for shepherding models in to production - Mar...](https://cdn.slidesharecdn.com/ss_thumbnails/markodimitrijevic-engineersguideforshepherdingmodelsintoproduction2-221130080720-6e979b6f-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jovan Bogicevic - Legacy to AI-Driven Defense: Transforming D...](https://cdn.slidesharecdn.com/ss_thumbnails/rsarluadt563hntyfc8q-3-251211083849-3e7bc4c0-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Dobrica Cosic - Savings by the Second: How Dynamic Pricing an...](https://cdn.slidesharecdn.com/ss_thumbnails/znp09f3smtqz3w2sq6wn-1-dobrica-cosic-savings-by-the-second-how-dynamic-pricing-and-smart-data-are-bu-251208151905-26e6f41e-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Bassam Maharmeh - Artificial Intelligence: Opportunities and ...](https://cdn.slidesharecdn.com/ss_thumbnails/thhfmr2fqpawzj7hsjpg-5-251211083048-2c23204f-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Urosevic -Rethinking Financial Talent: Integrating Cod...](https://cdn.slidesharecdn.com/ss_thumbnails/8jjrus8ttko6qj64f58f-3-251212103250-642c6374-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Aleksandra Dragicevic - AI-Boosted Research in Healthcare: Fr...](https://cdn.slidesharecdn.com/ss_thumbnails/iqwngszurf2r7pi1lnnj-4-aleksandra-dragicevic-ad-dsc-europe-conference-20-251208151905-37c3238a-thumbnail.jpg?width=640&height=640&fit=bounds)




