This document provides an overview of multi-armed bandit algorithms from an algorithmic perspective. It introduces the multi-armed bandit problem and defines it as a reinforcement learning problem where an agent must balance exploring unknown arms versus exploiting the best known arm to maximize rewards over time. The document summarizes several common bandit algorithms, including epsilon-greedy, upper confidence bound, and Thompson sampling. It also discusses extensions for non-stationary and contextual multi-armed bandit problems.
![MULTI-ARMED BANDIT:
AN ALGORITHMIC PERSPECTIVE
Gabriele Sottocornola
gsottocornola[at]unibz[dot]it
Free University of Bozen-Bolzano – University of Milano-Bicocca
December 13th 2021](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-1-2048.jpg)


![Definition(s)
• Reinforcement Learning: At each time step t, an agent choose one
action at among n actions (i.e., arms), based on its knowledge of the
environment, and observes a reward rt
• Machine Learning: We want to learn the parameters of a set of n
probability distributions (i.e., arms), while, at each time step t,
sampling a value rt from chosen distribution at
• Each arm 𝑎! ∈ 𝐴 is associated with an (hidden) mean reward value 𝜇!
• The goal is to maximize the (expected) cumulative reward over a
number of time steps T. Alternatively minimize the regret
𝑅" = '
#$%
"
𝑟# ; *
𝑅" = '
#$%
"
E[𝑟#] ; 𝜌 = 𝑇𝜇∗
− *
𝑅"](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-5-2048.jpg)
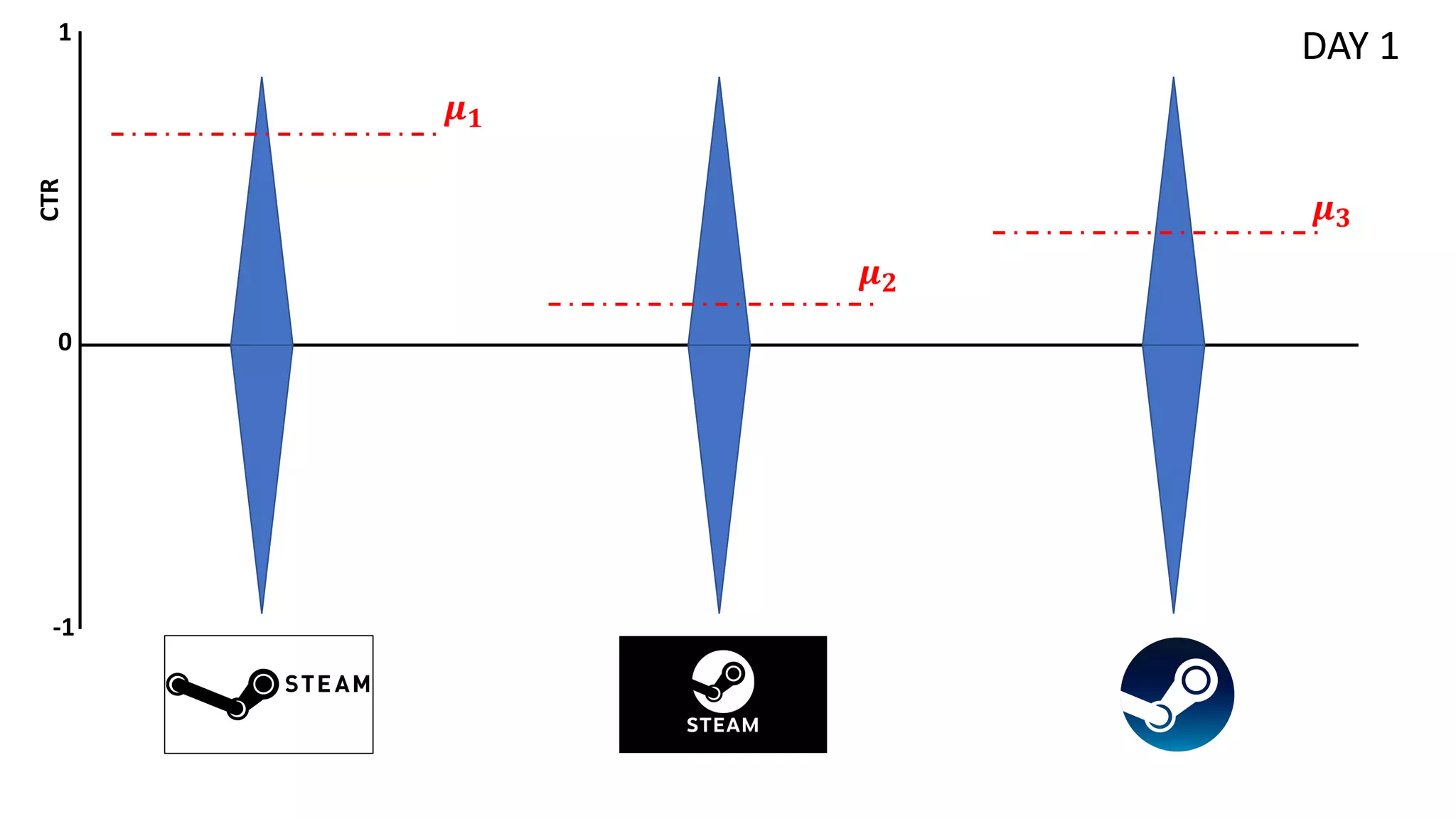
![Preliminaries
• Exploration/exploitation decision making trade-off
• Exploration: gather information about different arms
• Exploitation: make the best choice given current information
• Bandit/Semi-bandit feedback: no full information available
• Online learning of the local optimal action
• Stochastic MAB with i.i.d. rewards (unless non-stationary or adversarial)
• Research directions:
• Proof of theoretical bounds [Auer et al., 2002]
• Application of MAB algorithms to real-world/simulated problems
• (Bayesian optimization) [Shahriari et al., 2015]
• Off-policy (counterfactual) learning/evaluation [Jeunen & Goethals, 2021]](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-6-2048.jpg)

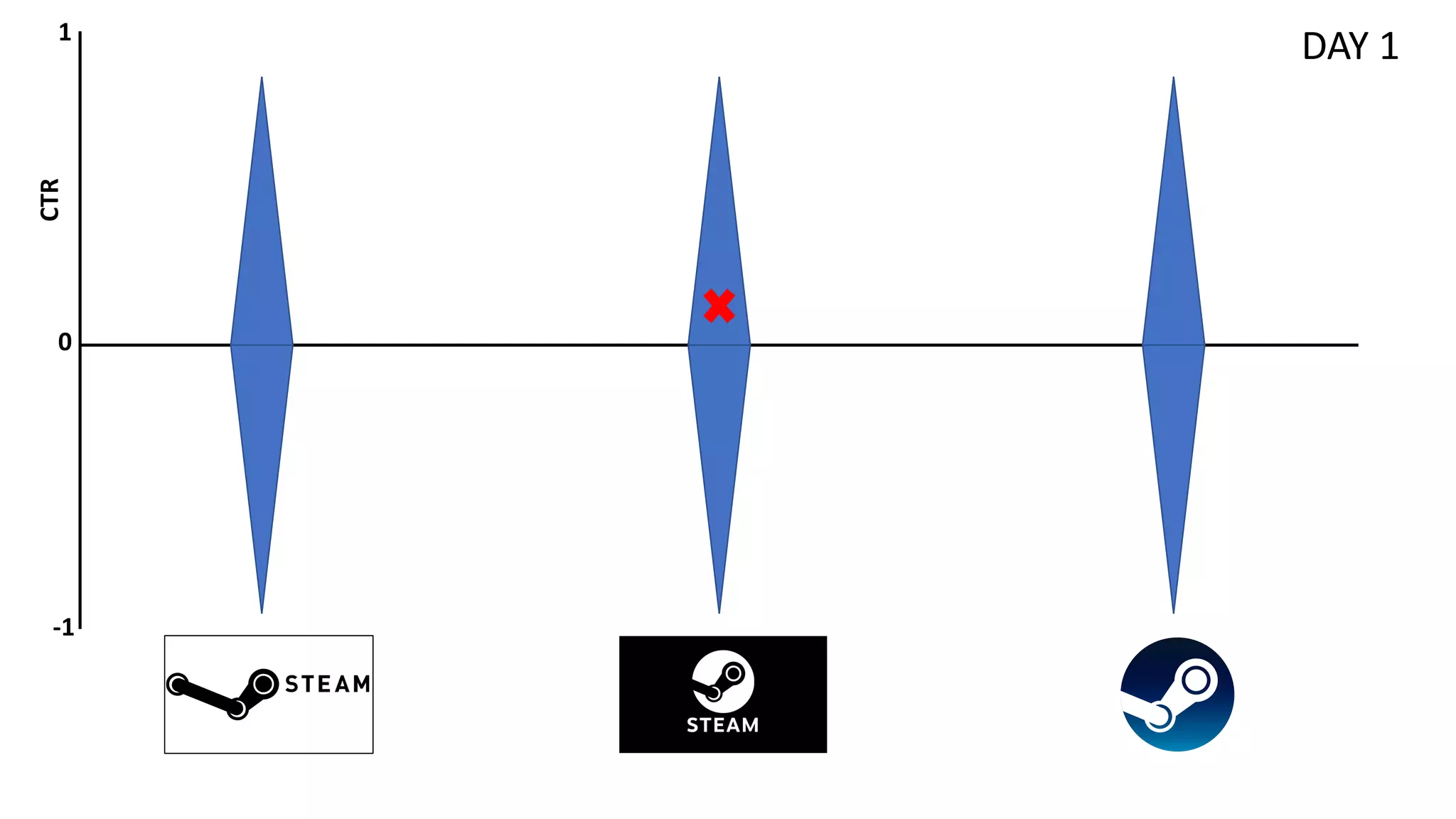
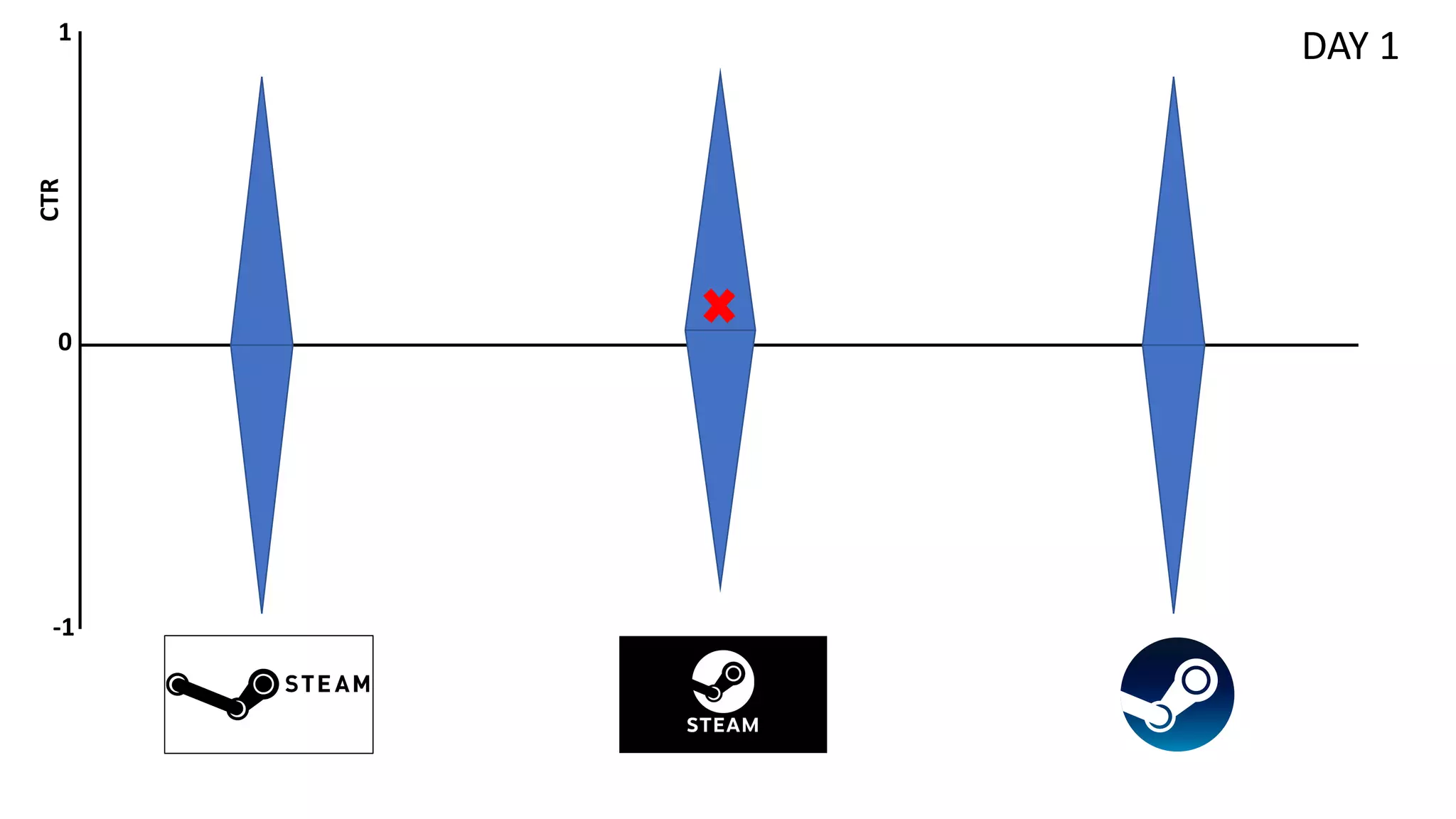
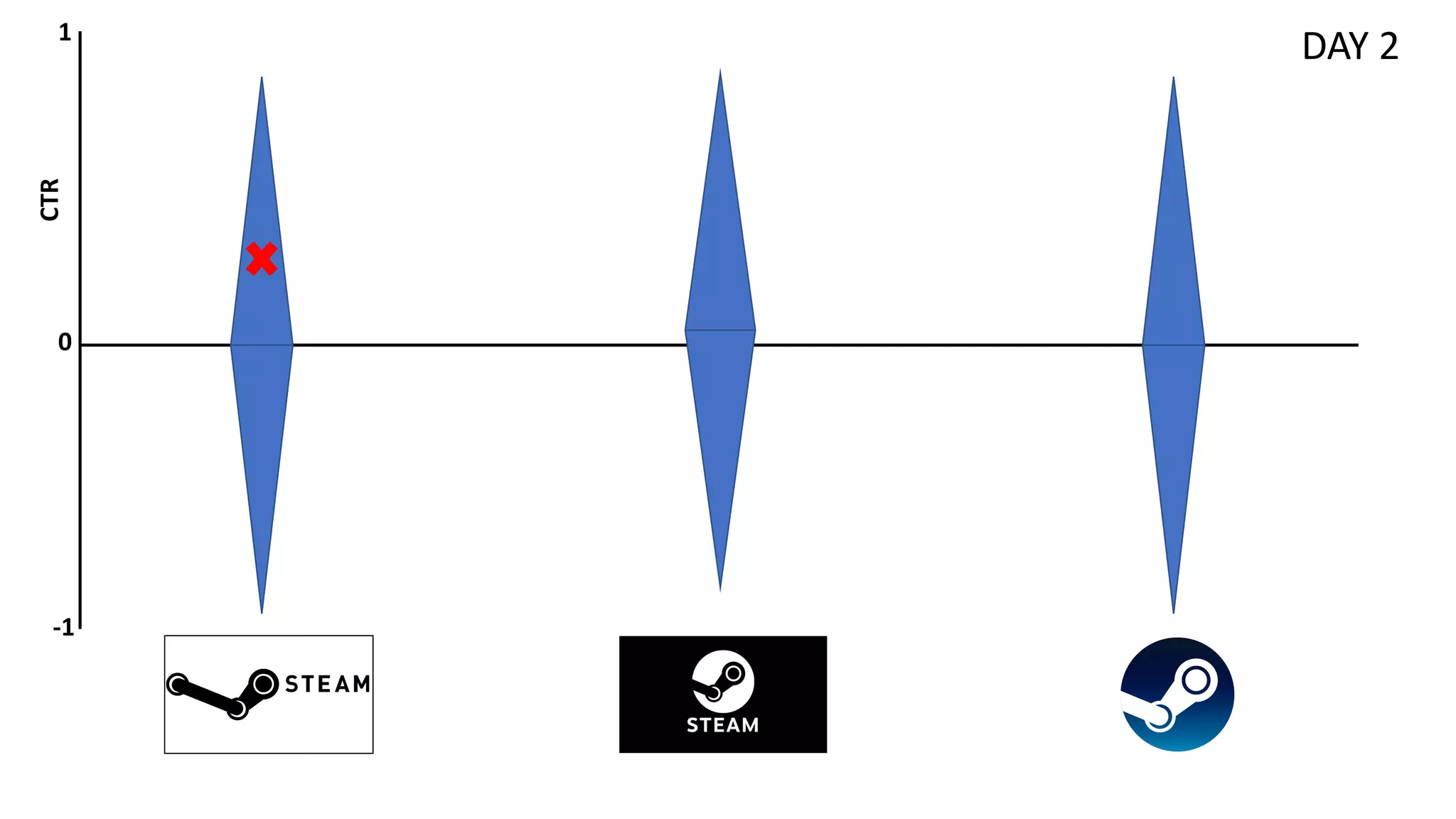
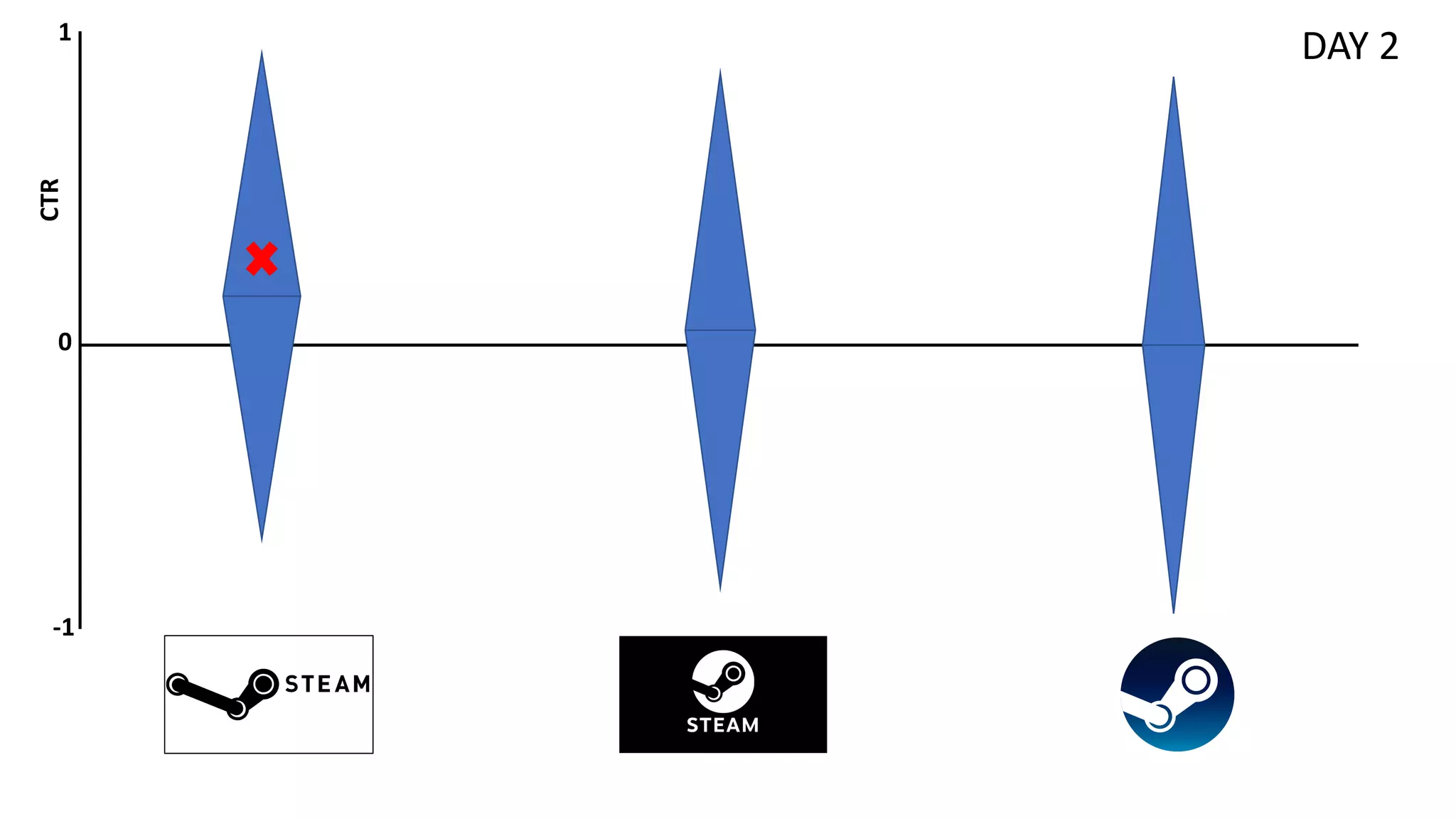
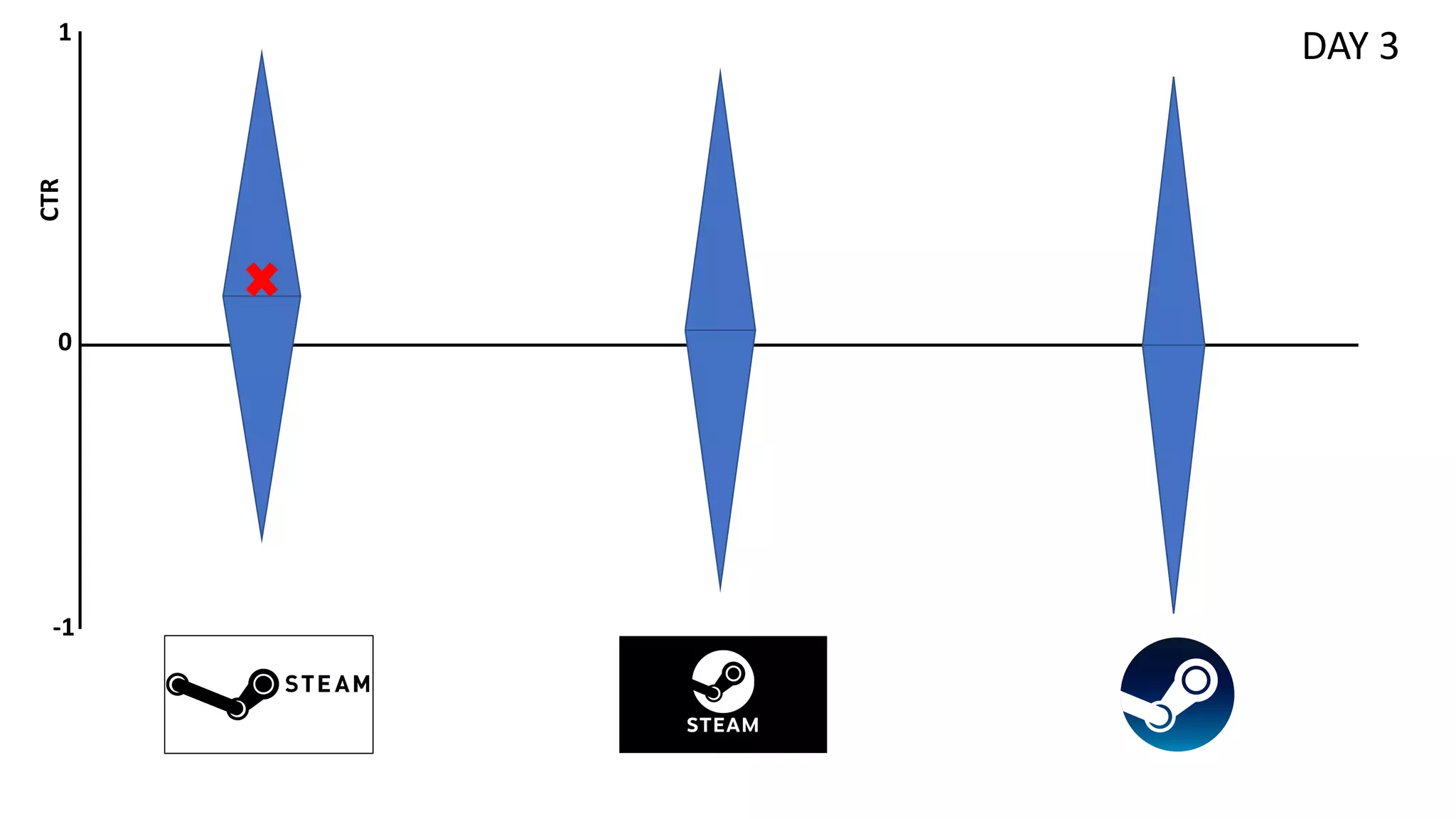
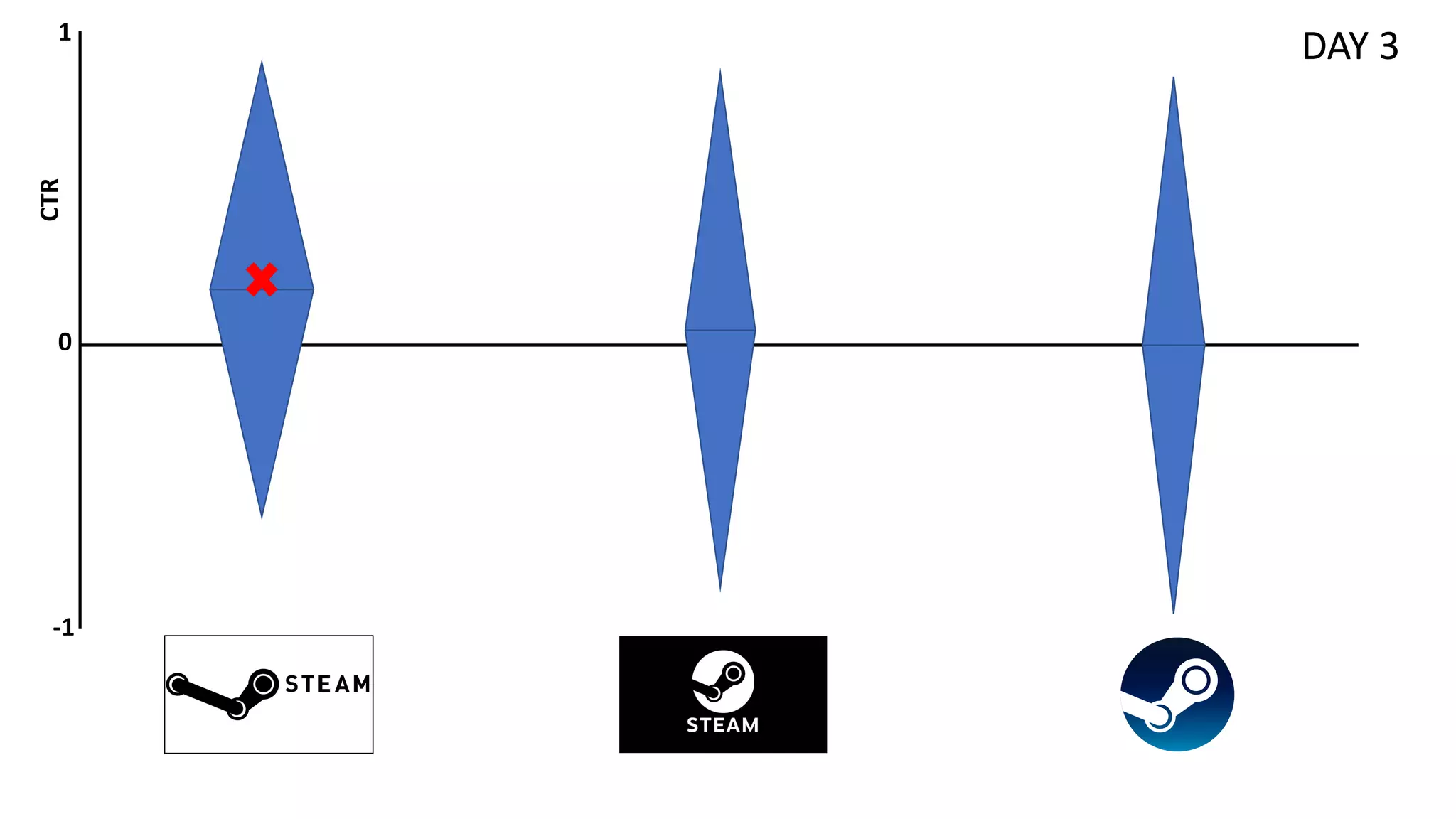

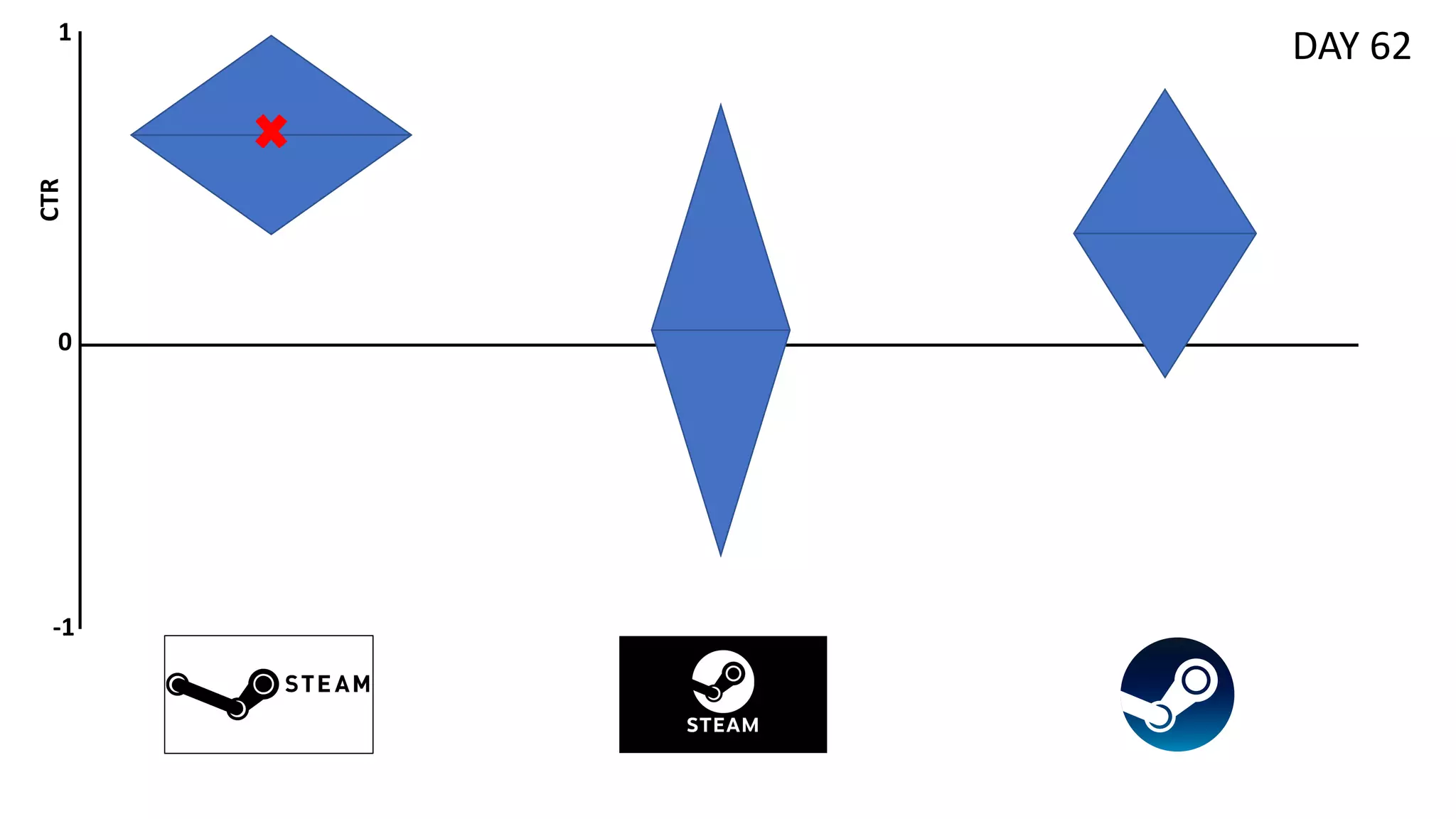
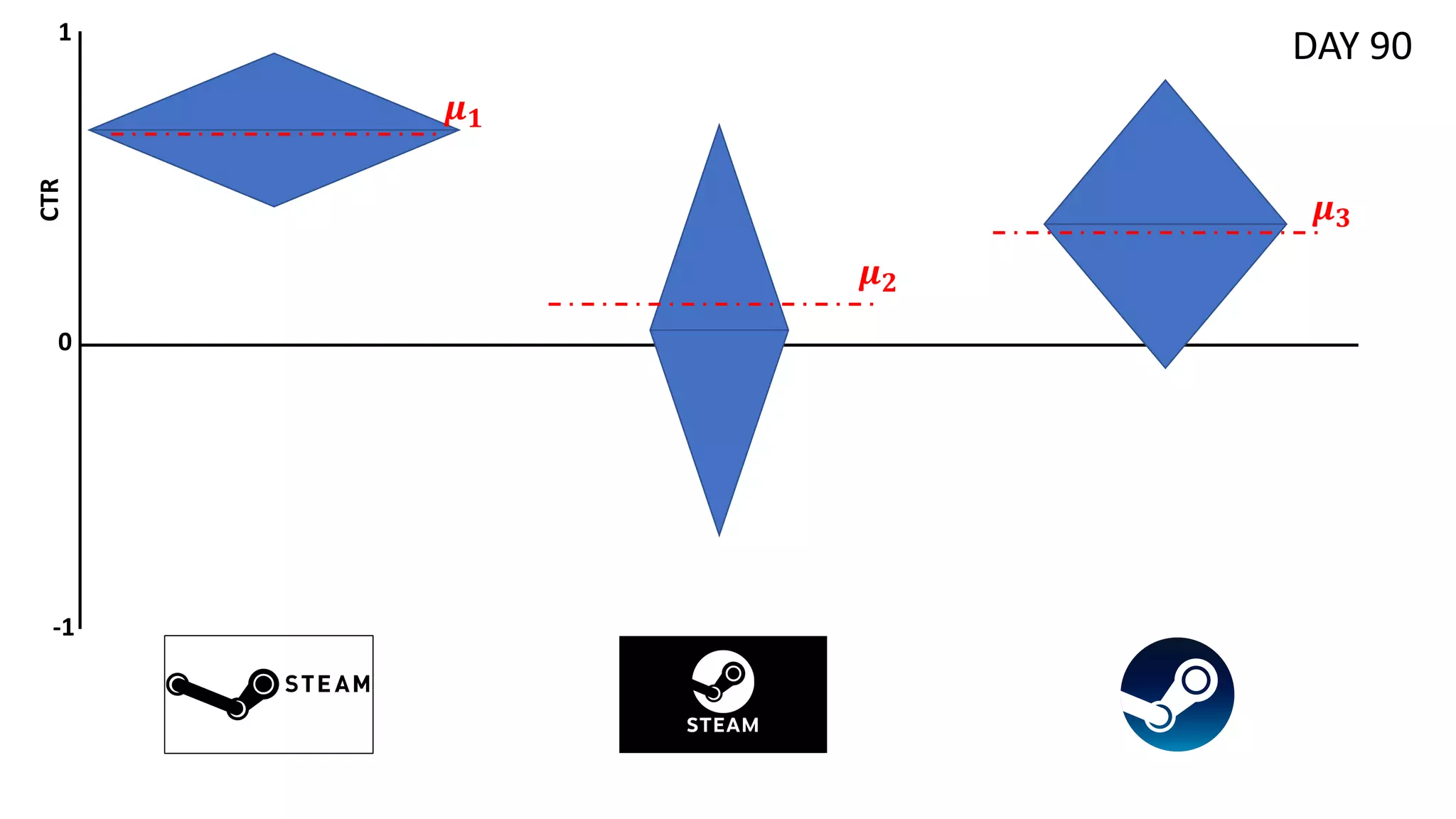



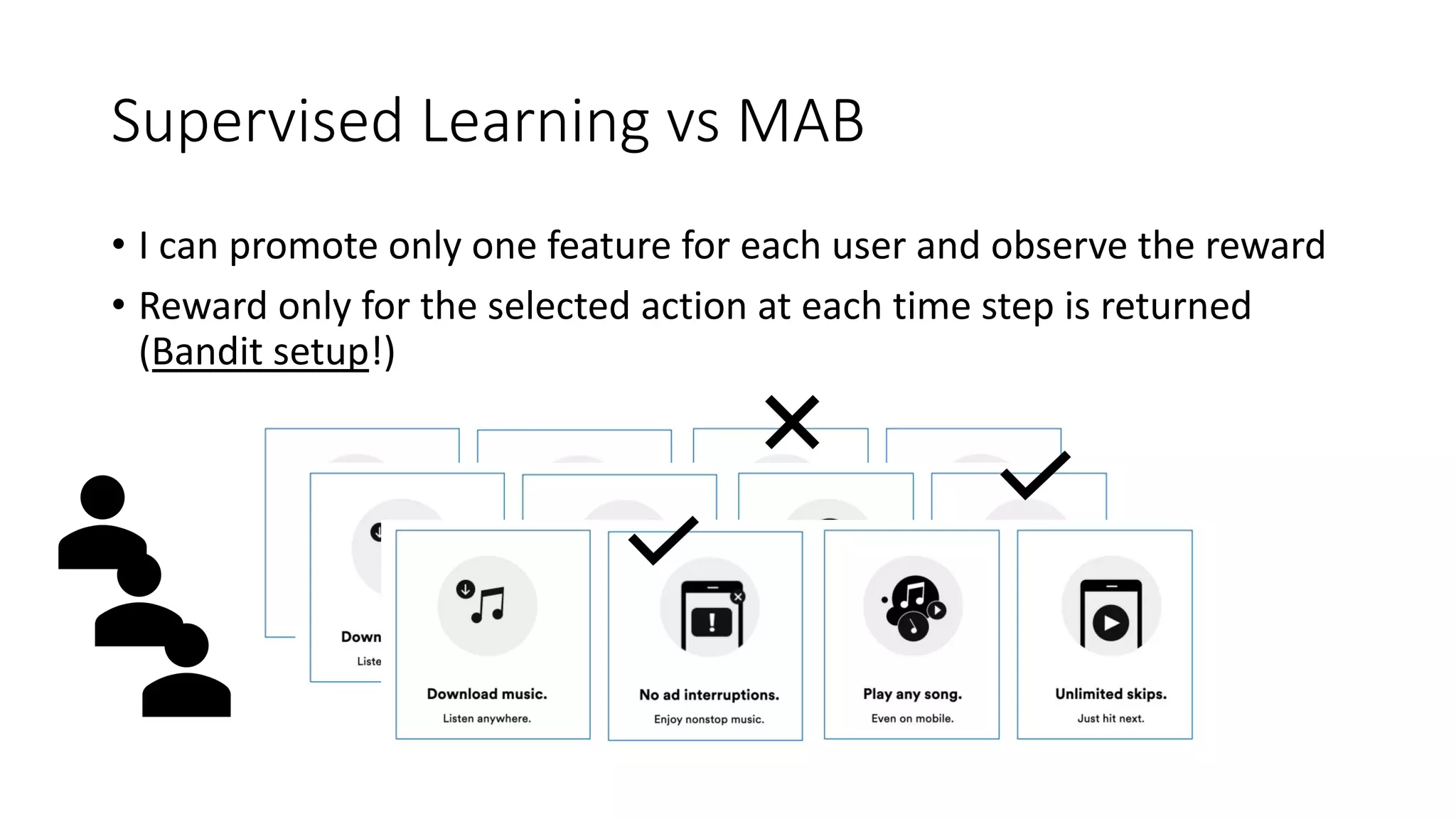


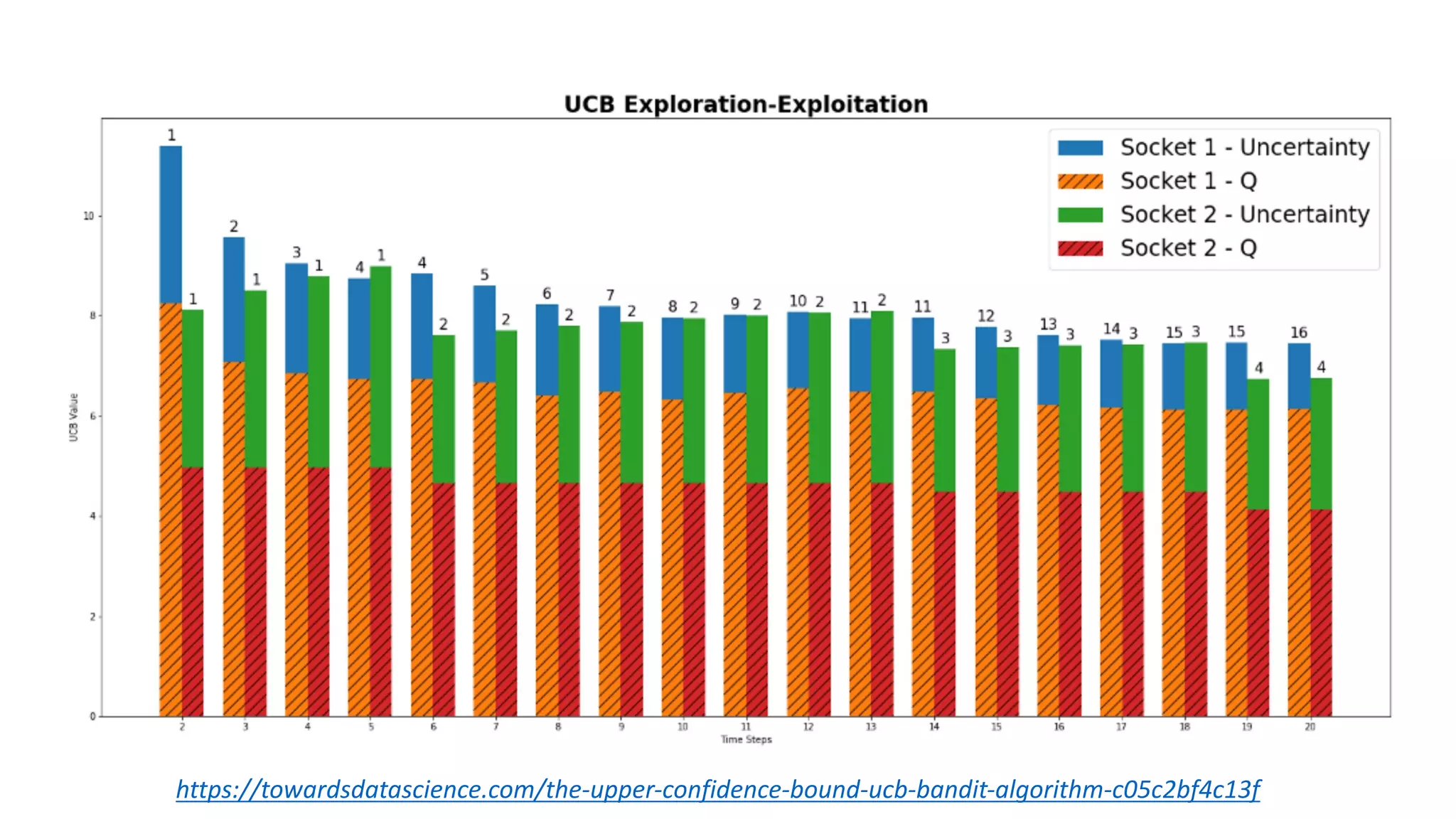
![Preliminaries
• Assumption: Stochastic MAB with Bernoulli rewards (e.g., casino)
• Bernoulli reward 𝑟% ∈ 0, 1
• Probability of success 𝑝$ = P𝑖 𝑟% = 1 for each arm 𝑎$ ∈ 𝐴
• 𝜇$ = 𝑝$ estimated with E ℬ 𝛼, 𝛽 (i.e., Beta is Bernoulli conjugate prior, with
𝛼 successes and 𝛽 failures)
• Blueprint of a MAB action selection:
𝑎# = argmax
'
[𝑄# 𝑎 + 𝑉# 𝑎 ]](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-28-2048.jpg)








![Thompson Sampling
Where E[ℬ] = -
𝑝! ≈ 𝑝! of Bernoulli](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-38-2048.jpg)
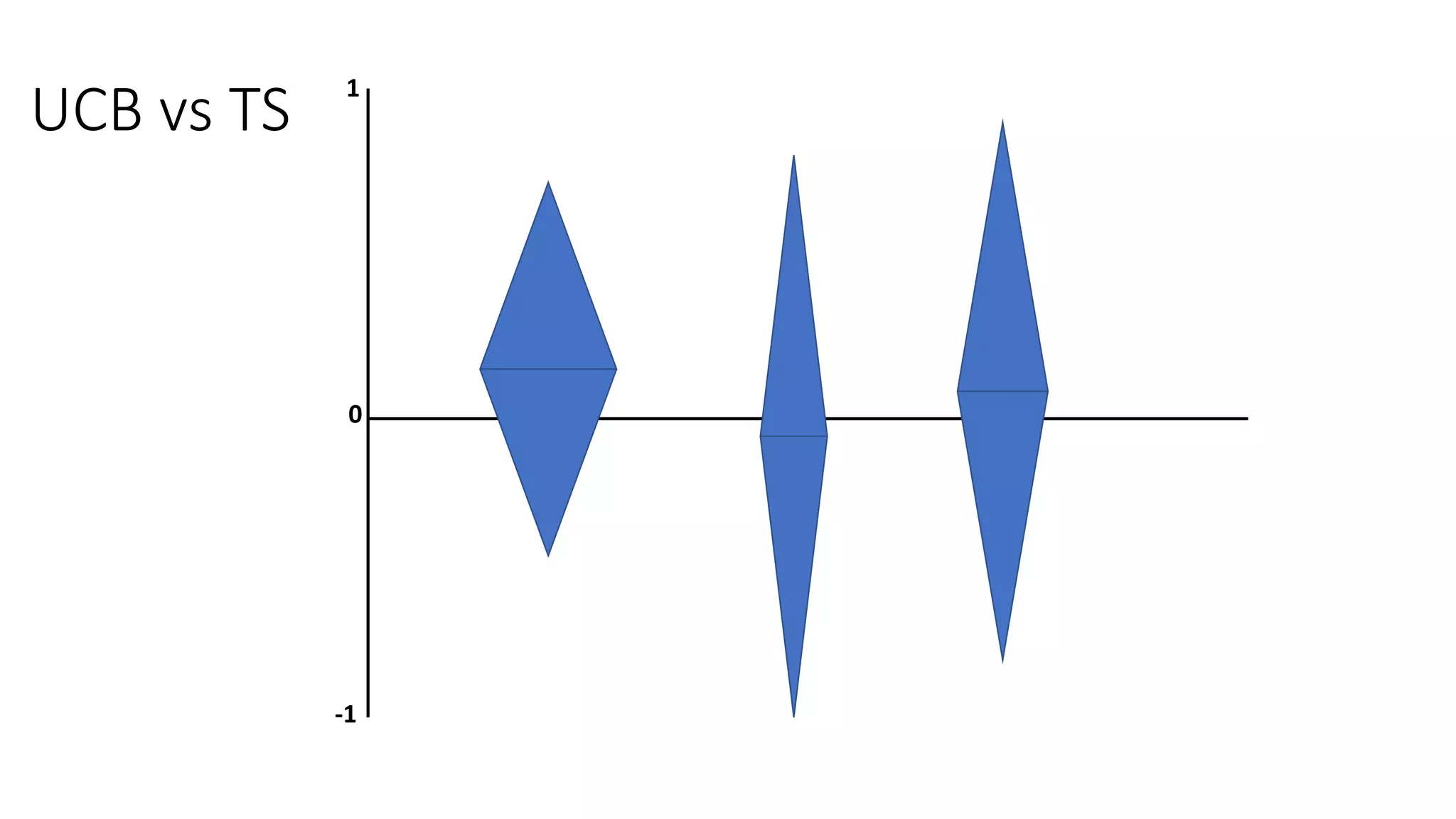
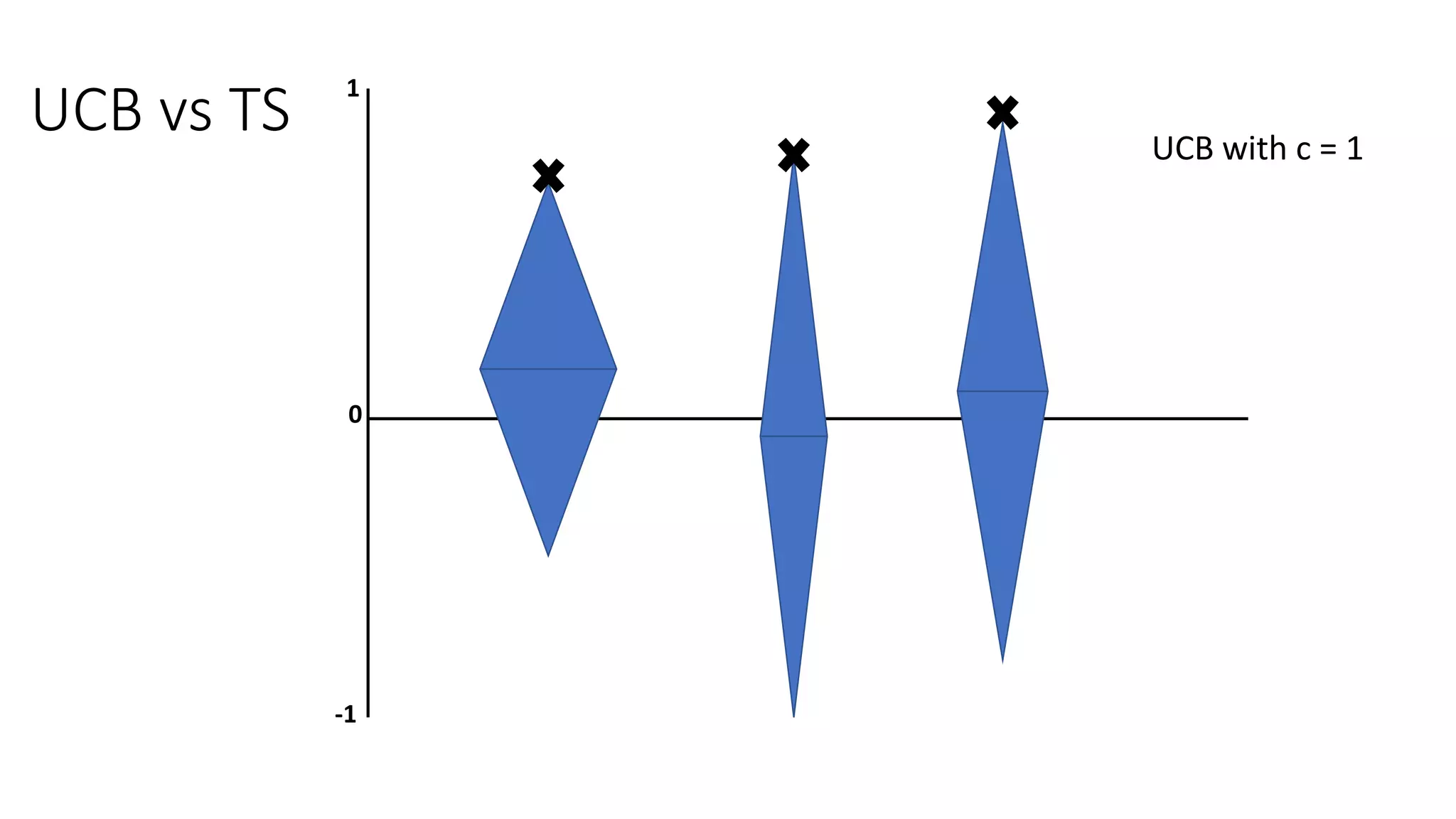
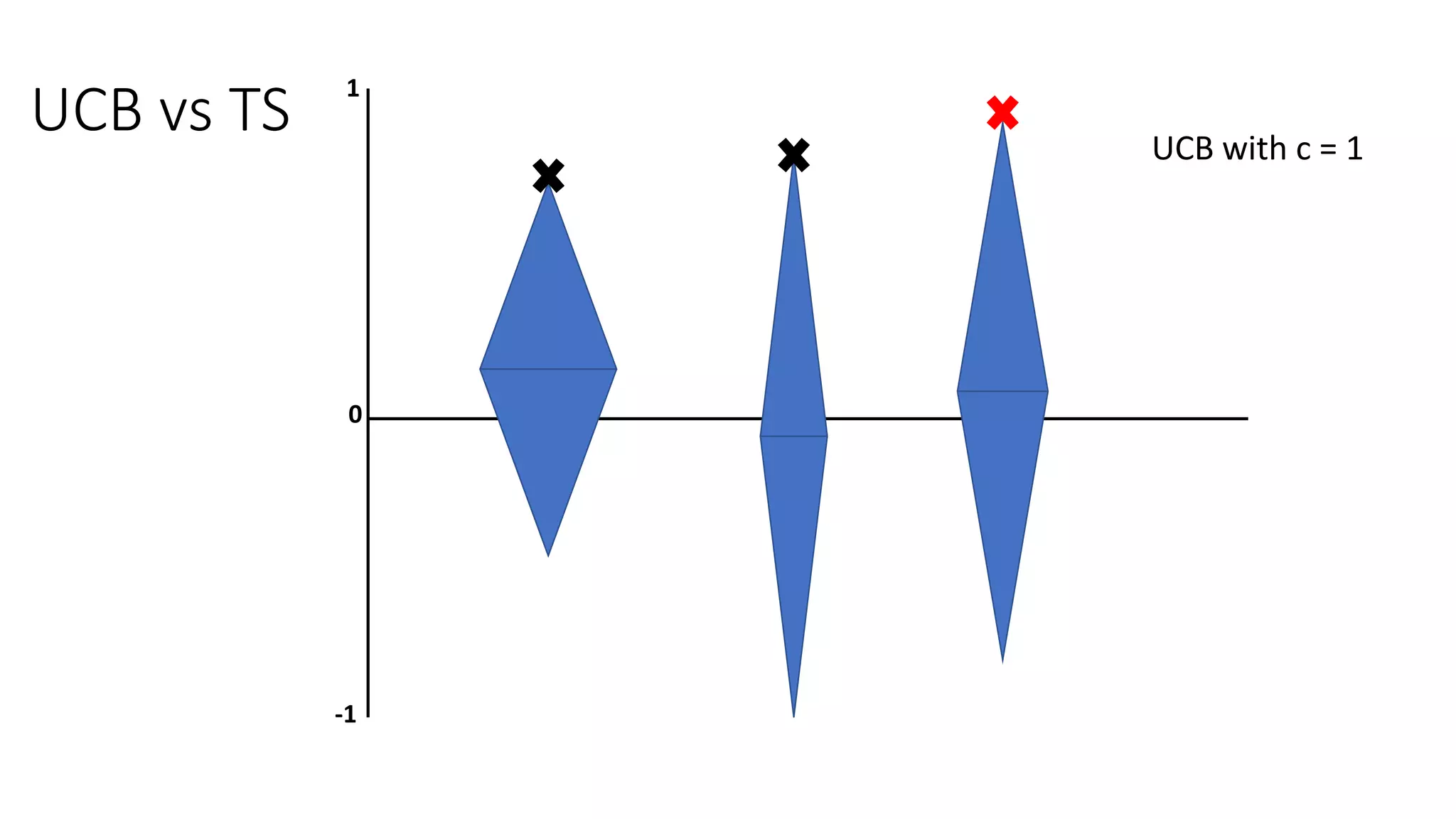
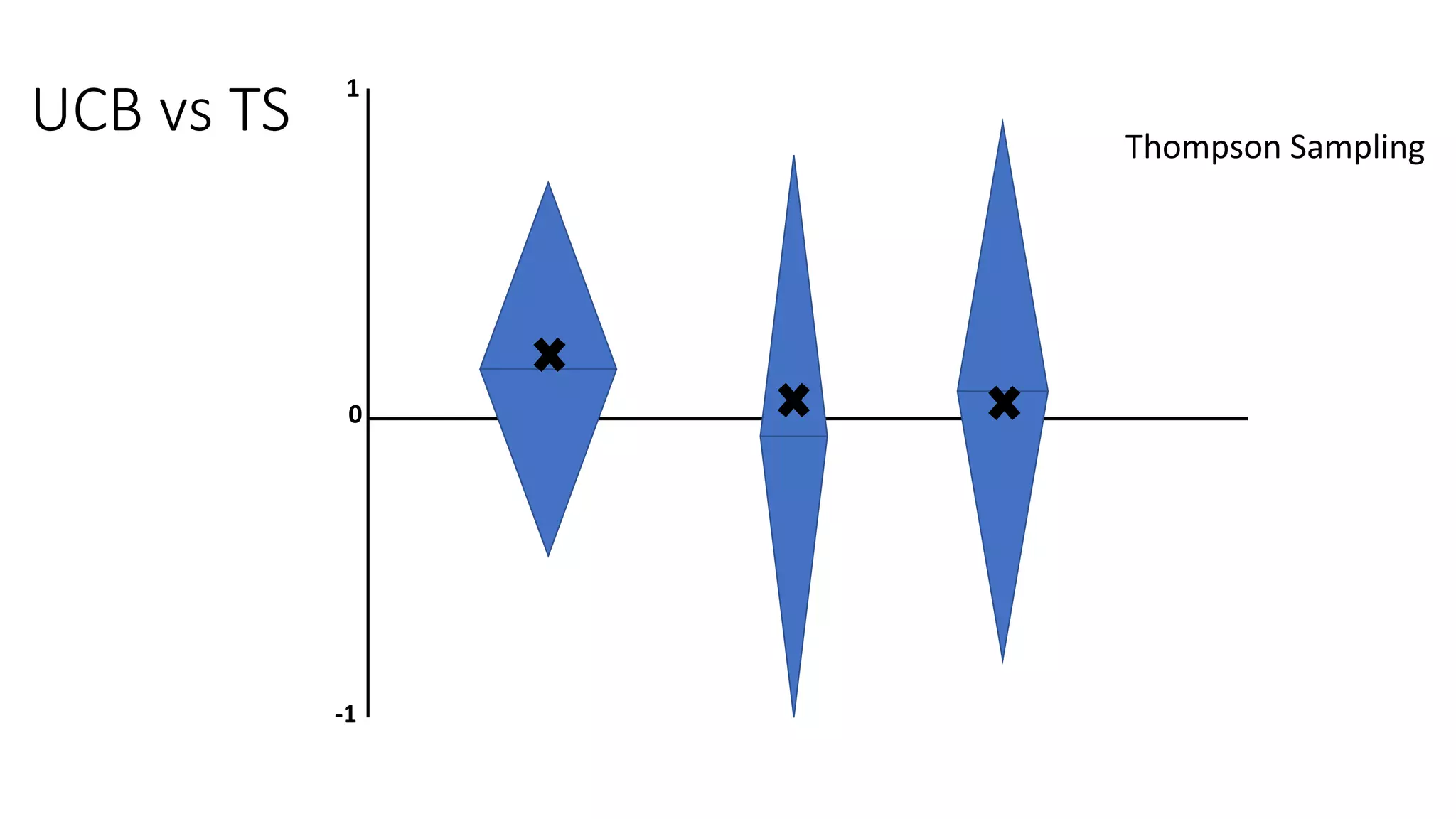

![Motivation
• Relax the assumption of rewards being drawn i.i.d. -> Expected reward
distributions evolve over time ∃𝑡 , 𝑖 ∶ 𝜇!
#
≠ 𝜇!
#0%
• 𝑅" = ∑#$%
"
𝑟# ; *
𝑅" = ∑#$%
"
E[𝑟#] ; 𝜌 = ∑#$%
"
𝜇#,∗
− *
𝑅"
• Useful in applications in which seasonal/evolving distributions might be
observed (also referred as concept drift in ML) [Žliobaitė et al., 2016]
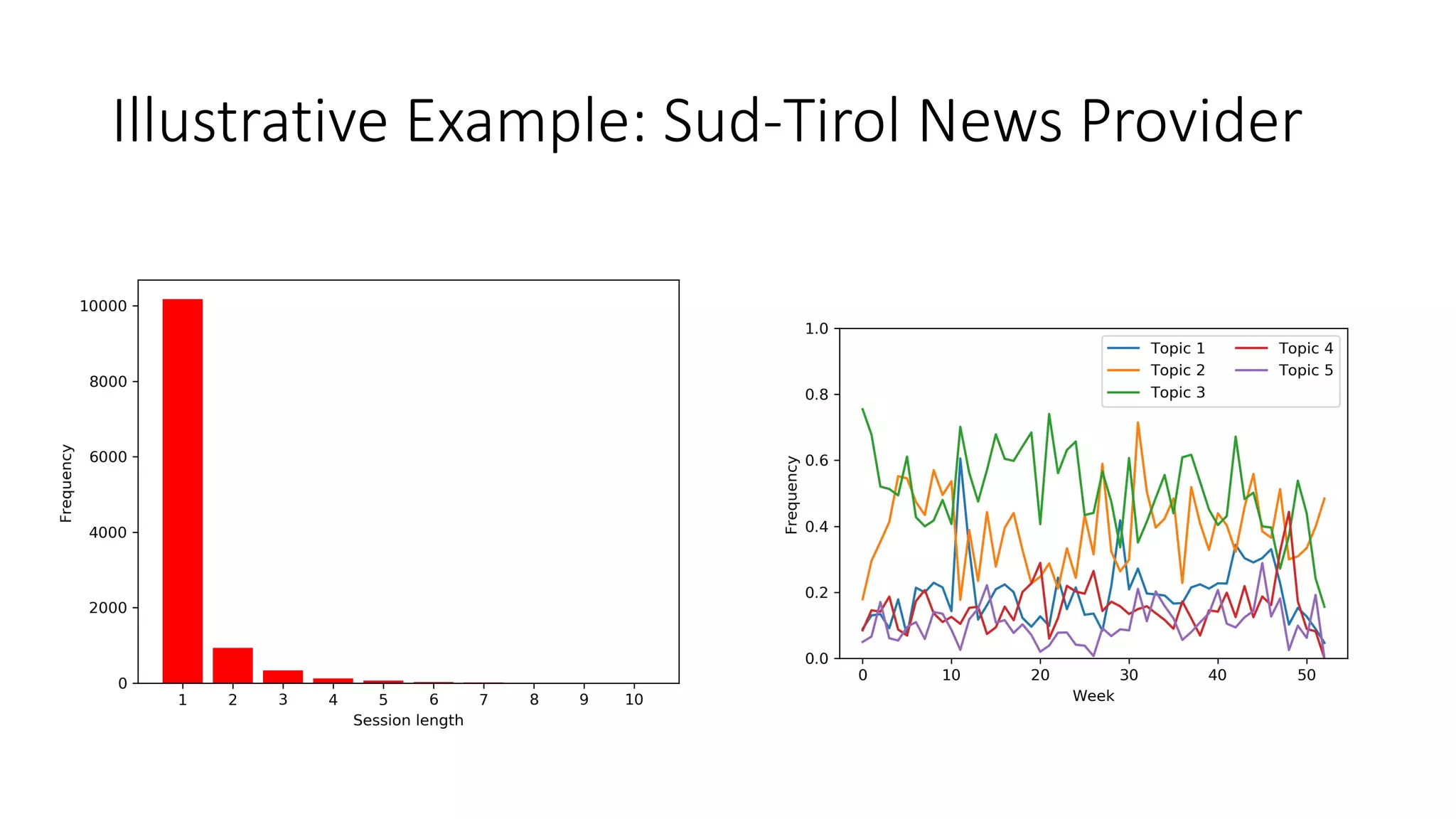
• e.g., Short-session news recommendation
• Few interactions per users (no data for personalization)
• Rapidly evolving trends (i.e., topic distributions) over the days](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-45-2048.jpg)
![Discounted TS
[Raj & Kalyani, 2017]](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-47-2048.jpg)
![Discounted TS
[Raj & Kalyani, 2017]
𝛾 factor of discount for older rewards](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-48-2048.jpg)
![Sliding-Window TS
[Trovò et al., 2020]](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-49-2048.jpg)
![Sliding-Window TS
Consider only last 𝜏 rewards when
computing ℬ parameters
[Trovò et al., 2020]](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-50-2048.jpg)
![f-Discounted
Sliding-Window TS
[Cavenaghi et al., 2021]](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-51-2048.jpg)
![f-Discounted
Sliding-Window TS
Historic trace with discounted rewards
[Cavenaghi et al., 2021]](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-52-2048.jpg)
![f-Discounted
Sliding-Window TS
Hot trace with sliding window
[Cavenaghi et al., 2021]](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-53-2048.jpg)
![f-Discounted
Sliding-Window TS
• Two samples for each arm at t
• Historic discounted trace
• Sliding-window hot trace
• Combination of the two
parameters via an aggregation
function f (e.g., min, max,
mean)
[Cavenaghi et al., 2021]](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-54-2048.jpg)
![Simulated Decreasing Reward (environment)
[Cavenaghi et al., 2021]](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-55-2048.jpg)
![Simulated Decreasing Reward (reward/regret)
[Cavenaghi et al., 2021]](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-56-2048.jpg)
![Comparison on Real-World Data
[Cavenaghi et al., 2021]
More experiments and details in the paper @ https://www.mdpi.com/1099-4300/23/3/380
Open-source code @ https://github.com/CavenaghiEmanuele/Multi-armed-bandit](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-57-2048.jpg)
![More Advanced Methods
• Change-point detection UCB [Liu et al., 2018]
• Concept drift sliding-window with TS [Bifet & Gavalda, 2007]
• Burst-induced MAB [Alves et al., 2021]
• ...](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-58-2048.jpg)








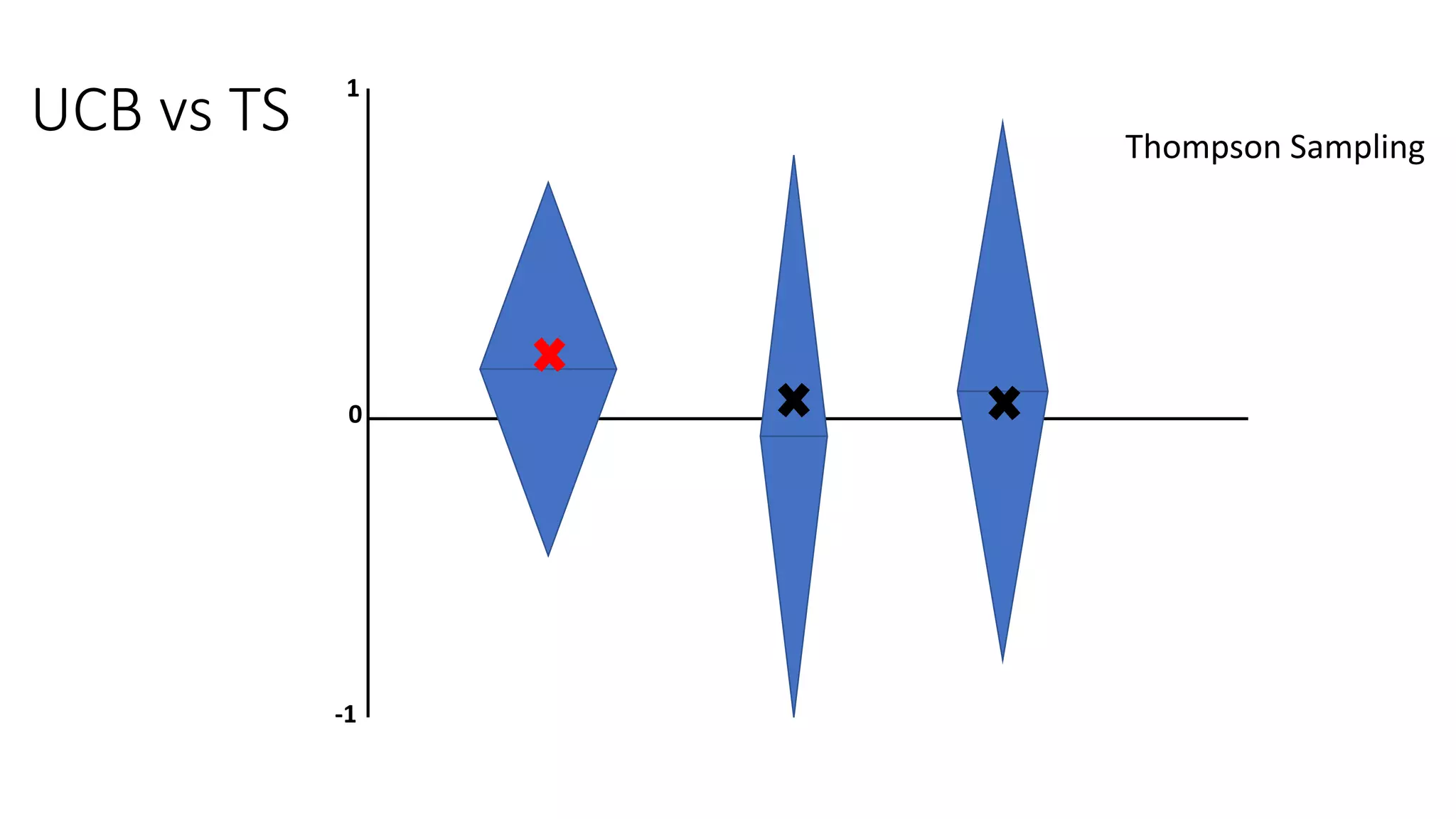
![Thompson Sampling
[Agrawal & Goyal, 2013]](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-68-2048.jpg)
![Thompson Sampling
We sample from a multivariate Gaussian distribution
with mean vector )
𝝁 and covariance matrix 𝑩!"
[Agrawal & Goyal, 2013]](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-69-2048.jpg)
![Thompson Sampling
[Agrawal & Goyal, 2013]
We assume an underlying unknown parameter 𝝁∗
,
which is approximated by 𝒖𝒕 , such that the expected
reward is a linear combination E 𝑟%,' = 𝒙𝒕,𝒂 𝝁∗](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-70-2048.jpg)
![Thompson Sampling
[Agrawal & Goyal, 2013]
Parameters update based on given context
𝒙𝒕,𝒂 and reward rt following Ridge Regression](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-71-2048.jpg)
![Linear Upper Confidence Bound
[Li et al., 2010]](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-72-2048.jpg)
![Linear Upper Confidence Bound
[Li et al., 2010]](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-73-2048.jpg)
![Linear Upper Confidence Bound
[Li et al., 2010]](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-74-2048.jpg)
![Case Study: Conversational Picture-based DSSApple
• Apple is the third most produced fruit worldwide (86+ million metric tons in
2019), apple exports are valued 7+ billion USD
• Problem: Post-harvest disease, occurring during storage, is one of the main
causes of economic losses for apples production (10% in integrated – 30% in
organic)
• Goal: Develop a Decision Support System (DSS) fully based on user
interaction with symptom images to guide the diagnosis of post-harvest
diseases of apples
[Sottocornola et al., 2020]](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-75-2048.jpg)
![Case Study: Conversational Picture-based DSSApple
[Sottocornola et al., 2020]](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-76-2048.jpg)
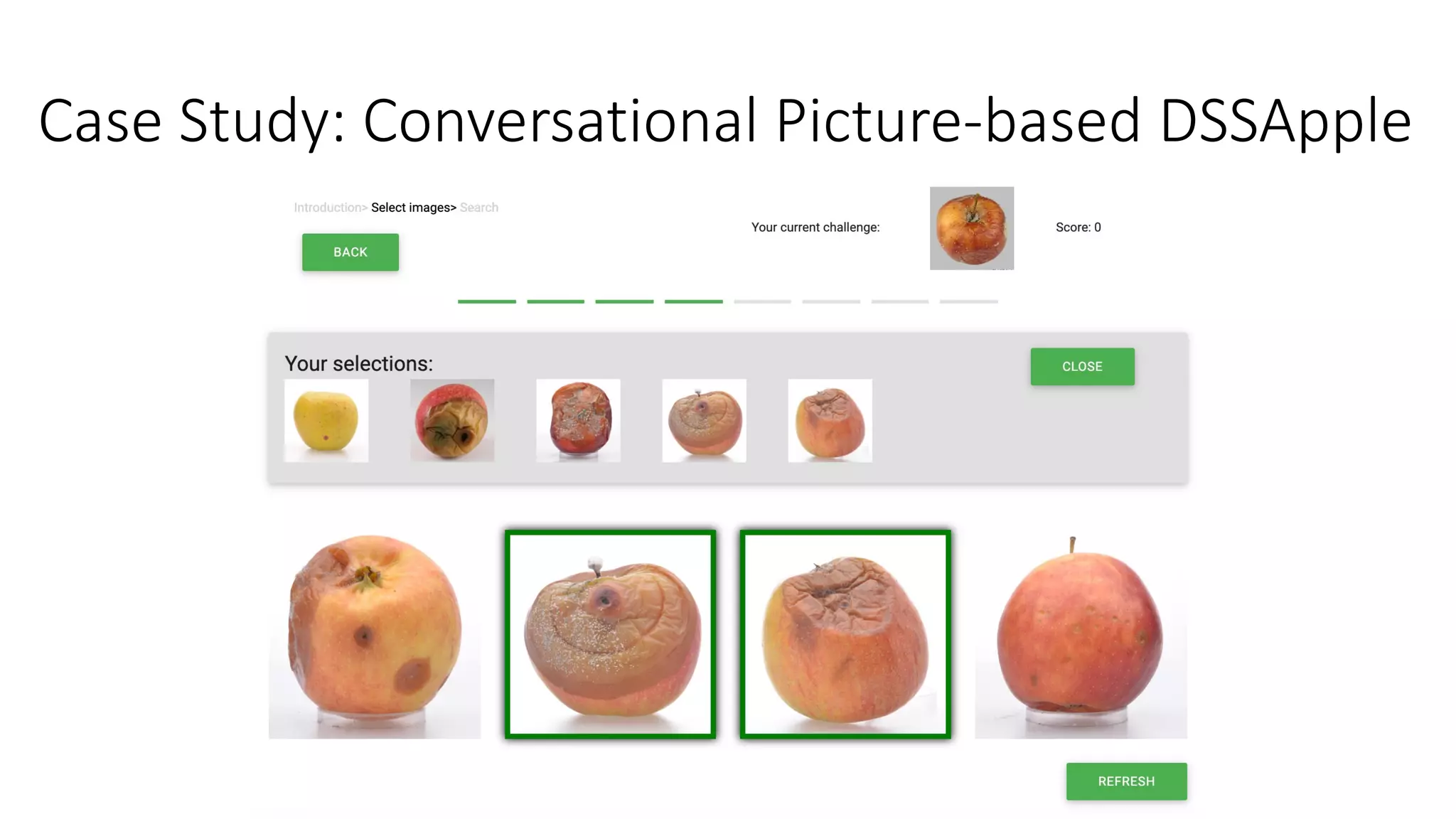
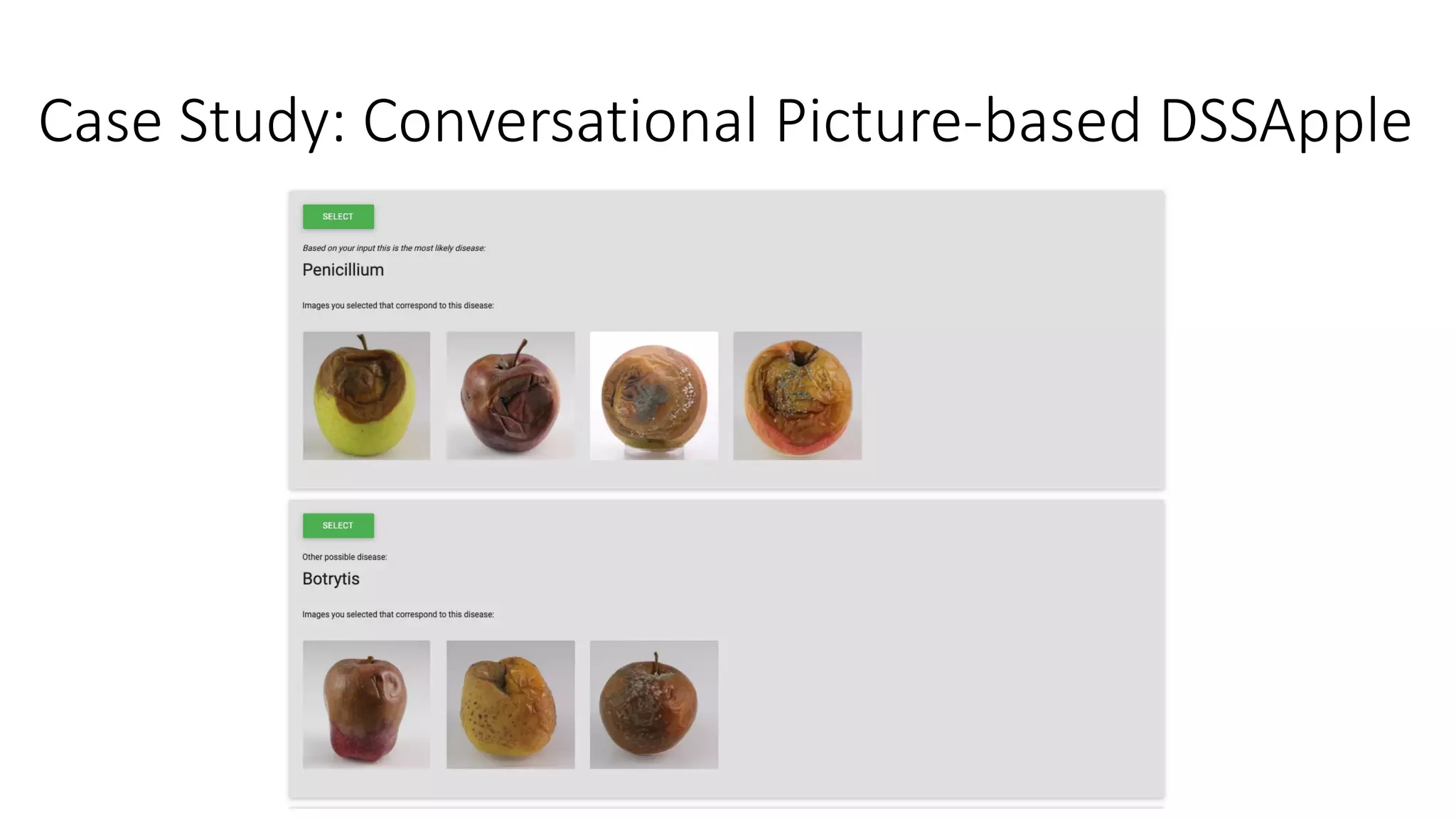


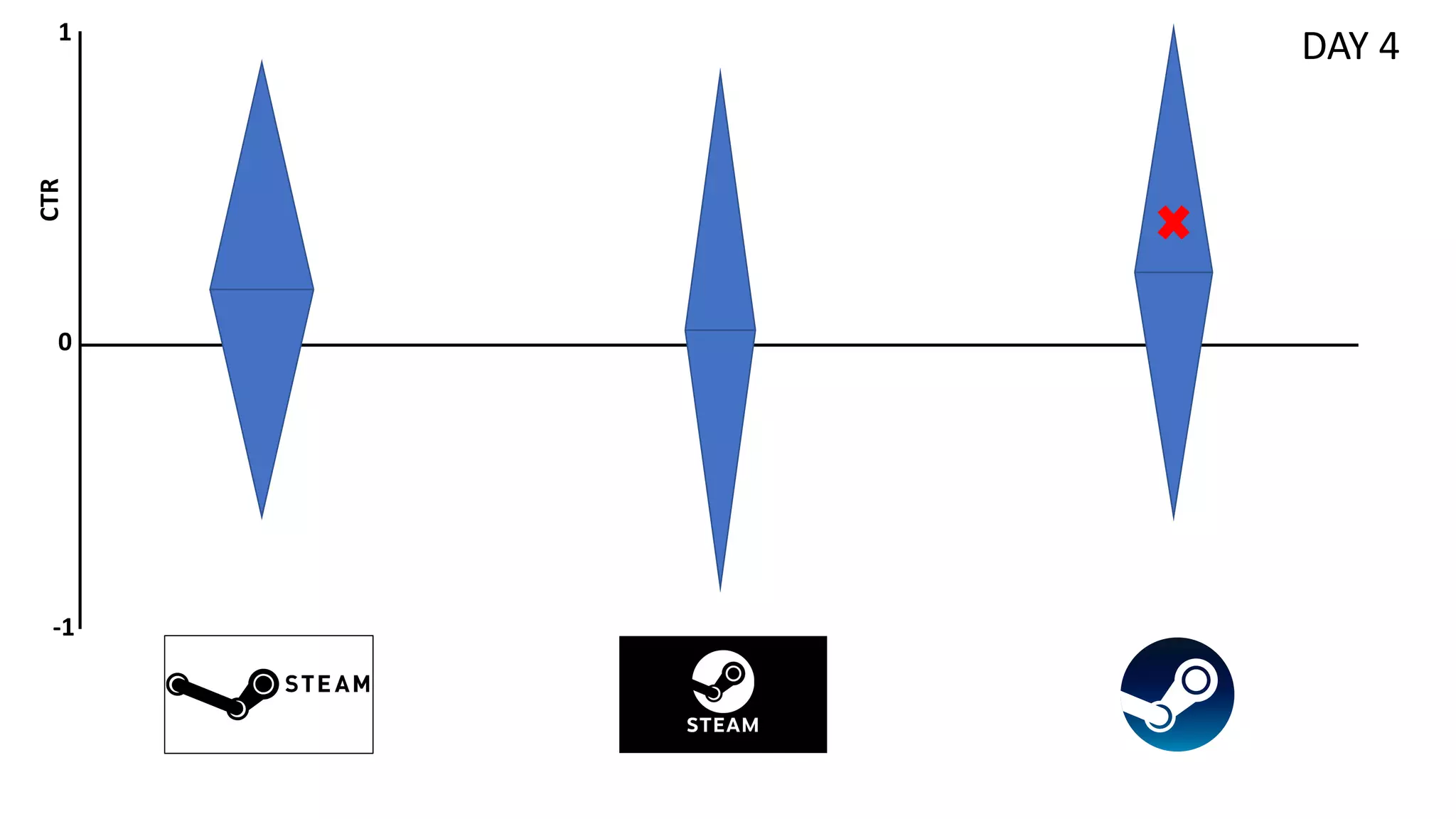
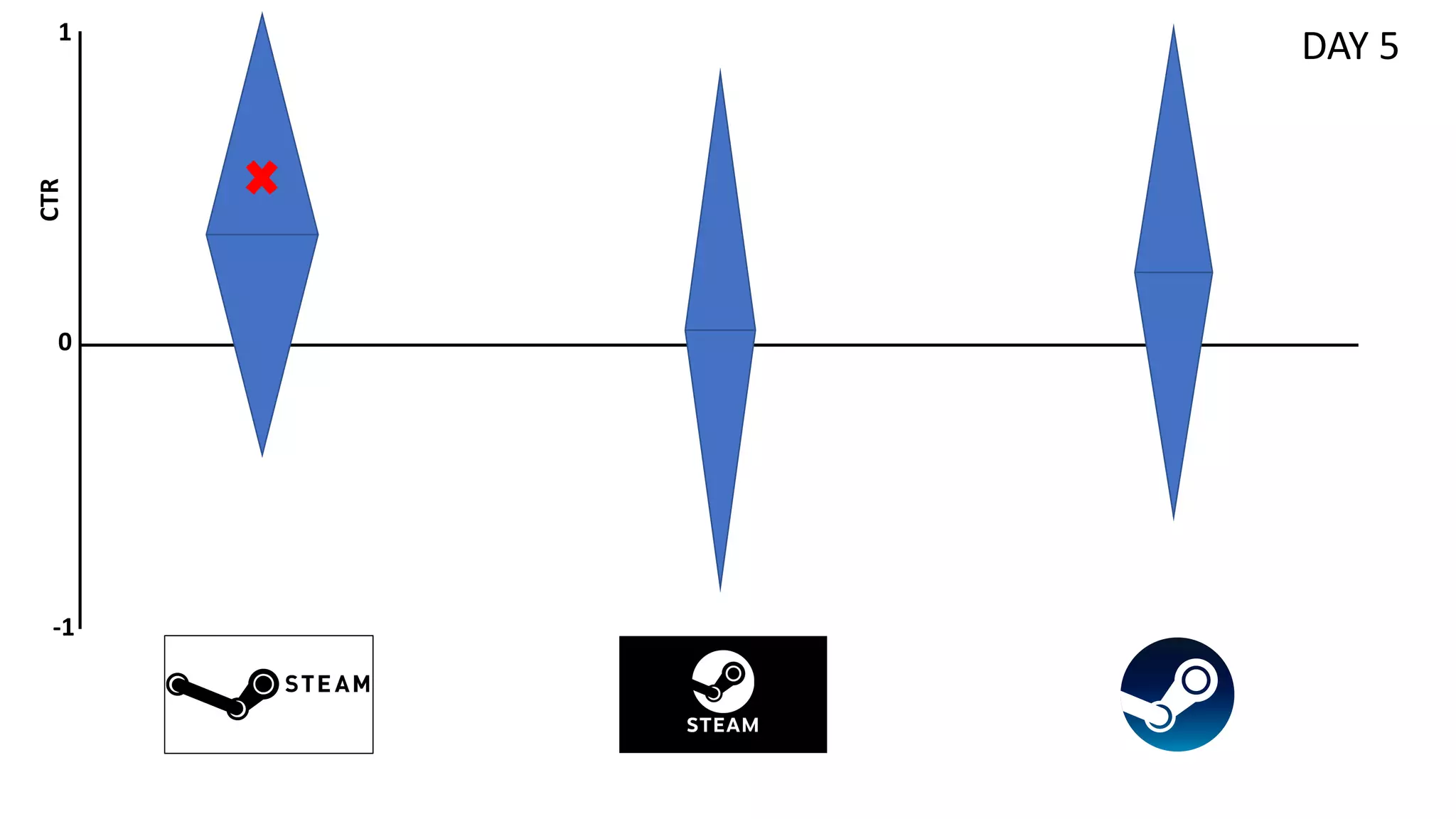
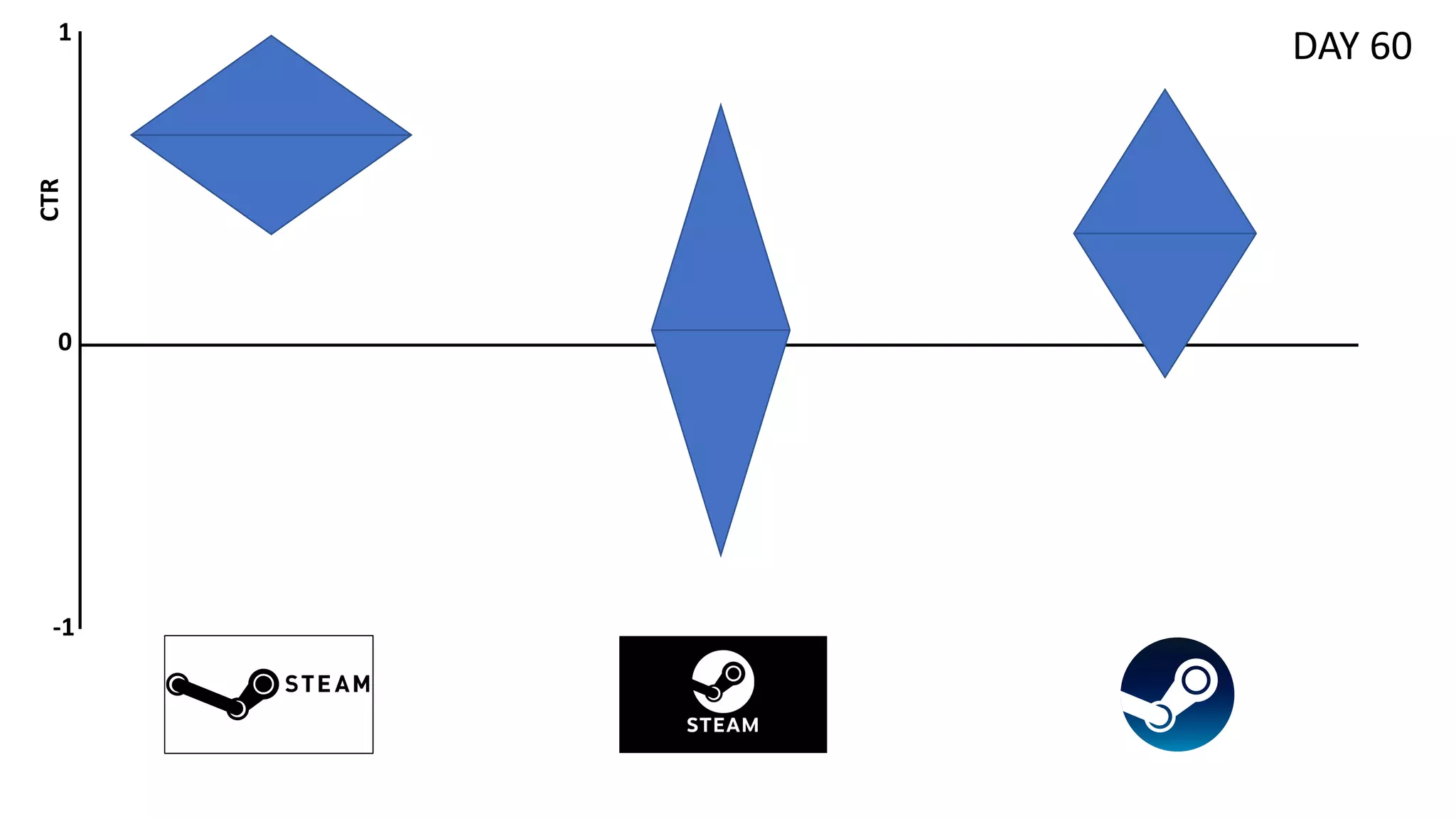
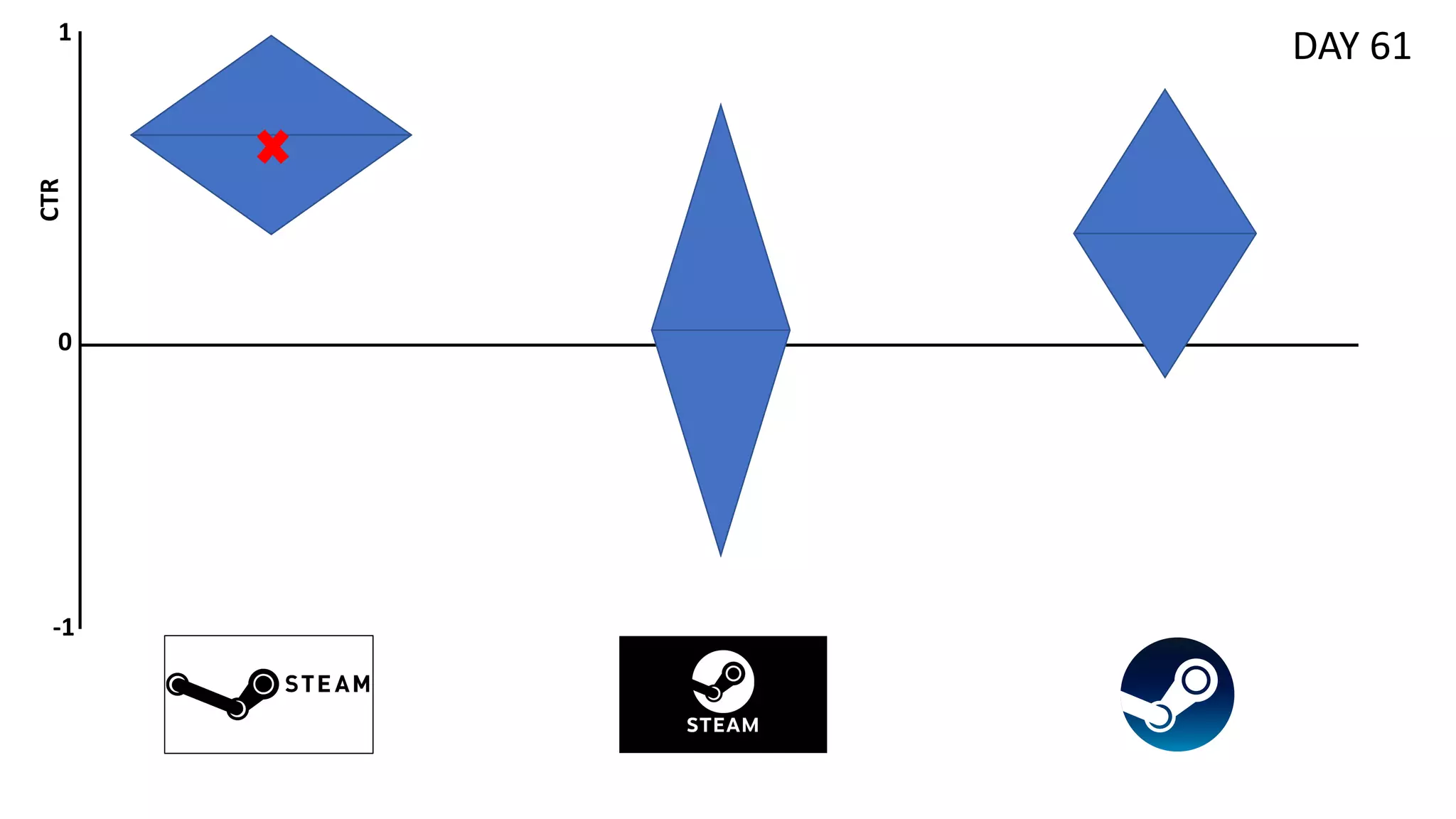
![Case Study: Conversational Picture-based DSSApple
• Gamified challenge with 163
BSc CS students performing
515 diagnoses
• 8 rounds with 4 images
• 5 diseases to be selected
• 4 different strategies of
reloading are implemented:
• Stratified Random (total
exploration)
• Greedy (total exploitation)
• Upper Confidence Bound
• Thompson sampling
[Sottocornola et al., 2021a]](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-81-2048.jpg)

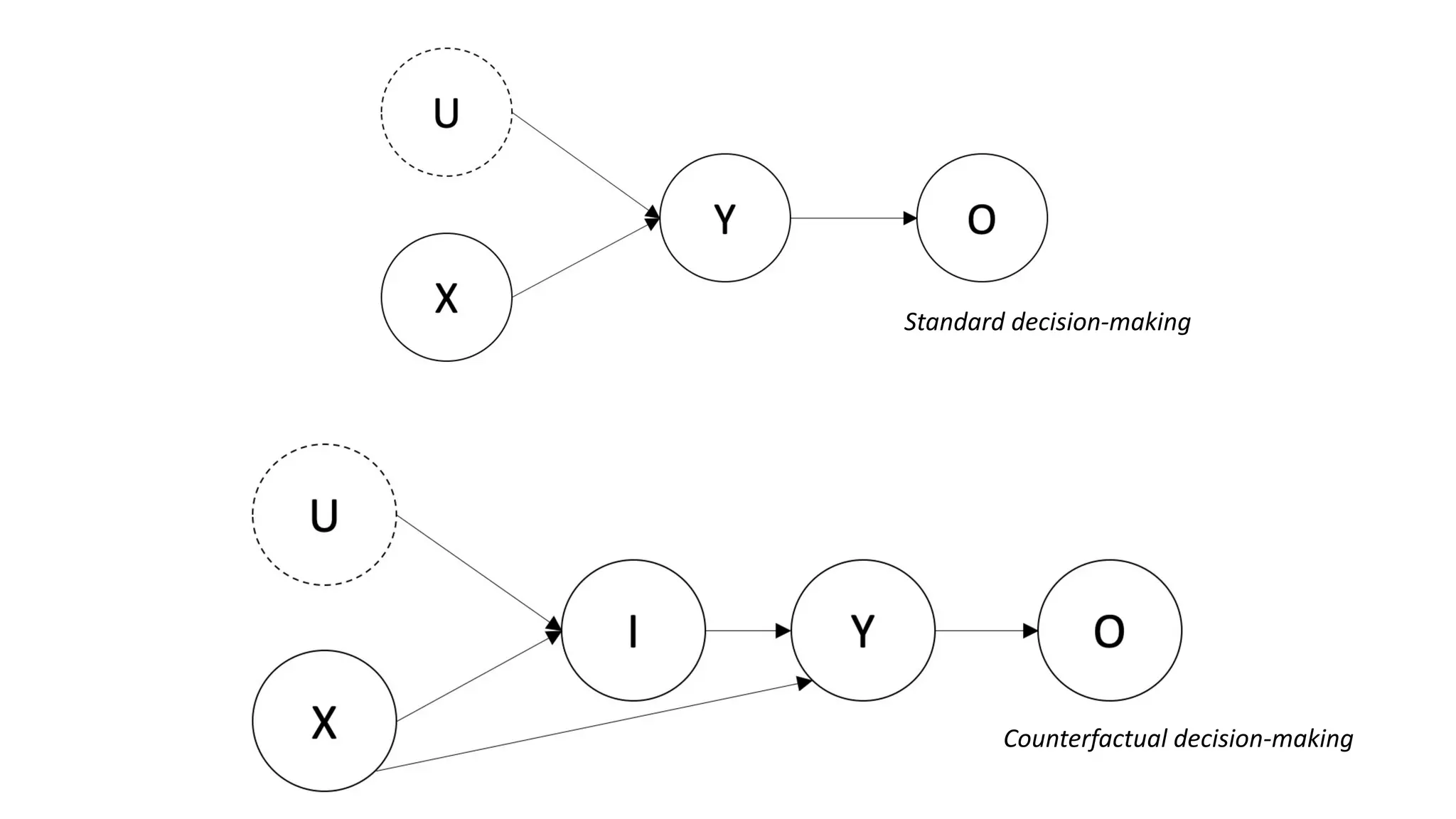
![Preliminaries
• Unobserved Confounders: factors U that simultaneously affect the
treatment/action (i.e., the arm selection) and the outcome (i.e., the bandit
reward), but are not accounted in the analysis
• Counterfactual: Let X be the set of player’s choice and Y the set of
outcomes. The counterfactual sentence “Y would be y (in situation U = u),
had X been x, given that X = x’ was observed” is interpreted as the causal
equation Yx(u) = y
[Bareinboim et al., 2015]](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-83-2048.jpg)
![Illustrative Example: Greedy Casino
• Two models of slot machines (M1 and M2), which learned the habits of the
players to adapt their payoff and increase casino outcome
• Player “natural” choice of the machine 𝑋 ∈ {𝑀2, 𝑀3} is a function of player
inebriation 𝐷 ∈ {0,1} and whether machine is blinking 𝐵 ∈ 0,1
• 𝑋 ← 𝑓" 𝐷, 𝐵 = 𝐷⨁𝐵
• Every player has equal chance to be inebriated, as well as every machine has equal
chance to be blinking 𝑃 𝐷 = 0 = 𝑃 𝐷 = 1 = 𝑃 𝐵 = 0 = 𝑃 𝐵 = 1 = 0.5
• Slot machines have full knowledge of the environment and adapt their payoff
according to player’s natural choice
[Bareinboim et al., 2015]
(a) Payoff rates and player natural choice (*), (b) Observational and Experimental expected reward](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-84-2048.jpg)
![Illustrative Example: Greedy Casino
• Greedy casino meets legal requirement of providing a payoff of 30% (under
randomized control trial), while in practice (under observational model) it is
paying just 15% of the times!
• Run a set of bandit/randomized experiments to improve the performance of
the players
[Bareinboim et al., 2015]](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-85-2048.jpg)
![MABUC Policy
• Exploit effect of the treatment of the treated (i.e., counterfactual) to include
unobserved confounders in the expected reward computation
• From average reward across arms (standard bandit) E(𝑌|𝑑𝑜 𝑋 = 𝑎 )
• To average reward by choosing and action w.r.t. natural choice (intuition)
E(𝑌456|𝑋 = 𝑎)
• Regret decision criterion: counterfactual nature of the inference, i.e.,
interrupt any reasoning agent before executing their choice, treat this as an
intention, compute the counterfactual expectation, then act.
[Bareinboim et al., 2015]](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-86-2048.jpg)
![Causal Thompson Sampling
[Bareinboim et al., 2015]](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-87-2048.jpg)
![Causal Thompson Sampling
[Bareinboim et al., 2015]](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-88-2048.jpg)
![Causal Thompson Sampling
[Bareinboim et al., 2015]](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-89-2048.jpg)
![Causal Thompson Sampling
[Bareinboim et al., 2015]](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-90-2048.jpg)
![Case Study: CF-CMAB to DSSApple Diagnosis
[Sottocornola et al., 2021b]](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-91-2048.jpg)
![• Idea: Leverage past user interactions (and decisions) with DSSApple
application to sequentially boost diagnosis accuracy including unobserved
confounders U
• Counterfactual Thompson Sampling (CF-TS) for contextual diagnosis: linear
CMAB (with TS policy) for “disease classification”, enhanced with
counterfactual computation on user decision
• Context: User feedback X provided to the system during a session of
diagnosis (i.e., images clicked as similar)
• Counterfactual: Regret decision criterion, i.e., interrupt users as they
execute their decision (i.e., diagnosis), treat this as an intuition I and
compute counterfactual decision Y
Counterfactual Contextual MAB
[Sottocornola et al., 2021b]](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-92-2048.jpg)
![CF-TS Algorithm
• At time t, play arm
• Expected reward is computed as
• In causal terms, this corresponds to optimize the expected outcome 𝑂 for
selecting arm 𝑌 = 𝑦, given the contextual information 𝑋 = 𝑥𝑡 and the
intuition of the user towards arm 𝐼 = 𝑖𝑡
• “What have been the expected reward had I pull arm 𝑦 given that I am
about to pull arm 𝑖𝑡 ?”
[Sottocornola et al., 2021b]](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-94-2048.jpg)
![CF-TS Algorithm
[Sottocornola et al., 2021b]](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-95-2048.jpg)
![CF-TS Algorithm
[Sottocornola et al., 2021b]](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-96-2048.jpg)
![Case Study: DSSApple Diagnosis Results
[Sottocornola et al., 2021b]
Cumulative reward for the image-based context (a) and the similarity-based context (b)](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-97-2048.jpg)
![Case Study: DSSApple Diagnosis Results
[Sottocornola et al., 2021b]
Open-source code @ https://github.com/endlessinertia/causal-contextual-bandits](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-98-2048.jpg)
![References
• [Auer et al., 2002] Auer, P., Cesa-Bianchi, N., & Fischer, P. (2002). Finite-time analysis of the multiarmed bandit problem. Machine
learning, 47(2), 235-256.
• [Shahriari et al., 2015] Shahriari, B., Swersky, K., Wang, Z., Adams, R. P., & De Freitas, N. (2015). Taking the human out of the loop: A
review of Bayesian optimization. Proceedings of the IEEE, 104(1), 148-175.
• [Jeunen & Goethals, 2021] Jeunen, O., & Goethals, B. (2021). Pessimistic reward models for off-policy learning in recommendation.
In Fifteenth ACM Conference on Recommender Systems (pp. 63-74).
• [Raj & Kalyani, 2017] Raj, V., & Kalyani, S. (2017). Taming non-stationary bandits: A Bayesian approach. arXiv preprint
arXiv:1707.09727.
• [Trovò et al., 2020] Trovò, F., Paladino, S., Restelli, M., & Gatti, N. (2020). Sliding-window thompson sampling for non-stationary
settings. Journal of Artificial Intelligence Research, 68, 311-364.
• [Cavenaghi et al., 2021] Cavenaghi, E., Sottocornola, G., Stella, F., & Zanker, M. (2021). Non Stationary Multi-Armed Bandit:
Empirical Evaluation of a New Concept Drift-Aware Algorithm. Entropy, 23(3), 380.
• [Liu et al., 2018] Liu, F., Lee, J., & Shroff, N. (2018). A change-detection based framework for piecewise-stationary multi-armed
bandit problem. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 32, No. 1).
• [Bifet & Gavalda, 2007] Bifet, A., & Gavalda, R. (2007). Learning from time-changing data with adaptive windowing. In Proceedings
of the 2007 SIAM international conference on data mining (pp. 443-448). Society for Industrial and Applied Mathematics.
• [Alves et al., 2021] Alves, R., Ledent, A., & Kloft, M. (2021). Burst-induced Multi-Armed Bandit for Learning Recommendation.
In Fifteenth ACM Conference on Recommender Systems (pp. 292-301).](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-99-2048.jpg)
![References
• [Agrawal & Goyal, 2013] Agrawal, S., & Goyal, N. (2013). Thompson sampling for contextual bandits with linear payoffs.
In International Conference on Machine Learning (pp. 127-135). PMLR.
• [Li et al., 2010] Li, L., Chu, W., Langford, J., & Schapire, R. E. (2010). A contextual-bandit approach to personalized news article
recommendation. In Proceedings of the 19th international conference on World wide web (pp. 661-670).
• [Sottocornola et al., 2020] Sottocornola, G., Nocker, M., Stella, F., & Zanker, M. (2020). Contextual multi-armed bandit strategies for
diagnosing post-harvest diseases of apple. In Proceedings of the 25th International Conference on Intelligent User Interfaces (pp.
83-87).
• [Sottocornola et al., 2021a] Sottocornola, G., Baric, S., Nocker, M., Stella, F., & Zanker, M. (2021). Picture-based and conversational
decision support to diagnose post-harvest apple diseases. Expert Systems with Applications, 116052.
• [Bareinboim et al., 2015] Bareinboim, E., Forney, A., & Pearl, J. (2015). Bandits with unobserved confounders: A causal
approach. Advances in Neural Information Processing Systems, 28, 1342-1350.
• [Sottocornola et al., 2021b] Sottocornola, G., Stella, F., & Zanker, M. (2021). Counterfactual Contextual Multi-Armed Bandit: a Real-
World Application to Diagnose Apple Diseases. arXiv preprint arXiv:2102.04214.
• [Žliobaitė et al., 2016] Žliobaitė, I., Pechenizkiy, M., & Gama, J. (2016). An overview of concept drift applications. Big data analysis:
new algorithms for a new society, 91-114.](https://image.slidesharecdn.com/multi-armed-bandit-tutorial-211213195154/75/Multi-Armed-Bandit-an-algorithmic-perspective-100-2048.jpg)




























![[DSC Europe 25] Vid Stimac - Policy Parsimony: Between Oversimplifying and Ov...](https://cdn.slidesharecdn.com/ss_thumbnails/eqlepagzqp2rhg3gbluh-dsc-stimac-251120-251205090438-059e7f54-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Jim Sterne - Adopting Generative AI Capabilities Into the Ent...](https://cdn.slidesharecdn.com/ss_thumbnails/sxhpofuorcagxsaulkmt-3-251204082258-7e66bc48-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Andy Cotgreave - Nothing is new in analytics.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/mba4vzcurvoh5lfrd5zw-6-251205194645-341bbbbe-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Dragan Vucic - Building the Learning Organization - How AI Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/8brigo2sbu6qur6gxrra-7-251205085715-6ae07d24-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Dusan Jovicic - AI Story: From on-prem to cloud and back agai...](https://cdn.slidesharecdn.com/ss_thumbnails/8kp49m6uq22ifnbwhfnk-2-251205085715-964d11a6-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Max Talanov - Non digital NNs.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/wif8tr3gtua74qvtopke-non-digital-nns-251205090438-26b0eea6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Goran Obradovic - The Rise of Sovereign AI: Building the Regi...](https://cdn.slidesharecdn.com/ss_thumbnails/7nw2xxixrxqdxvrb5wca-6-251205085714-ab09a2ac-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)

