Download as PDF, PPTX






![4 - Provide visibility to the end-users
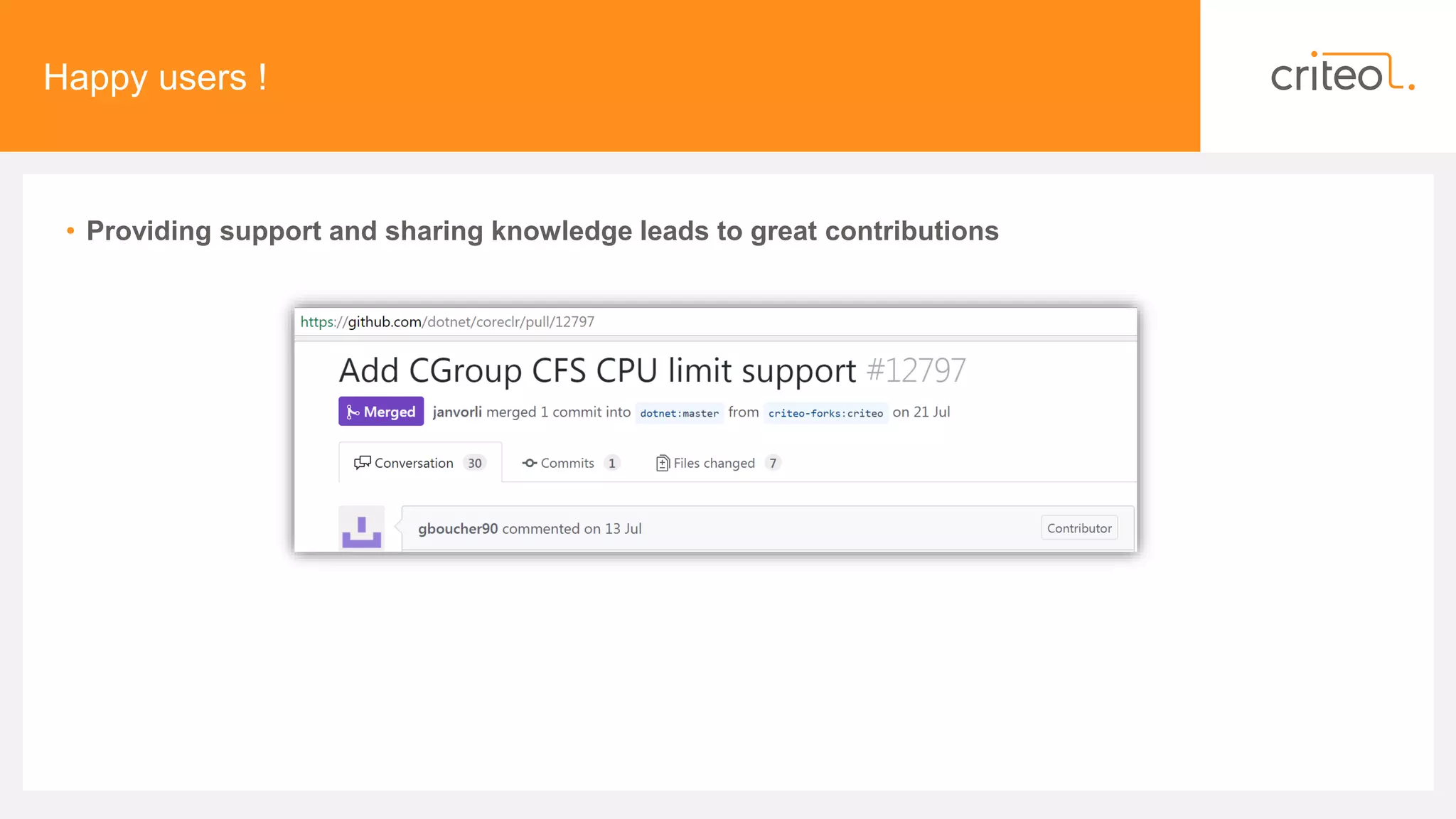
• Cultural changes
• App instances move continuously !
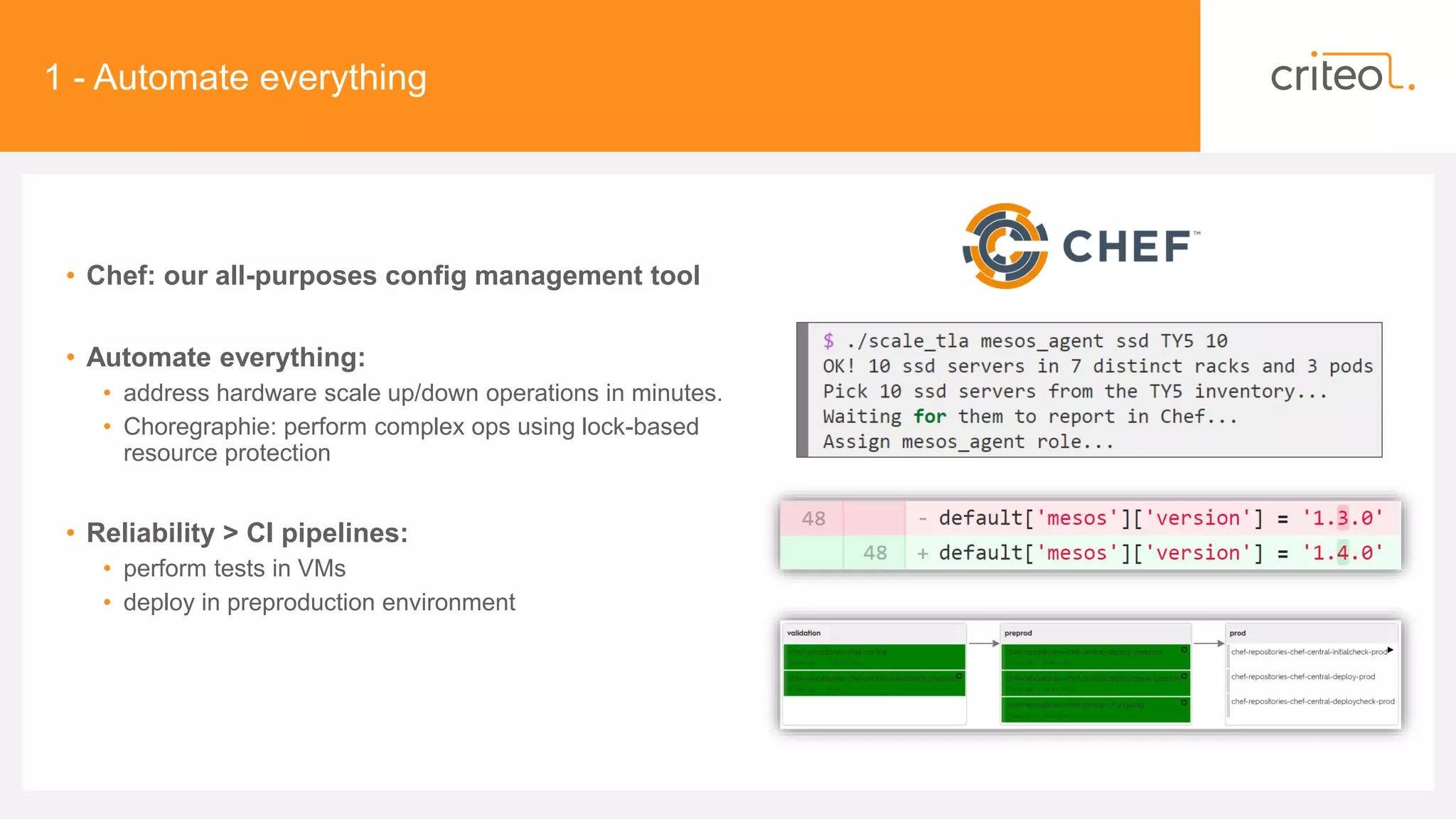
• Metrology & Alerting
• Collectd, prometheus_exporter, etc.
• Not well-known metrics, from mesos.proto :
• Networking: net_[rx|tx|tcp]*,
[TrafficControl|Ip|Tcp|Udp]Statistics,
• Disk I/O: CgroupInfo.Blkio.CFQ.Statistics
• Tracing: PerfStatistics (costly!)
• SLAs
• Transparency about platform footprint
• Report your ability to schedule – chaos monkey involved !
• Debugging / Tracing
• The Mesos I/O Switchboard: remotely attach/exec
• Introducing system tracing components such as LTTng](https://image.slidesharecdn.com/mesosconeu2017-criteo-operatingmesos-basedinfrastructures-171027065635/75/MesosCon-EU-2017-Criteo-Operating-Mesos-based-Infrastructures-10-2048.jpg)




The document discusses insights on operating a large-scale infrastructure powered by Mesos at Criteo, detailing the company's growth, operational strategies, and system architecture. Key topics include the transition to commodity hardware, the implementation of automation tools like Chef, service discovery methods, and challenges related to networking and resource management. The presentation also highlights the importance of security, reliability, and user visibility in maintaining a production-grade environment.





















































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)













