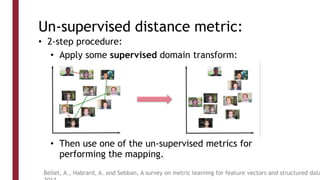
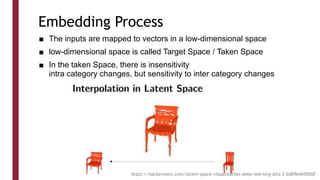
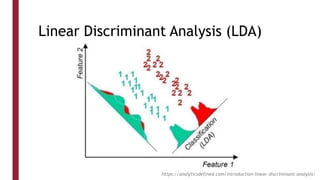
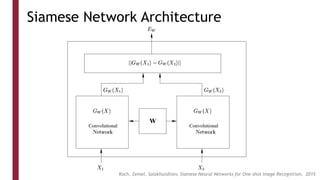
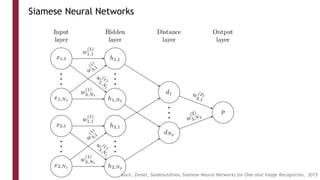
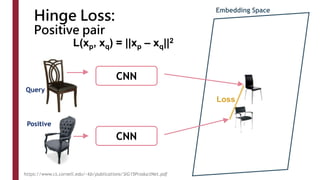
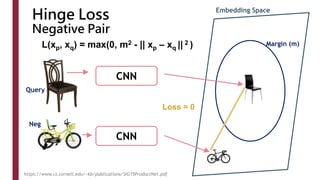
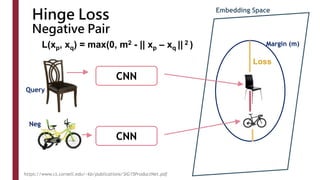
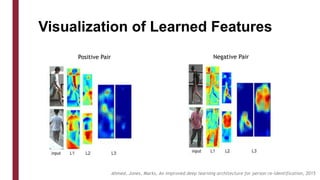
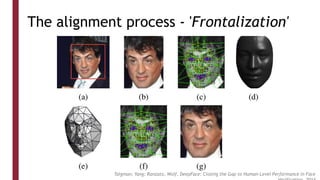
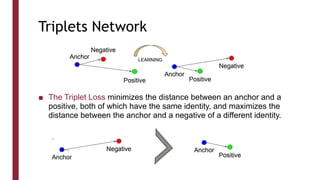
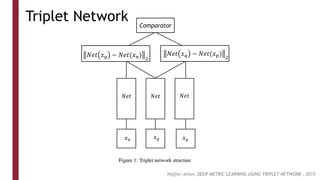
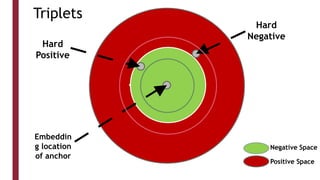
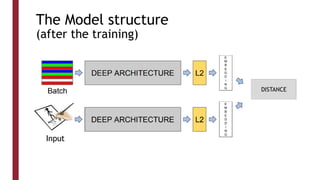
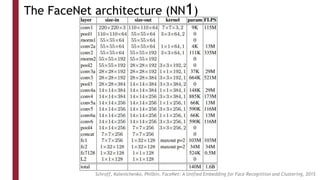
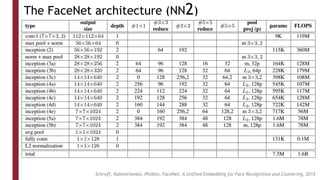
This document discusses one-shot learning techniques for object recognition from few examples. It introduces the concepts of embedding spaces and similarity metrics for measuring distances between objects. Specific deep learning models are described, including Siamese networks, triplet networks, DeepFace, and FaceNet. Siamese networks aim to learn a similarity function using a contrastive loss over input pairs, while triplet networks employ a triplet loss to optimize relative distances between anchor, positive, and negative examples. DeepFace and FaceNet are state-of-the-art face recognition systems that use deep convolutional networks trained with triplet losses to learn embeddings that achieve human-level accuracy on benchmark face datasets.