Download to read offline




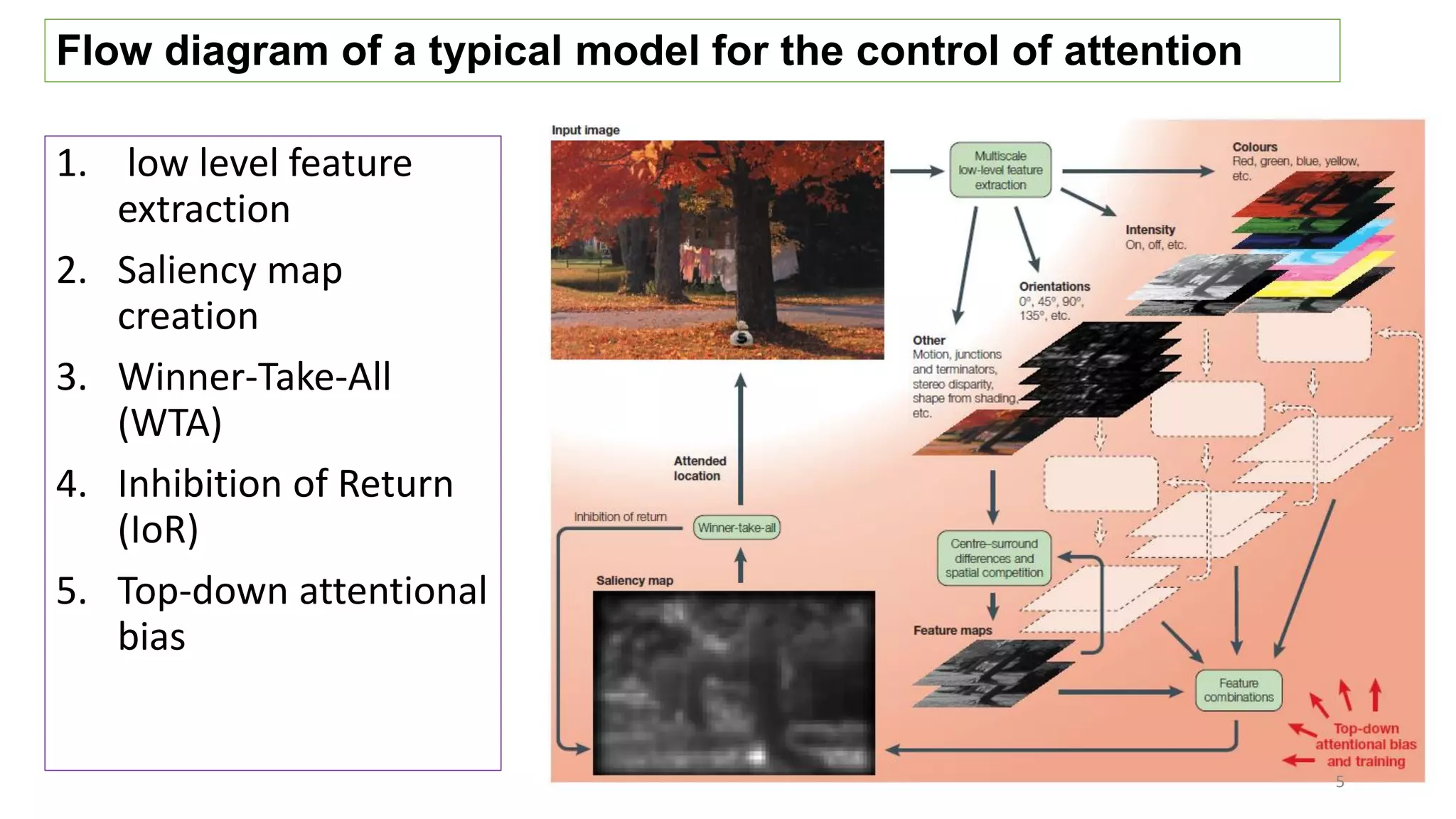
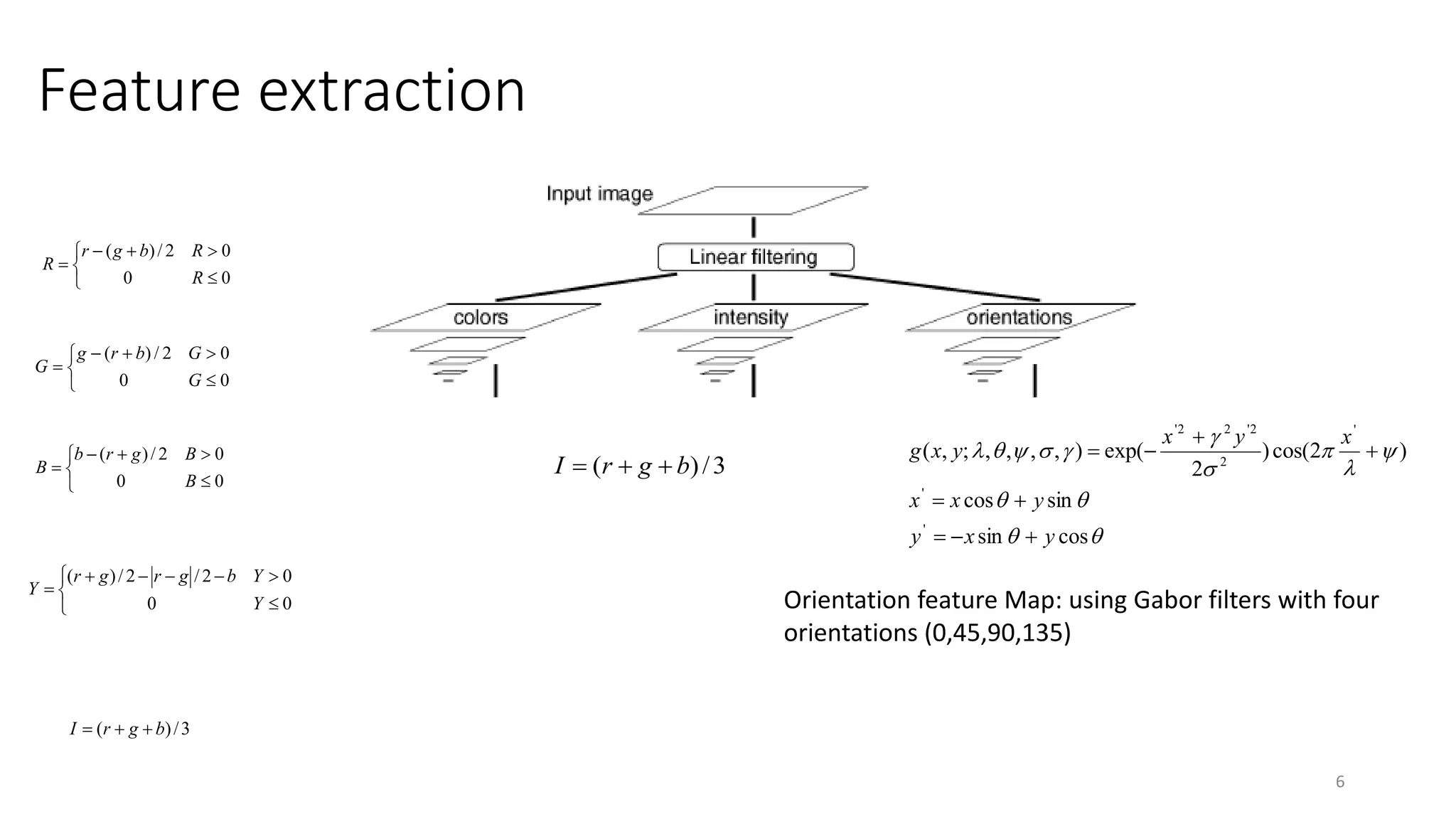




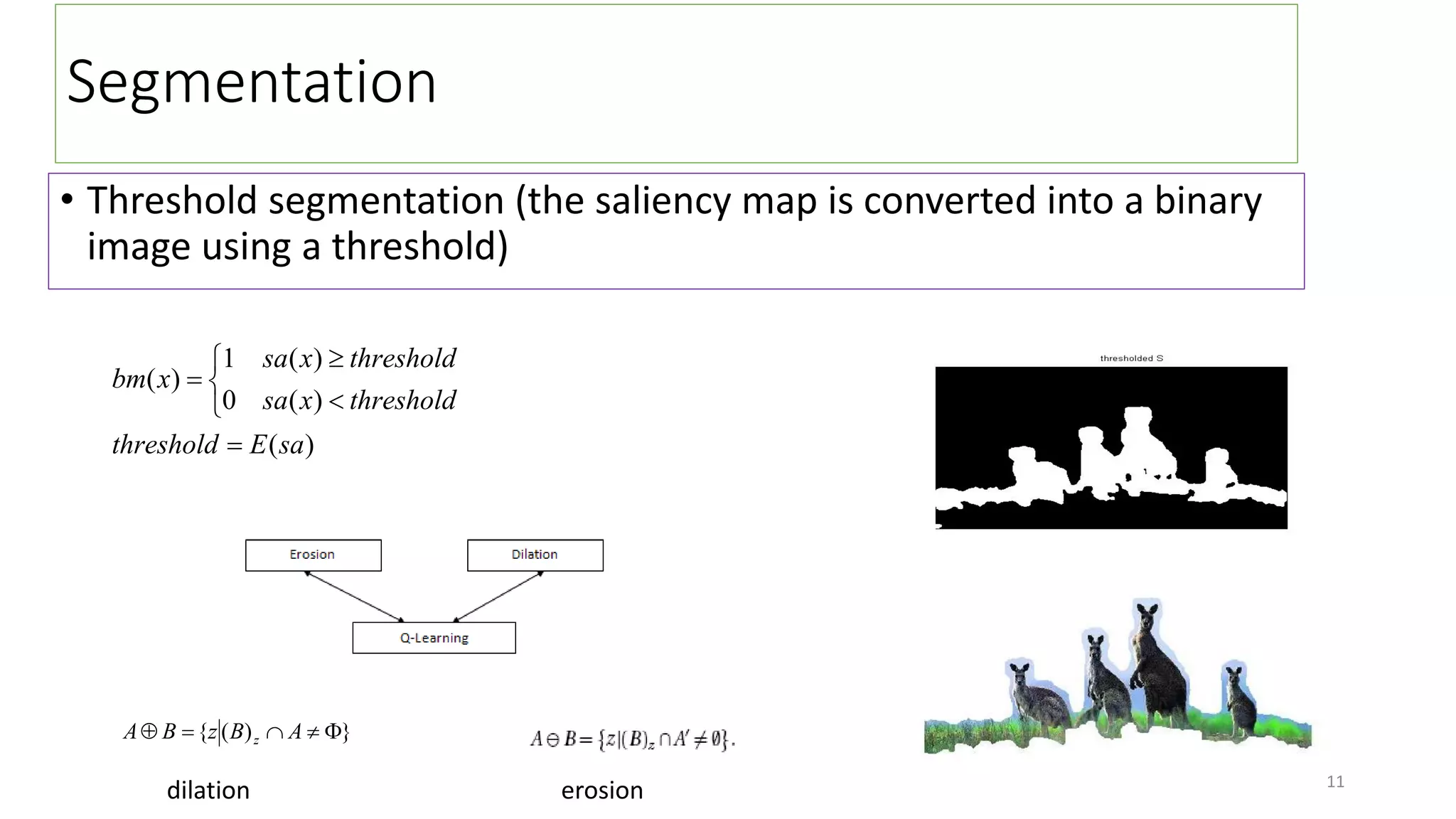
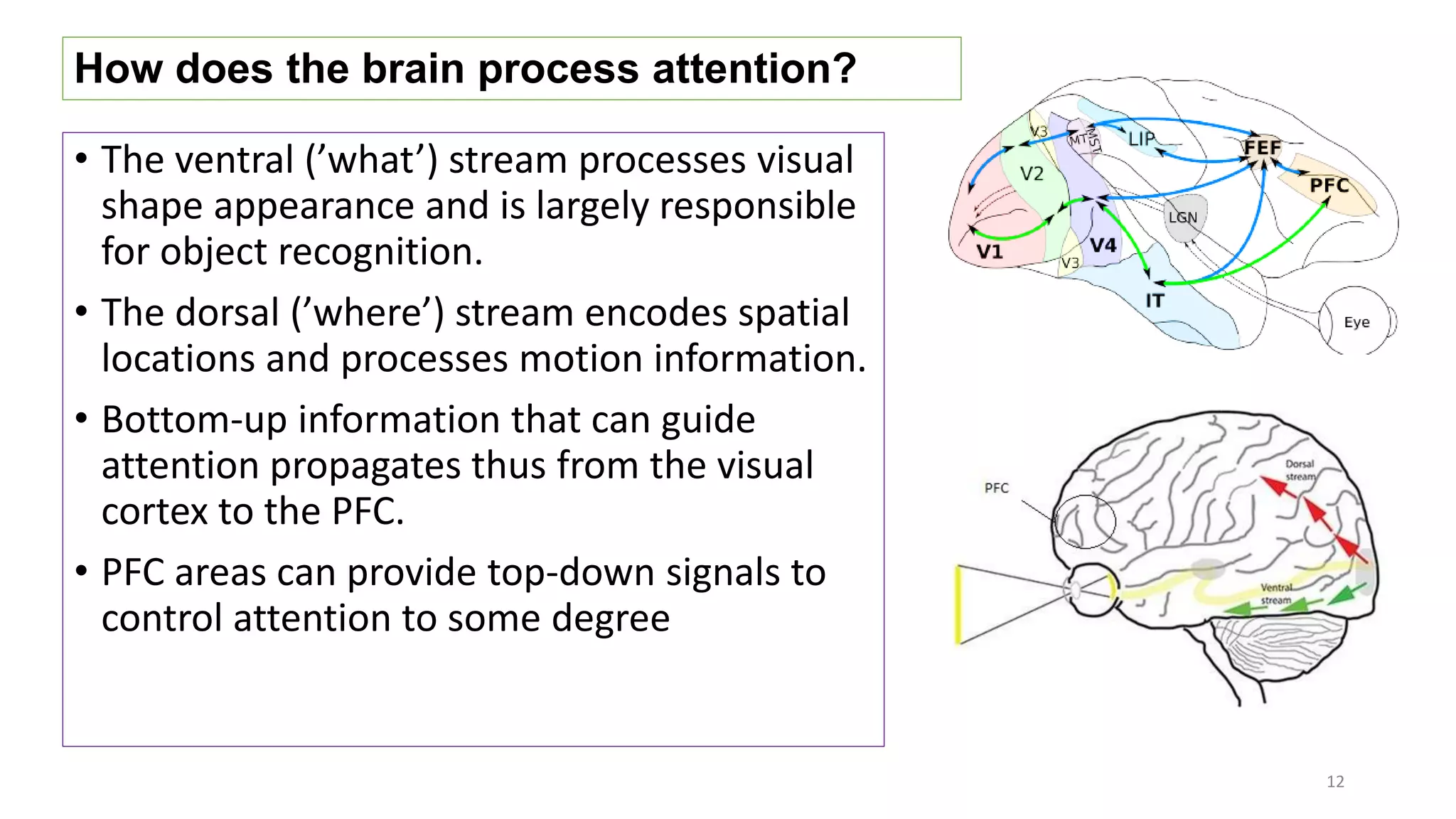
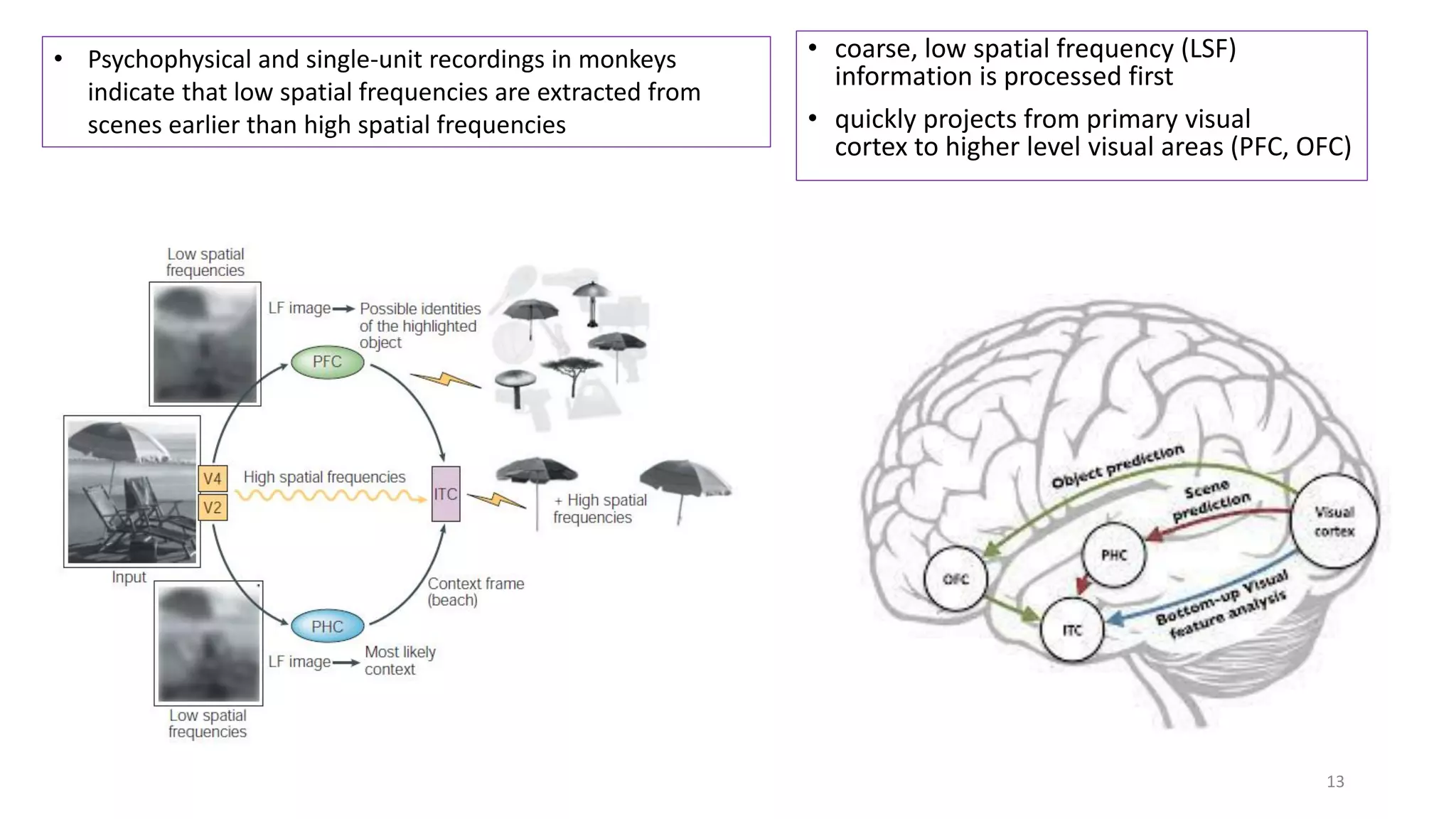
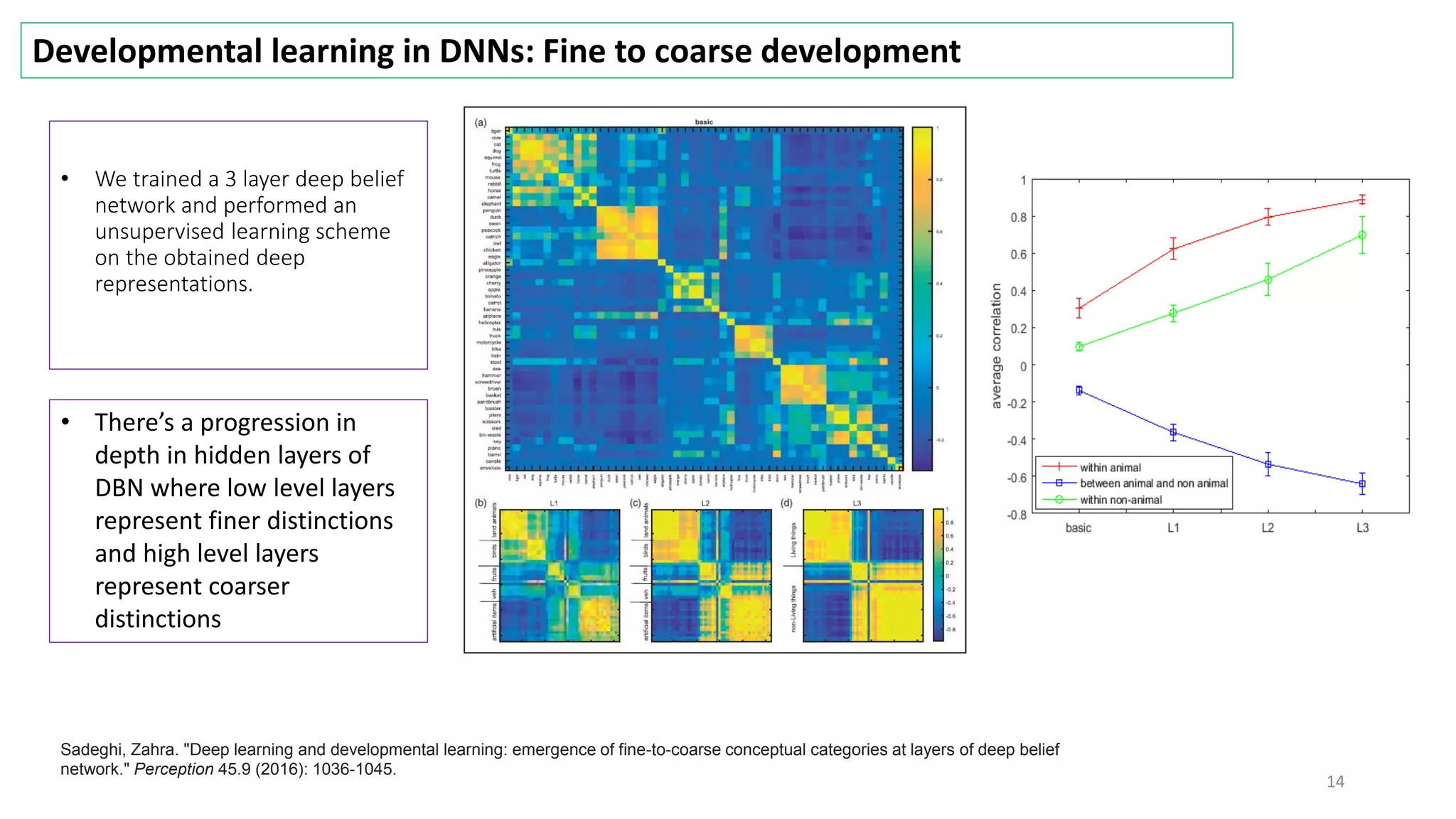

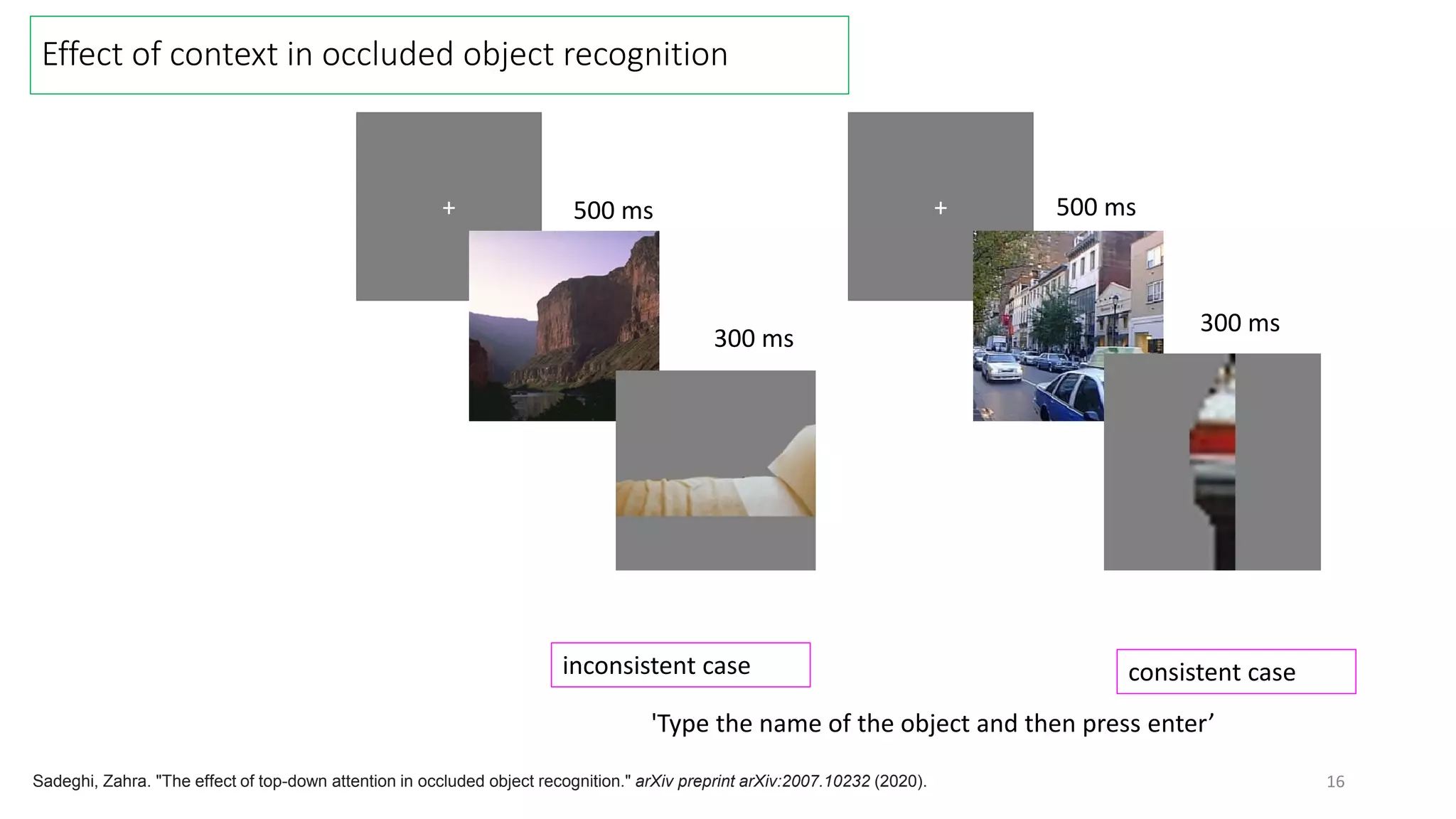
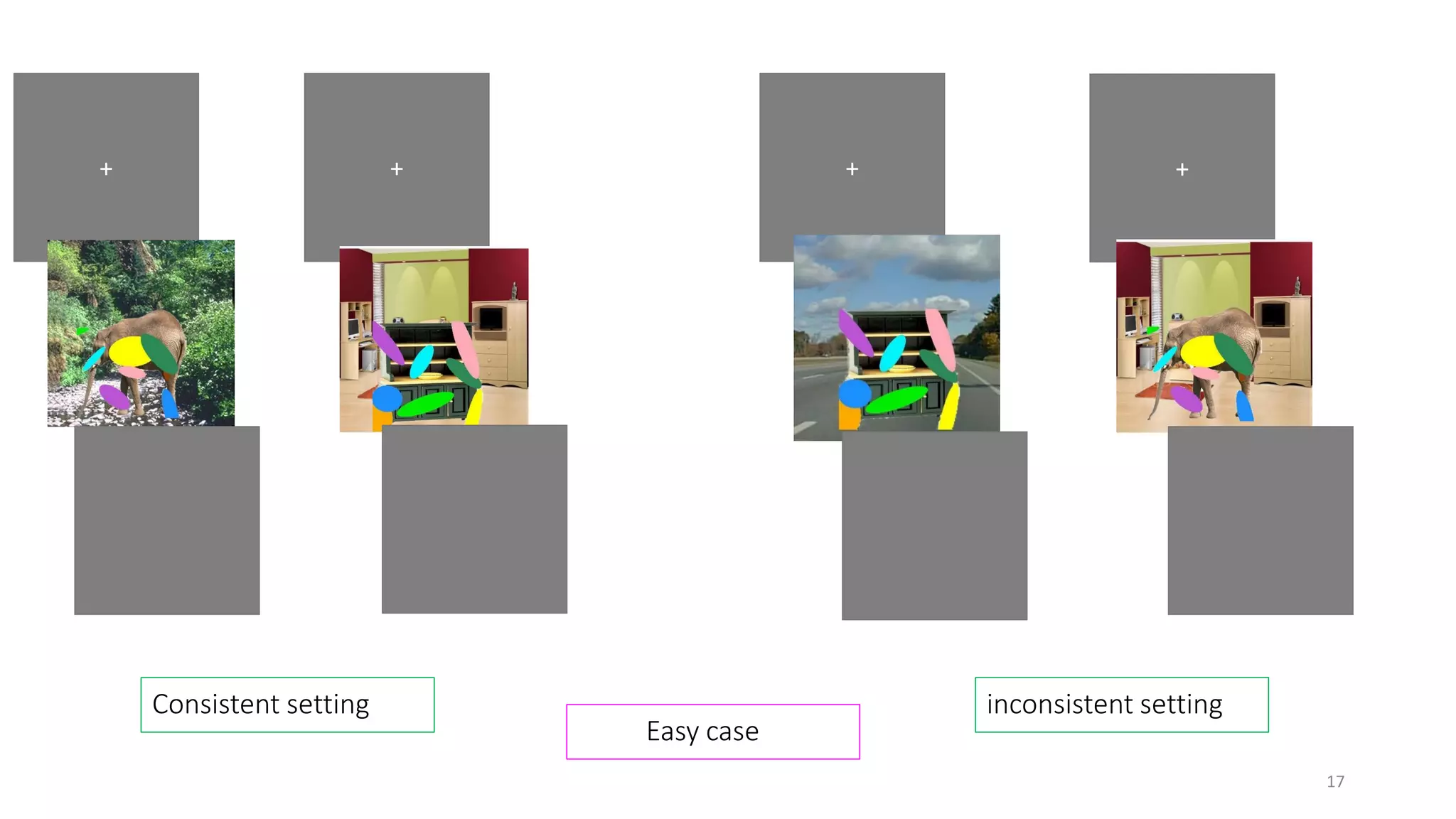
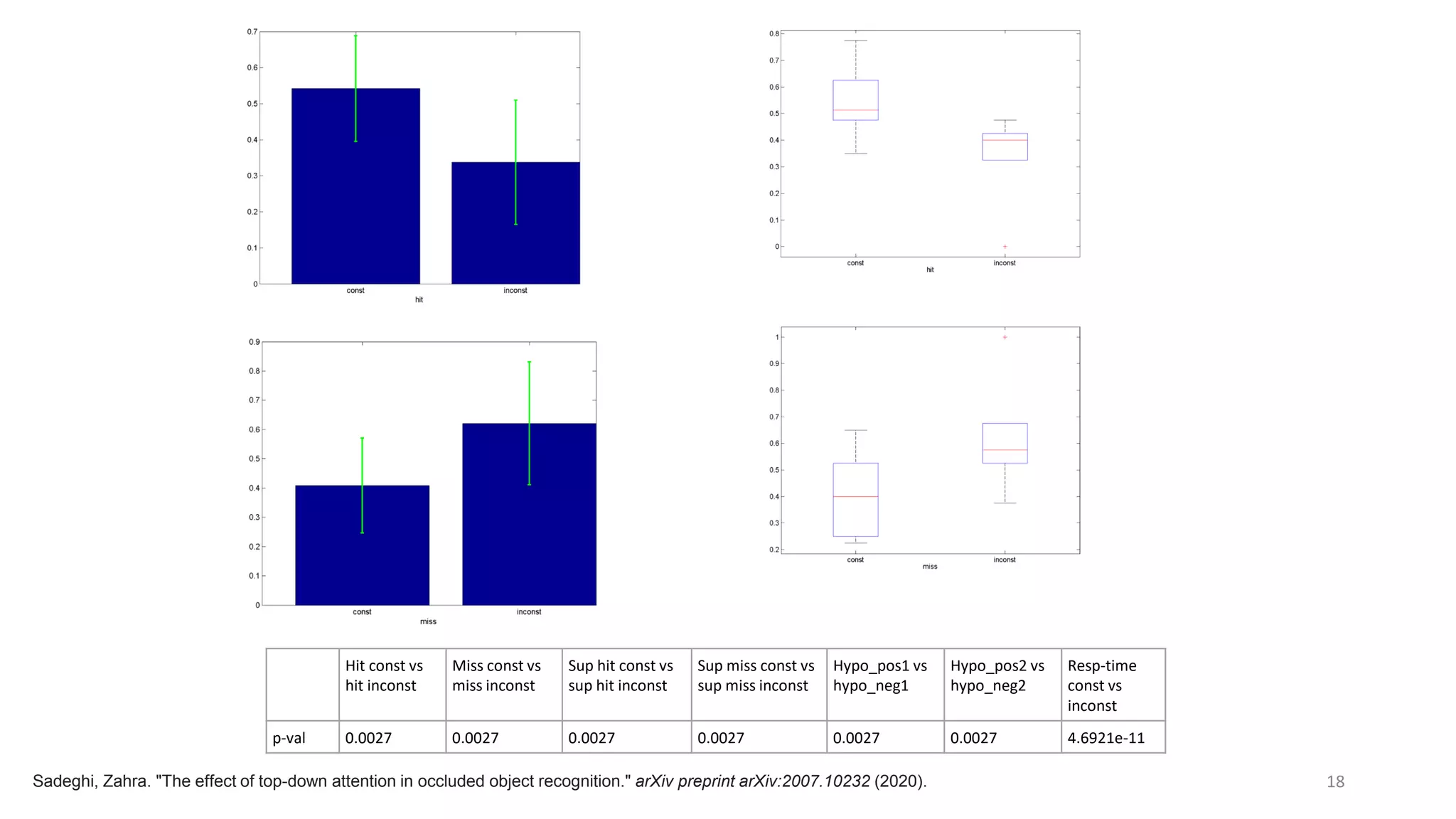
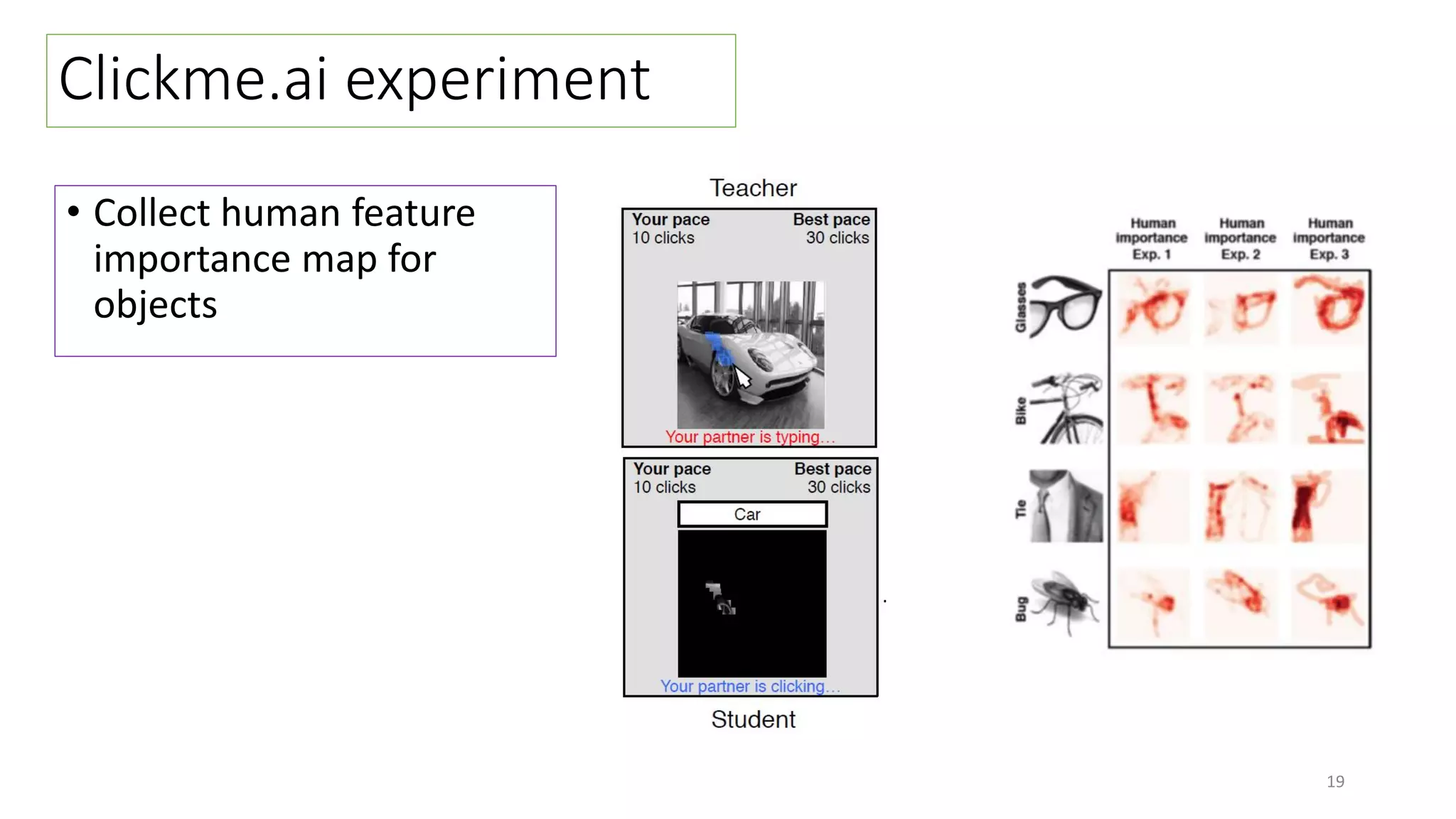
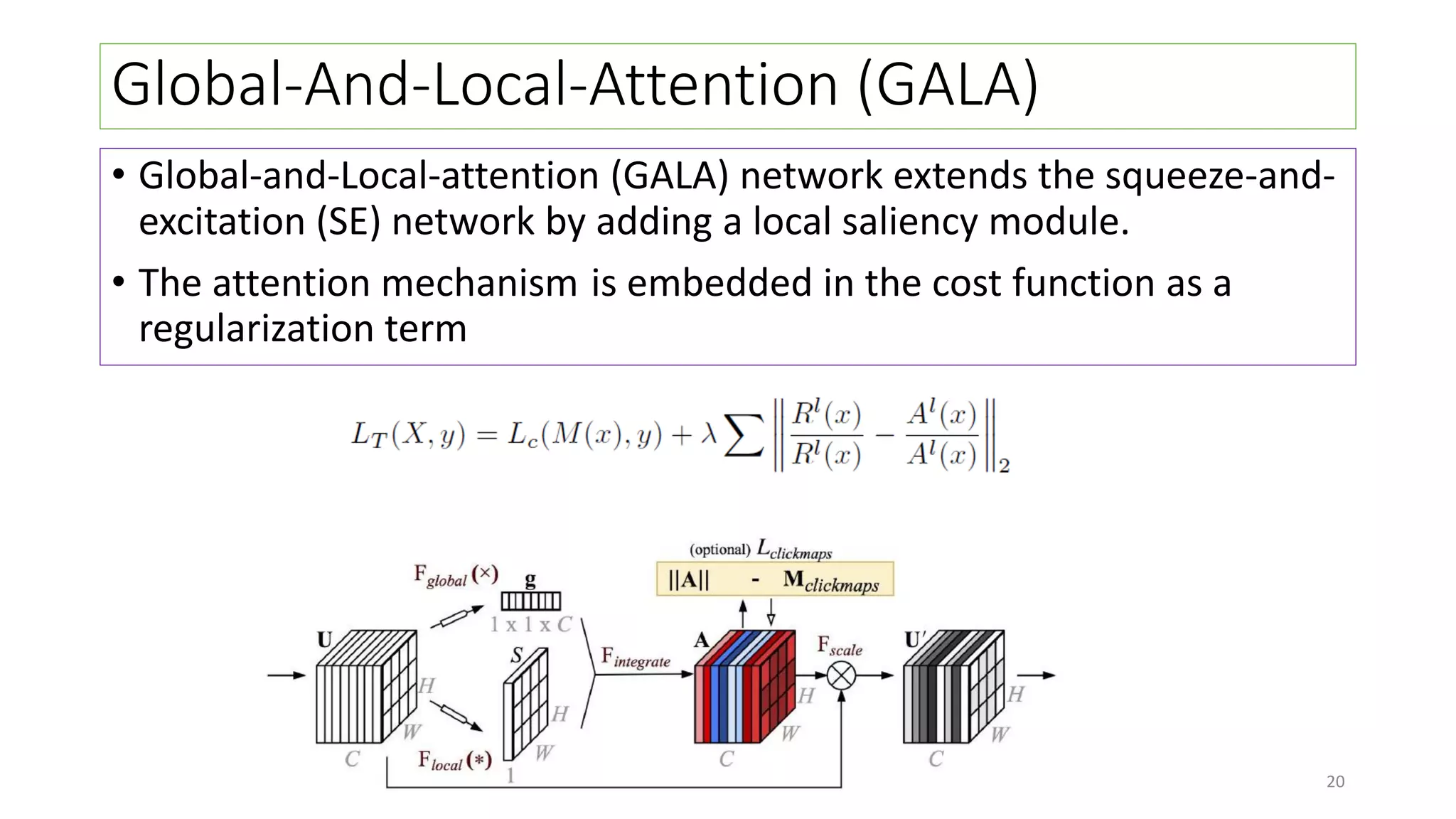





The document discusses visual attention, detailing its mechanisms including bottom-up and top-down attention, visual saliency, and the neural processes involved in attention. It explores how machines can extract salient features from images and compares human and machine attention models, highlighting the importance of context in object recognition. Additionally, it reports on experiments using attention deep neural networks to improve object recognition accuracy based on varying image inputs.



































































