Downloaded 19 times


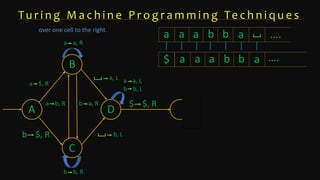






The document discusses Turing machine programming techniques, particularly methods for recognizing the left end of the tape and building Turing machines for specific languages like 0n 1n 0n. It describes the use of special symbols to facilitate string comparison and the possibility of non-destructive replacements to preserve original strings. Key examples are given, illustrating how to create larger machines by combining simpler ones.



































































