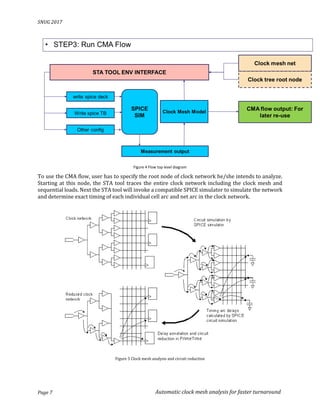
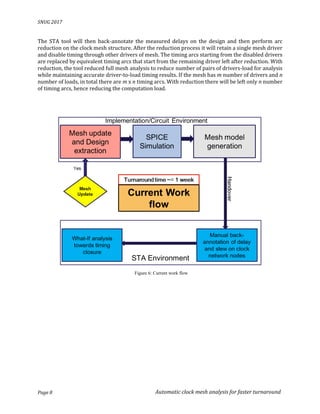
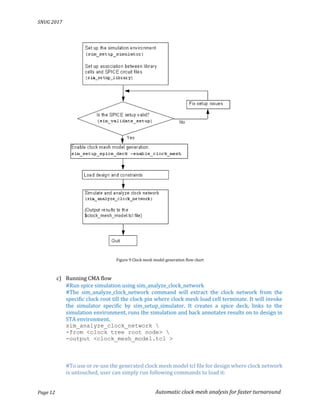
This document describes an automated clock mesh analysis (CMA) flow that uses SPICE simulation within a static timing analysis (STA) tool to model clock mesh networks. The CMA flow extracts the clock mesh network, runs SPICE simulation on it, and back-annotates delays and slews to the STA tool. This allows clock meshes to be analyzed faster and more accurately compared to traditional manual SPICE simulations or STA tools alone. Experimental results show the CMA flow matches an internal simulator to within 1.365% for cell delays and transitions, while reducing analysis time from a week to less than an hour.









![SNUG 2017
Page 11 Automatic clock mesh analysis for faster turnaround
-simulator_type <simulation tool>
-work_dir <simulation directory path>
-preserve <all|fail|none>
#OUTPUT SNIPPET
#Setup mapping of transistor models to gate level models
sim_setup_library
-lib <path to gate level library>
-sub_circuit <Dir path that contains cell sub-circuit file>
-header <path to header files which includes simulation
settings such as model file, corner instantiation and
simulation options>
-file_name_pattern <pattern for input files>
#OUTPUT SNIPPET
#Specify setup option to enable SPICE simulation
sim_setup_spice_deck –enable_clock_mesh
#Test your setup: To validate your SPICE setup is correct, run following commands:-
sim_validate_setup
-from A -to Y
-lib_cell [get_lib_cells $lib_name/<CELL_NAME>]
-capacitance <cap_value> -transition_time <transition_time>](https://image.slidesharecdn.com/automatedclockmeshanalysisforfasteturnaroundver5-180622101756/85/Automated-clock-mesh-analysis-for-faster-turnaround-11-320.jpg)

![SNUG 2017
Page 16 Automatic clock mesh analysis for faster turnaround
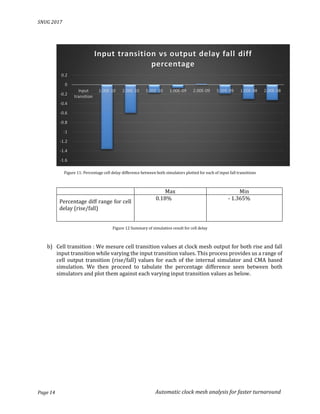
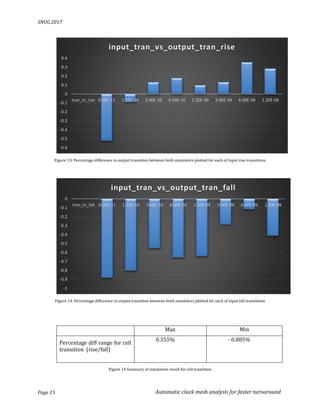
With above data we can conclude between earlier and current approach simulation accuracy for
both cell delay and cell transition is varying by a maximum of 1.365% , which is an acceptable
variation considering this also accounts for differences in spice models and simulators itself.
Analysis runtime
Between earlier and current approach for the testcase, we see a significant improvement in runtime
as below.
Previous approach of CM
analysis
CMA flow based approach
Total analysis time 1 Week 1 hour
Figure 15 : Analysis runtime comparison
5. Conclusions
The implemented flow offers following advantages:-
a) Scalabile yet accurate: The CMA flow is an independent and closed loop flow, hence even
for smallest ECOs there’s no dependency on other teams for collaterals and multiple handoffs.
This methodology can be extended to any number of modes/corners. Though the flow has
some level of limited accuracy , it has been found to be of good enough quality as required for
signoff.
b) Faster turn-around: As compared to existing approach which may take almost a week to
generate the required data to be back-annotated to STA environment, the CMA flow can do it
in few hours, enabling faster design convergence.
CMA Accuracy tradeoff:-
As described earlier, the native STA tool favors clock mesh optimization to reduce clock drivers, this
is to ensure the flow offer faster execution with nominal accuracy loss. This allows more iterations of
ECOs to back annotation within STA tool environment itself. In our analysis we have found the
accuracy level
Hence with above listed advantages of scalability, flexibility and faster turn-around time we were
able to achieve faster and quality design convergence while reducing the resource requirement for
the same task. Moreover the nominal accuracy levels were found to be good enough quality as
required for signoff.
6. References
[1] H. Chen, C. Yeh,G. Wilke, sliding window scheme for accurate clock mesh analysis, ACM library
[2] Pinaki Chakarbarti, Vikram Bhatt, Dwight Hill, Aiqun Cao, Clock mesh framework, ISQED 2012
[3] Malik Devulpalli, Yuichi Kawahara, Clock mesh Variation robustness : Benefit and analysis, Design and
reuse, https://www.design-reuse.com/articles/21019/clock-mesh-benefits-analysis.html
[4] Solvent article: Improved SPICE Correlation Flow.](https://image.slidesharecdn.com/automatedclockmeshanalysisforfasteturnaroundver5-180622101756/85/Automated-clock-mesh-analysis-for-faster-turnaround-16-320.jpg)







































![[Back2School] STA Basic Concepts- Chapter 1.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/stabasicconcepts-250524204554-25ac4895-thumbnail.jpg?width=640&height=640&fit=bounds)




![[Back2School] STA Methodology- Chapter 7pdf](https://cdn.slidesharecdn.com/ss_thumbnails/stamethodology-250624214856-5fd24ebc-thumbnail.jpg?width=640&height=640&fit=bounds)



















