Downloaded 10 times






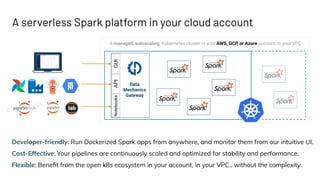
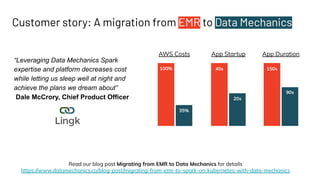


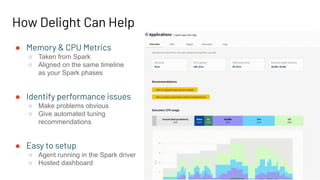
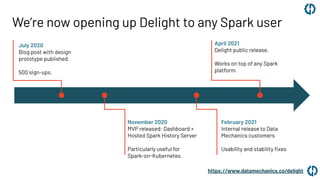

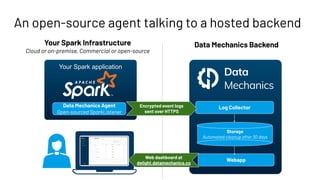



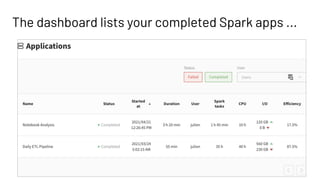
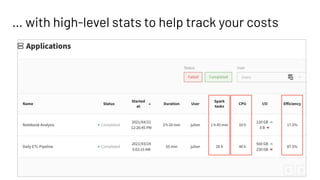

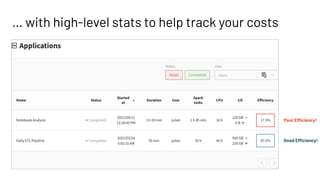



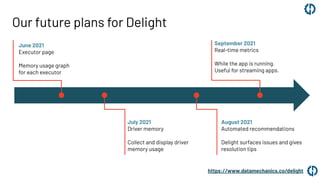



This document introduces Delight, an improved Apache Spark UI created by Data Mechanics. Delight provides high-level visualizations of Spark jobs to help users identify inefficiencies and reduce costs. It collects metrics during and after jobs to show CPU usage, task duration, and efficiency. Delight is open source and works on any Spark platform by installing an agent. Data Mechanics aims to further enhance Delight with real-time metrics, driver memory collection, and automated recommendations.














































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)
![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)







