Get To The Point: Summarization with Pointer-Generator Networks_acl17_論文紹介
Neural Text Summarizationタスクの研究論文.ACL'17- long paper採択.スタンフォード大のD.Manning-labの博士学生とGoogle Brainの共同研究.長文データ(multi-sentences)に対して、生成時のrepetitionを回避するような仕組みをモデルに導入し、長文の要約生成を可能とした.ゼミでの論文紹介資料.論文URL : https://arxiv.org/abs/1704.04368
Get To The Point: Summarization with Pointer-Generator Networks_acl17_論文紹介
1.
2017.06.26
NAIST ⾃自然⾔言語処理理学研究室
D1 Masayoshi Kondo
論論⽂文紹介-‐‑‒ About Neural Summarization@2017
Get To The Point : Summarization with
Pointer-‐‑‒Generator Networks
ACLʼ’17
Abigail See
Stanford University
Peter J. Liu
Google Brain
Christopher D. Manning
Stanford University
00: Introduction
とはいえ・・・
Abstractive Summarization の課題は多い
• Undesireble behavior such as inaccurately reproducing factual details.
• An inability to deal with out-‐‑‒of-‐‑‒vocabulary (OOV)
• Repeating themselves
Short Text
(1 or 2 sentences)
Long Text
(more than 3 sentences)
Single Document Headline Generation 本研究の対象
Multi Documents (Opinion Mining)
Document
Summary length
⽂文書要約タスクのタイプ
本研究(本論論⽂文)では、
• Long-‐‑‒text summarization をタスクとして、
• 上記の課題 に対応するような、
• 新しいニューラルネットモデル を提案する.
00: Introduction
Attention
Encoder (Bi-‐‑‒LSTM)Decoder (RNN)
Input-‐‑‒Sequence
Attention
Distribution
Predicted Vocab
Distribution
Context Vector
pgen
Final Predicted Vocab
Distribution
1 -‐‑‒ pgen
pgen
Context Vector
12.
00: Introduction
Attention
Encoder (Bi-‐‑‒LSTM)Decoder (RNN)
Input-‐‑‒Sequence
Attention
Distribution
Predicted Vocab
Distribution
Context Vector
pgen
Final Predicted Vocab
Distribution
1 -‐‑‒ pgen
pgen⼊入⼒力力系列列(src)
側の単語を
使い回す
気持ち
新しい表現を
⽣生み出す気持ち
Context Vector
13.
1. Introduction
2. Our Models
3. Related Work
4. Dataset
5. Experiments
6. Results
7. Discussion
8. Conclusion
14.
00: Our Models
2.1 Sequence-‐‑‒to-‐‑‒Sequence attention model
[Encoder] [Decoder]
…
i+1
i
… …
ei
t
= vT
⋅ tanh Whh +Wss( )
at
= soft max(et
)
ht
∗
= ai
t
hi
i
∑
$
%
&
&
'
&
&
Encoder hidden state :
Decoder hidden state : s
h
Context vector : h∗
詳しく知るには:
Neural machine translation by jointly learning to align and translate
[Bahdanau, ICLRʼ’15]
Abstractive text summarization using sequence-‐‑‒to-‐‑‒sequence RNN and beyond
[R.Nallapati et al, CoNLLʼ’16]
15.
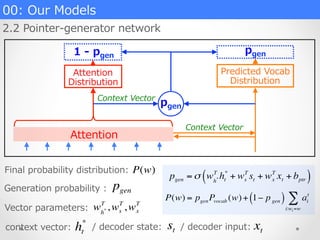
00: Our Models
2.2 Pointer-‐‑‒generator network
Attention
Attention
Distribution
Predicted Vocab
Distribution
Context Vector
pgen
1 -‐‑‒ pgen
pgen
Context Vector
pgen = σ wh*
T
ht
*
+ ws
T
st + wx
T
xt + bptr( )
P(w) = pgenPvocab (w)+ 1− pgen( ) ai
t
i:wi=w
∑
Final probability distribution: P(w)
context vector:
wh*
T
,ws
T
,wx
T
Generation probability : pgen
ht
*
/ decoder state: st / decoder input: xt
Vector parameters:
16.
00: Our Models
2.3 Coverage mechanism
Coverage Vector : ct Attention
Distribution
sum
Decoder
Timestep
1
2
3
t-‐‑‒1
t
…
…
ct
Coverage
Vector
Dec側の過去の⼊入⼒力力に
対するattention vector
を⾜足し合わせる.
ct
= at'
t'=0
t−1
∑
ct is a (unnormalized)
distribution over the source
document words.
…
17.
00: Our Models
2.3 Coverage mechanism
ei
t
= vT
⋅ tanh Whh +Wss +Wcct
+ battn( )
covlosst
通常のアテンション計算式に
Coverage Vectorの項を追加
Coverage Loss :
covlosst = min(ai
t
,ci
t
)
i
∑
losst = −log(wt
*
)+ λ min(ai
t
,ci
t
)
i
∑
Attentionの計算 :
Dec側のステップt番⽬目の単語に対する、
Enc側のi番⽬目のattention値と
coverage (vectorの要素i)値を⽐比較し
て、⼩小さい⽅方を加算対象とする.
【解釈】:Dec側のステップt毎に毎回Enc側i番⽬目の単語が使われる状況を想定する.このとき、ci
tは、tに
従って増加して⾏行行き(蓄積される)、ステップtが進むにつれてai
tはci
tの値を超えにくなる(cが1を超えた場
合は、以後, aがcovlossへの加算対象となる.)この時、min(a)となると、backprop時にDec側ステップtの
単語をEnc側i番⽬目の単語の性質から引っ張ってくることを強く抑制するように最適化がなされる.⼀一⽅方で、
min(c)となった場合は、Dec側の全てのtに対してEnc側i番⽬目の単語の性質の利利⽤用を抑制するように最適化が
なされる.したがって、全体としてEnc側同⼀一単語の利利⽤用を抑制しつつ、Dec時の局所的に⾼高い確率率率で単語を
繰り返すような場合もmin(a)によって抑制できる.→ Dec側tの同単語の繰返し⽣生成を抑制.
18.
1. Introduction
2. Our Models
3. Related Work
4. Dataset
5. Experiments
6. Results
7. Discussion
8. Conclusion
論論⽂文内容にあまり影響
しないので、割愛
19.
1. Introduction
2. Our Models
3. Related Work
4. Dataset
5. Experiments
6. Results
7. Discussion
8. Conclusion
20.
00: Dataset
CNN/Daily Mail Dataset : Online news articles
Source (article) Target (summary)
avg Sentence : -‐‑‒
Word : 781 (tokens)
vocab 150k size
avg Sentence : 3.75
Word : 56 (tokens)
vocab 60k size
Settings
• Used scripts by Nallapati et al (2016) for pre-‐‑‒processing.
• Used the original text (non-‐‑‒anonymized version of the data).
Train set Validation set Test set
287,226 13,368 11,496
Dataset size
21.
1. Introduction
2. Our Models
3. Related Work
4. Dataset
5. Experiments
6. Results
7. Discussion
8. Conclusion
lead-‐‑‒3(冒頭⽂文抜出) > 抽出要約⽅方式 > ⽣生成要約⽅方式
【ここまでのまとめ】:ROUGEスコアを評価指標とする要約タスクは、
00: Discussion
7.1 Comparison with extractive systems
ROUGEスコアは、元記事の冒頭⽂文章を利利⽤用したり元記事の表現を使い回す
といった安直な戦略略に対して良良い評価を⾏行行う.
これが、抽出要約⽅方式が⽣生成要約⽅方式よりもROUGEスコアが⾼高く、
抽出要約⽅方式ですら、ベースライン:lead-‐‑‒3(冒頭3⽂文抜出)に勝て
ない理理由である.
30.
METEORスコア
00: Discussion
7.1 Comparison with extractive systems
前述の課題に対応するために、METEORスコアによる評価を⾏行行なった.
予測⽂文と正解⽂文の単語⼀一致だけでなく、(事前に辞書が必要ではあるが)
語幹、同義語や⾔言い換えにも良良い評価を与える.
• 提案法が、他の⽣生成要約モデルに⽐比べて1ポイント以上優位結果を⽰示した.
• ⼀一⽅方で、lead-‐‑‒3には負けている.これは、ニュース記事の形式がlead-‐‑‒3を
評価指標に対して⾮非常に強くさせているのだろう.
31.
00: Discussion
7.1 Comparison with extractive systems
We believe that investigating this issue further is an
important direction for future work.
7.2 How abstractive is our model ?
We have show that our pointer mechanism makes
our abstractive system more reliable, copying factual
details correctly more often. But, does the ease of
copying make our system any less abstractive ?
• ⽣生成要約タスクにおいて、現⾏行行の評価指標には限界がある.
• pointer mechanismは、詳細な事実を正しくコピーでき、確かに提案
法をより良良いものとした.
• だが、コピーの容易易さはむしろ我々のモデルから⽣生成要約らしさを減ら
してしまっているのではないか?
32.
00: Discussion
7.2 How abstractive is our model ?
⽣生成された要約⽂文に対するsrc側に含まれる表現のn-‐‑‒gram毎の含有率率率
33.
Fig.7 ) 図の2つのArticleは、どち
らも要約時には「X beat Y
<score> on <day>」のような典
型的な⽂文章になる例例.
00: Discussion
7.2 How abstractive is our model ?
Fig.5 ) 提案⼿手法による⽣生成要約例例.
典型的な要約⽂文ではなく、新しい語
を使って要約⽂文を⽣生成している.
34.
00: Discussion
7.2 How abstractive is our model ?
• Train 時 : 0.30 → 0.53 (train終了了時)
• Test 時 : avg-‐‑‒0.17
pgen は、提案⼿手法における⽣生成要約らしさの尺度度.
モデルは、最初src側のコピーを多く⾏行行なうが、半時間程で⽣生成すること
を学習.
35.
1. Introduction
2. Our Models
3. Related Work
4. Dataset
5. Experiments
6. Results
7. Discussion
8. Conclusion













![00: Our Models
2.1 Sequence-‐‑‒to-‐‑‒Sequence attention model
[Encoder] [Decoder]
…
i+1
i
… …
ei
t
= vT
⋅ tanh Whh +Wss( )
at
= soft max(et
)
ht
∗
= ai
t
hi
i
∑
$
%
&
&
'
&
&
Encoder hidden state :
Decoder hidden state : s
h
Context vector : h∗
詳しく知るには:
Neural machine translation by jointly learning to align and translate
[Bahdanau, ICLRʼ’15]
Abstractive text summarization using sequence-‐‑‒to-‐‑‒sequence RNN and beyond
[R.Nallapati et al, CoNLLʼ’16]](https://image.slidesharecdn.com/gettothepointacl17-170626100452/85/Get-To-The-Point-Summarization-with-Pointer-Generator-Networks_acl17_-14-320.jpg)










































![[DL輪読会]Convolutional Sequence to Sequence Learning](https://cdn.slidesharecdn.com/ss_thumbnails/dl0519-170519005603-thumbnail.jpg?width=640&height=640&fit=bounds)













![[DL輪読会]Abstractive Summarization of Reddit Posts with Multi-level Memory Netw...](https://cdn.slidesharecdn.com/ss_thumbnails/abstractivesummarizationofredditpostswithmulti-levelmemorynetworks-190219034601-thumbnail.jpg?width=640&height=640&fit=bounds)

![[PaperReading]Unsupervised Discrete Sentence Representation Learning for Inte...](https://cdn.slidesharecdn.com/ss_thumbnails/paperreading-20180702shinoda-180702111612-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DLHacks]Topic‑Aware Neu ral KeyphraseGenerationforSocial Media Language](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackstakgfinal-190820070754-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Pervasive Attention: 2D Convolutional Neural Networks for Sequence-to-...](https://cdn.slidesharecdn.com/ss_thumbnails/20180907pervasiveattention2dconvolutionalneuralnetworksforsequence-to-sequenceprediction-180907000649-thumbnail.jpg?width=640&height=640&fit=bounds)
![Graph-to-Sequence Learning using Gated Graph Neural Networks. [ACL'18] 論文紹介](https://cdn.slidesharecdn.com/ss_thumbnails/graph2sequencelearningusinggatedgraphneuralnetworkacl18-190507010338-thumbnail.jpg?width=640&height=640&fit=bounds)







