Download as PDF, PPTX











![EPOCH-GREEDY [1]
Step 1: For the first N pulls
Evenly pull all the arms, keeping track of the
number of pulls & wins per arm
Step 2: For the remaining M pulls
Choose the arm the the highest expected
reward
Arm 1: {trials: 100, wins: 2}
Arm 2: {trials: 100, wins: 21}
Arm 3: {trials: 100, wins: 17}
Arm 1: 2/100 = 0.02
Arm 2: 21/100 = 0.21
Arm 3: 17/100 = 0.17
Explore
Exploit
[1]: http://hunch.net/~jl/projects/interactive/sidebandits/bandit.pdf](https://image.slidesharecdn.com/bandit-algorithms-li-170511190106/75/Bandit-Algorithms-17-2048.jpg)
![EPSILON-GREEDY/Ε-GREEDY [2]
Choose a value for the hyperparameter ε
Loop forever
With probability ε:
Choose an arm uniformly at random, keep track of trials and wins
With probability 1-ε:
Choose the arm the the highest expected reward
Explore
Exploit
[2]: people.inf.elte.hu/lorincz/Files/RL_2006/SuttonBook.pdf](https://image.slidesharecdn.com/bandit-algorithms-li-170511190106/75/Bandit-Algorithms-18-2048.jpg)









![…BUT CONTEXTUAL BANDITS
ARE THE HOLY GRAIL
The the contextual bandit setting, once we pull an arm and receive a reward,
we also get to see a context vector associated with the reward. The
objective is now to maximise the expected reward over time given the
context at each time step.
Solving this problem gives us a higher reward over time in situations where
the globally best arm isn’t always the best arm.
Example algorithm: Thompson Sampling with Linear Payoffs [3]
[3]: https://arxiv.org/abs/1209.3352](https://image.slidesharecdn.com/bandit-algorithms-li-170511190106/75/Bandit-Algorithms-32-2048.jpg)
![…ACTUALLY, ADVERSARIAL
CONTEXTUAL BANDITS ARE THE
HOLY GRAIL
Until now, we’ve assumed that each one-armed bandit gives a $100 reward
according to some unknown probability P. In real-world scenarios, the world
rarely behaves this well. Instead of a simple dice roll, the bandit may pay out
differently depending on the day/hour/amount of money in the machine. It
works as an adversary of sorts.
A bandit algorithm that is capable of dealing with changes in payoff
structures in a reasonable amount of time tend to work better than
stochastic bandits in real-world settings.
Example algorithm: EXP4 (a.k.a the “Monster” algorithm) [4]
[4]: https://arxiv.org/abs/1002.4058](https://image.slidesharecdn.com/bandit-algorithms-li-170511190106/75/Bandit-Algorithms-33-2048.jpg)










This document discusses bandit algorithms and their applications. It begins with an overview of multi-armed bandit problems and explores various algorithms to solve them, including naive, epsilon-greedy, and Thompson sampling algorithms. Thompson sampling is shown to have logarithmic regret compared to linear regret for other algorithms. The document then discusses contextual bandits, which incorporate context into the problem to select the best arm given context, and adversarial contextual bandits, where payoffs may change. Real-world applications of bandits include medical treatments, testing, optimization, and recommendations. Contextual bandits can be implemented using APIs, databases, and services. Bandit algorithms can solve many problems modeled as games.
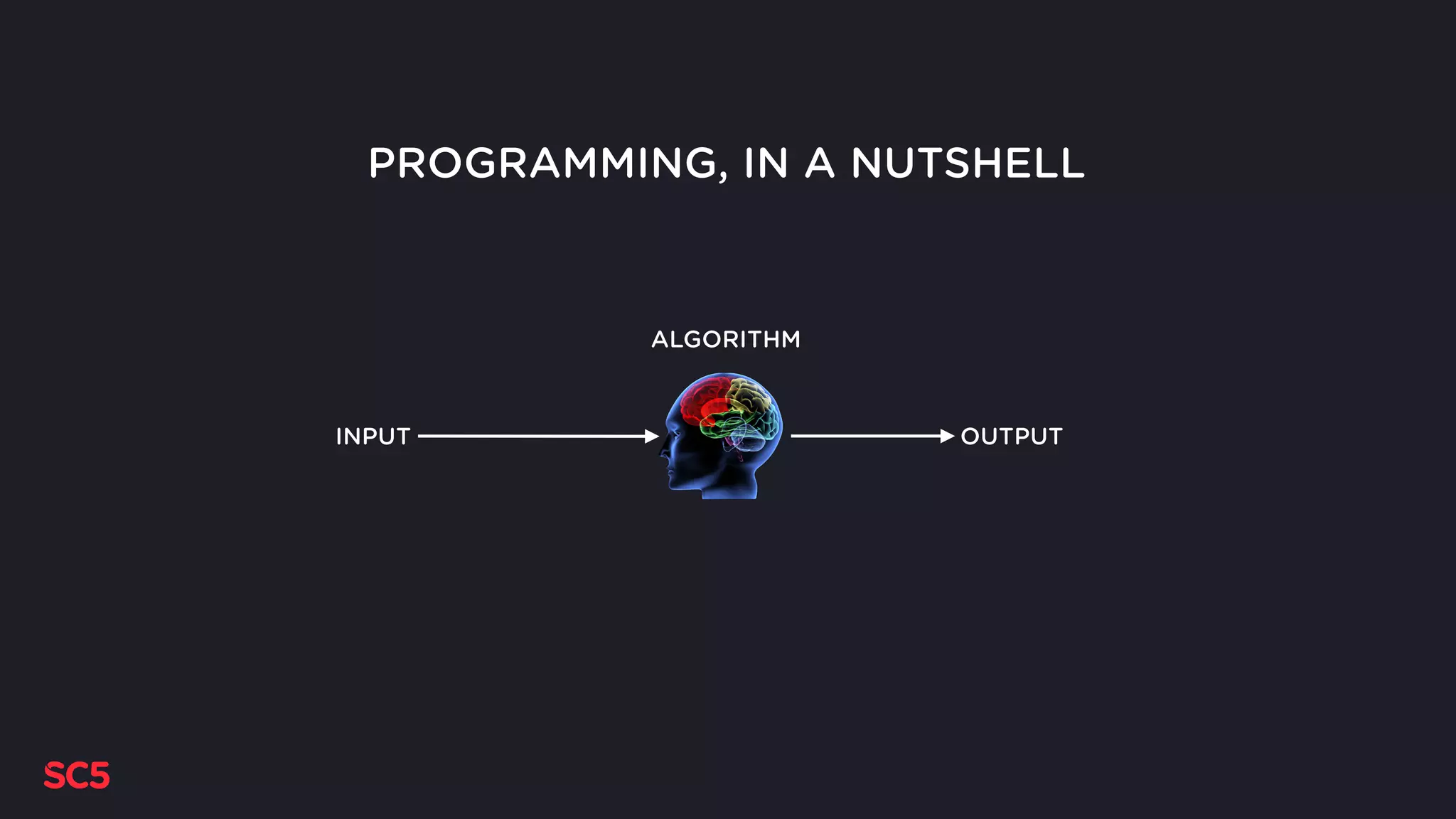
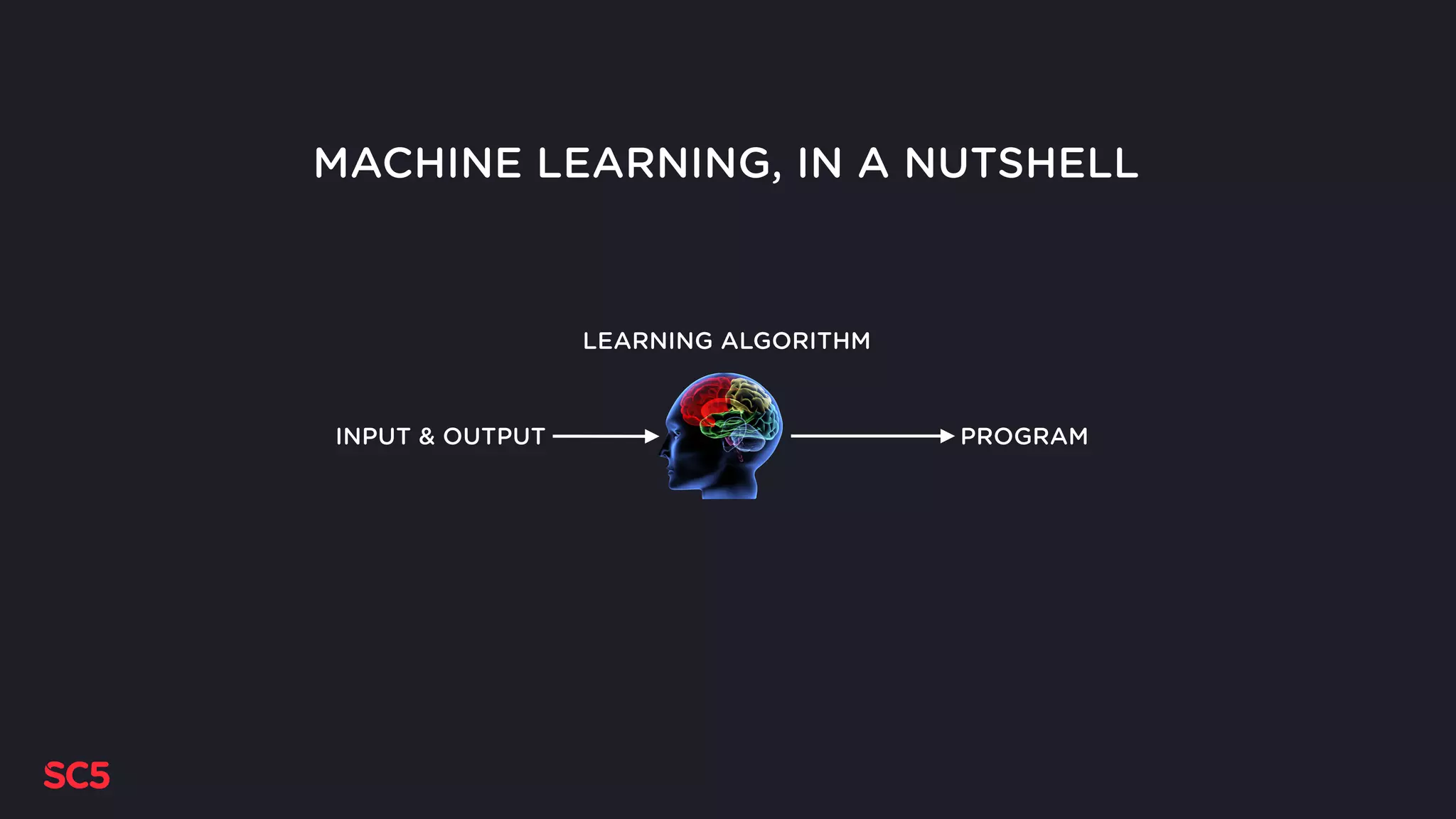
Introduction to the presentation by Max Pagels on bandit algorithms, basics of programming and machine learning.
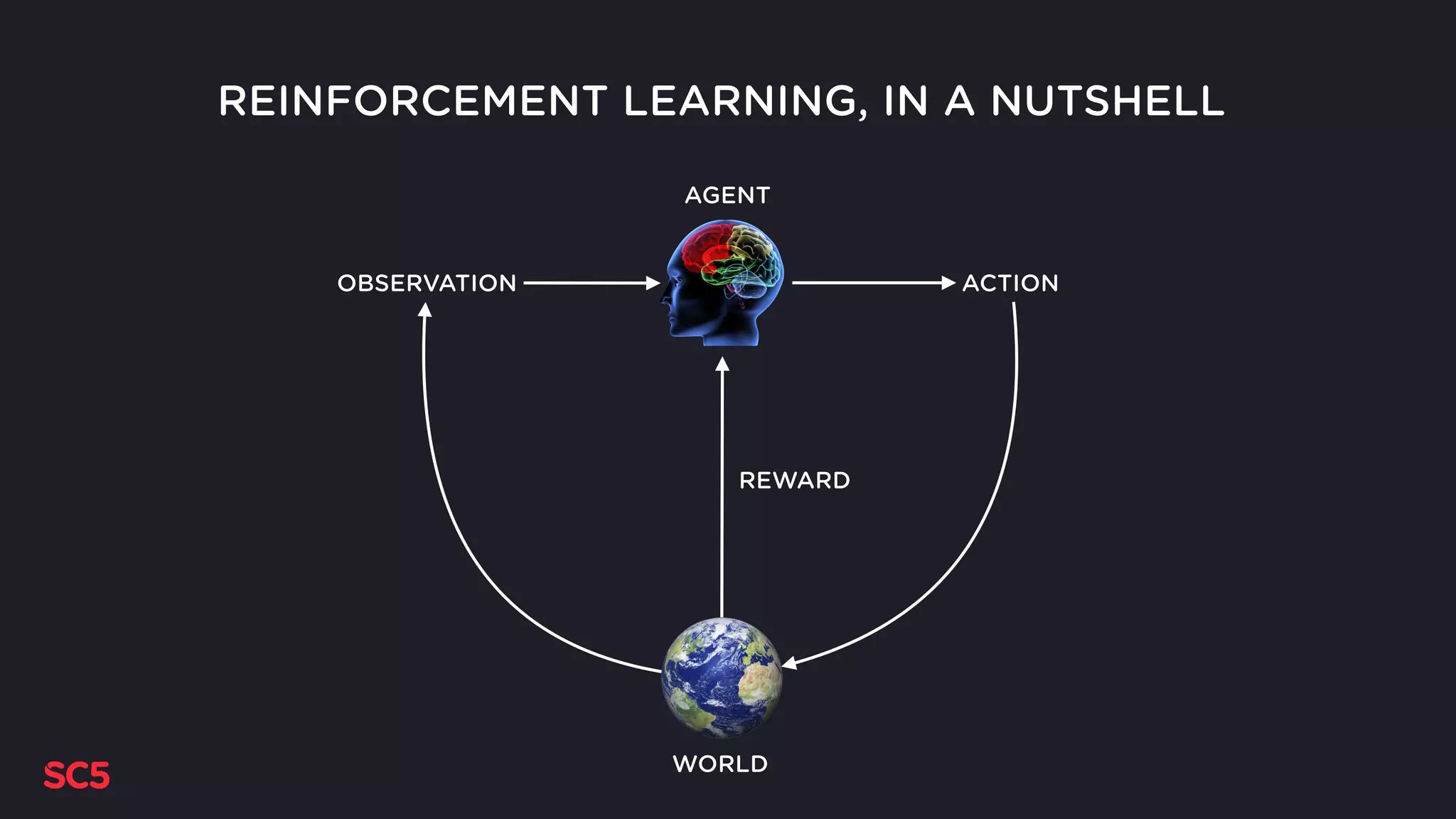
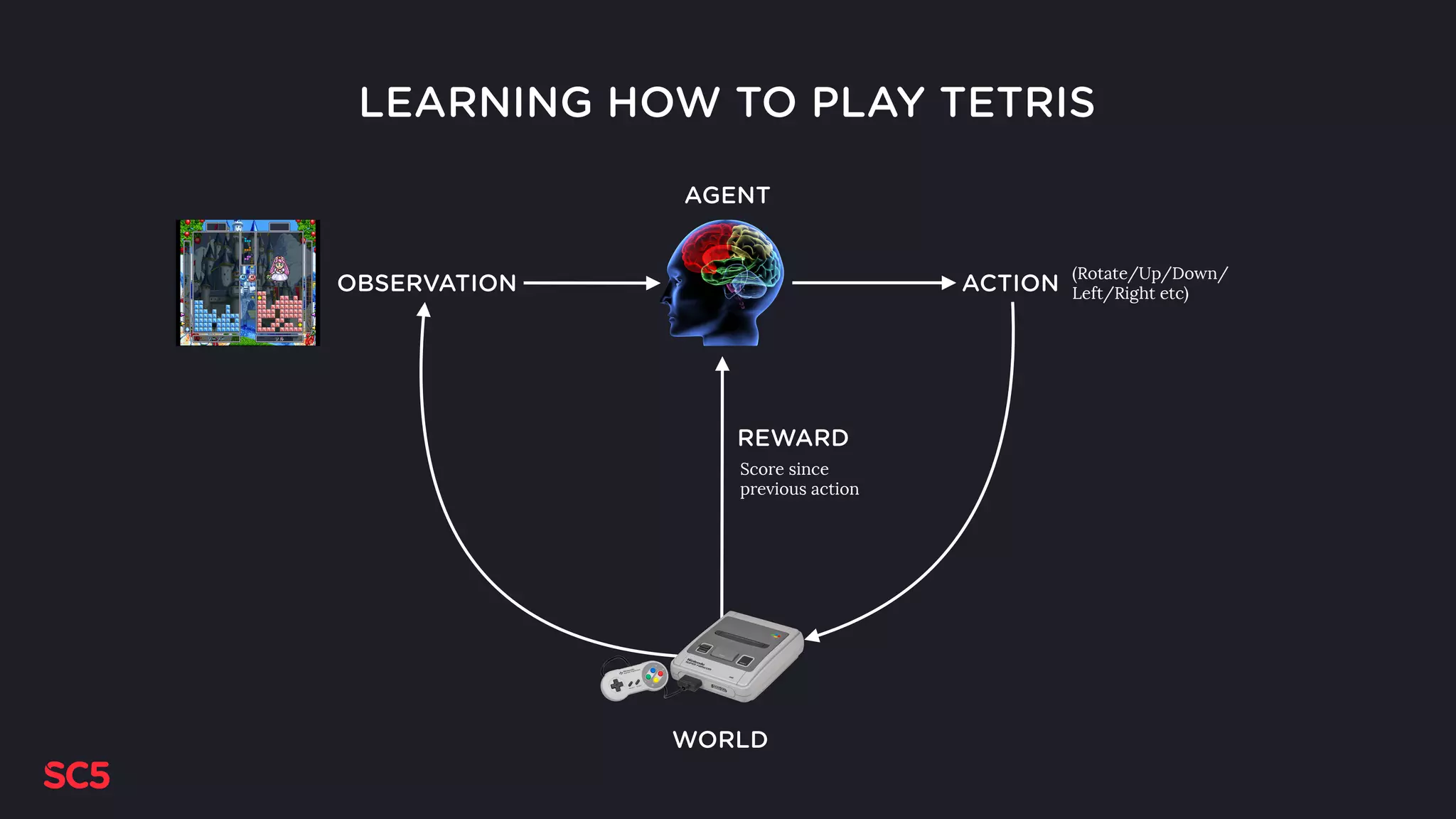
Defines reinforcement learning concepts, using Tetris as an example for agent, actions, rewards, and observations.
Illustrates the concept of multi-armed bandits, focusing on partial information, exploration vs. exploitation.
Describes a naïve algorithm for solving bandit problems, including trials, pulls, rewards, and expected returns.
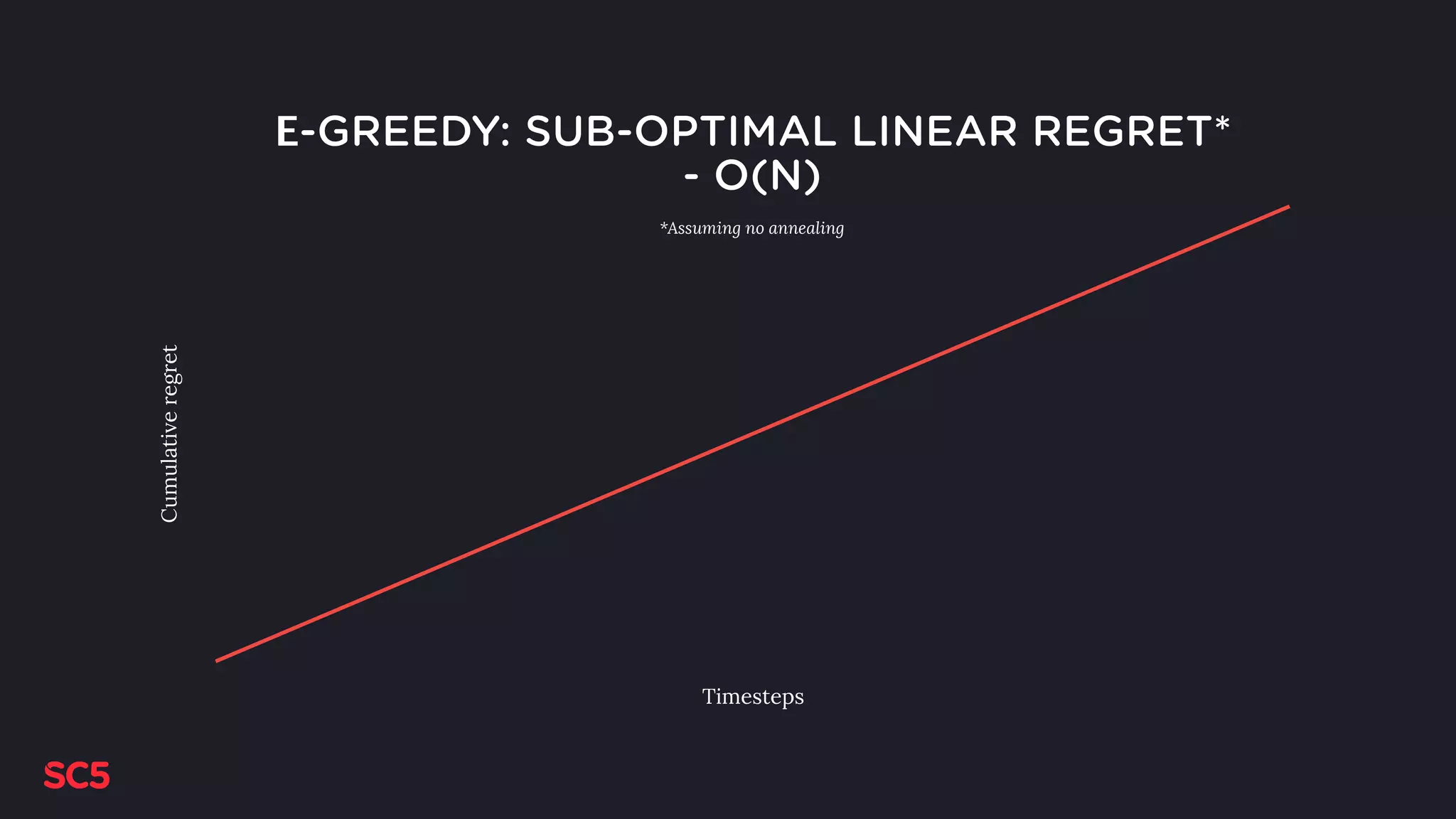
Details on Epoch-Greedy and Epsilon-Greedy algorithms, exploring their decision-making strategies and regret behavior.
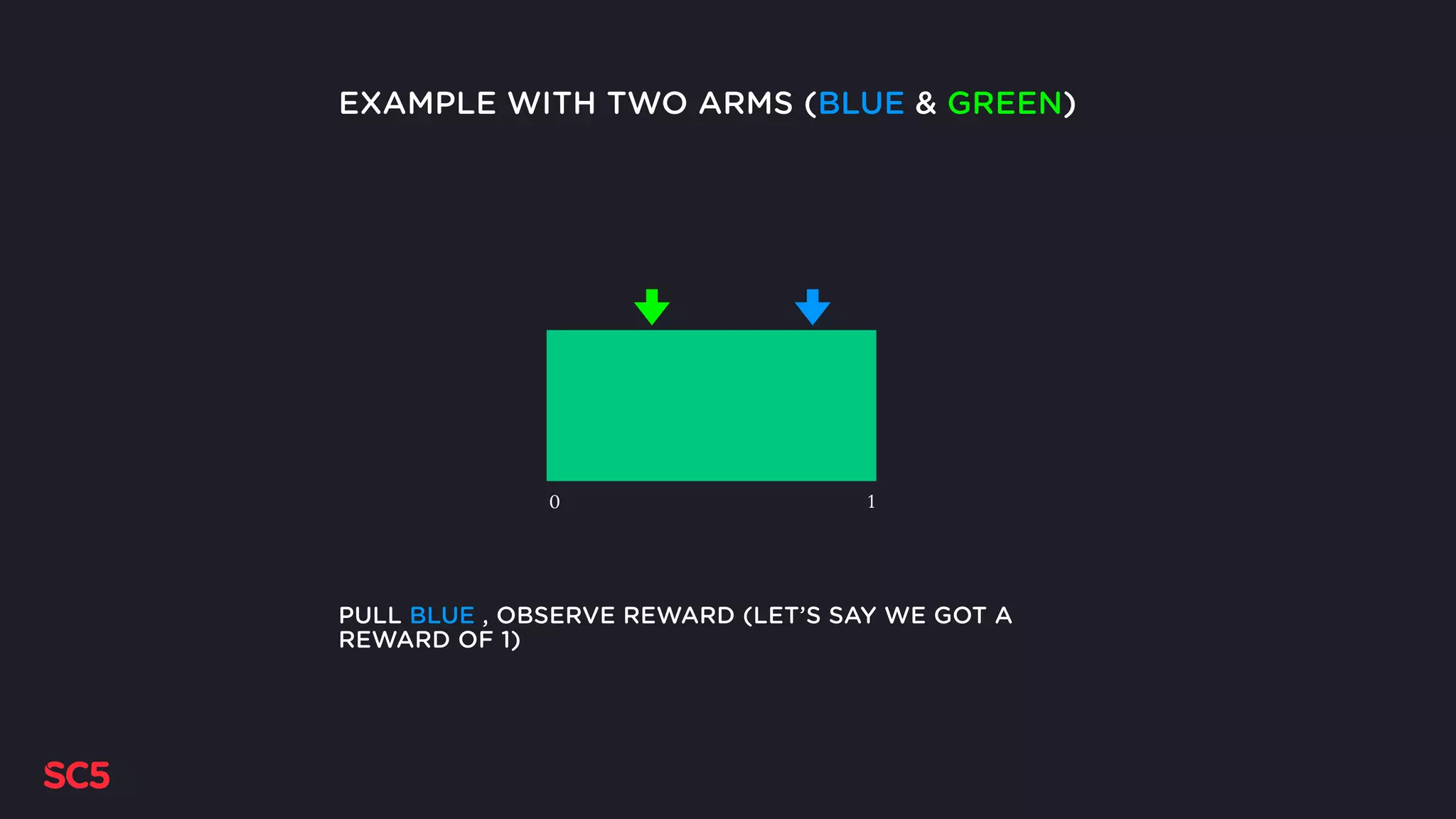
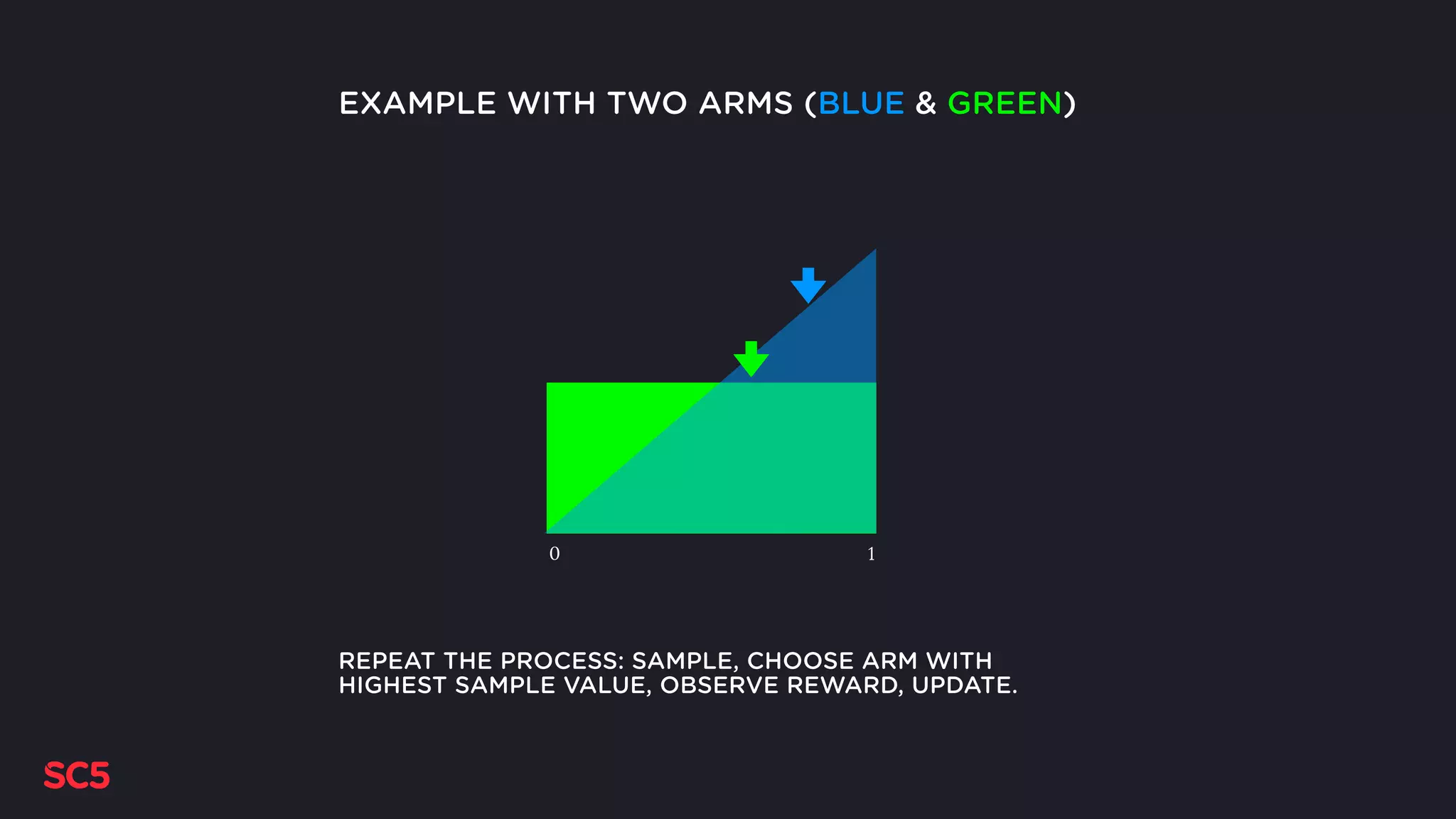
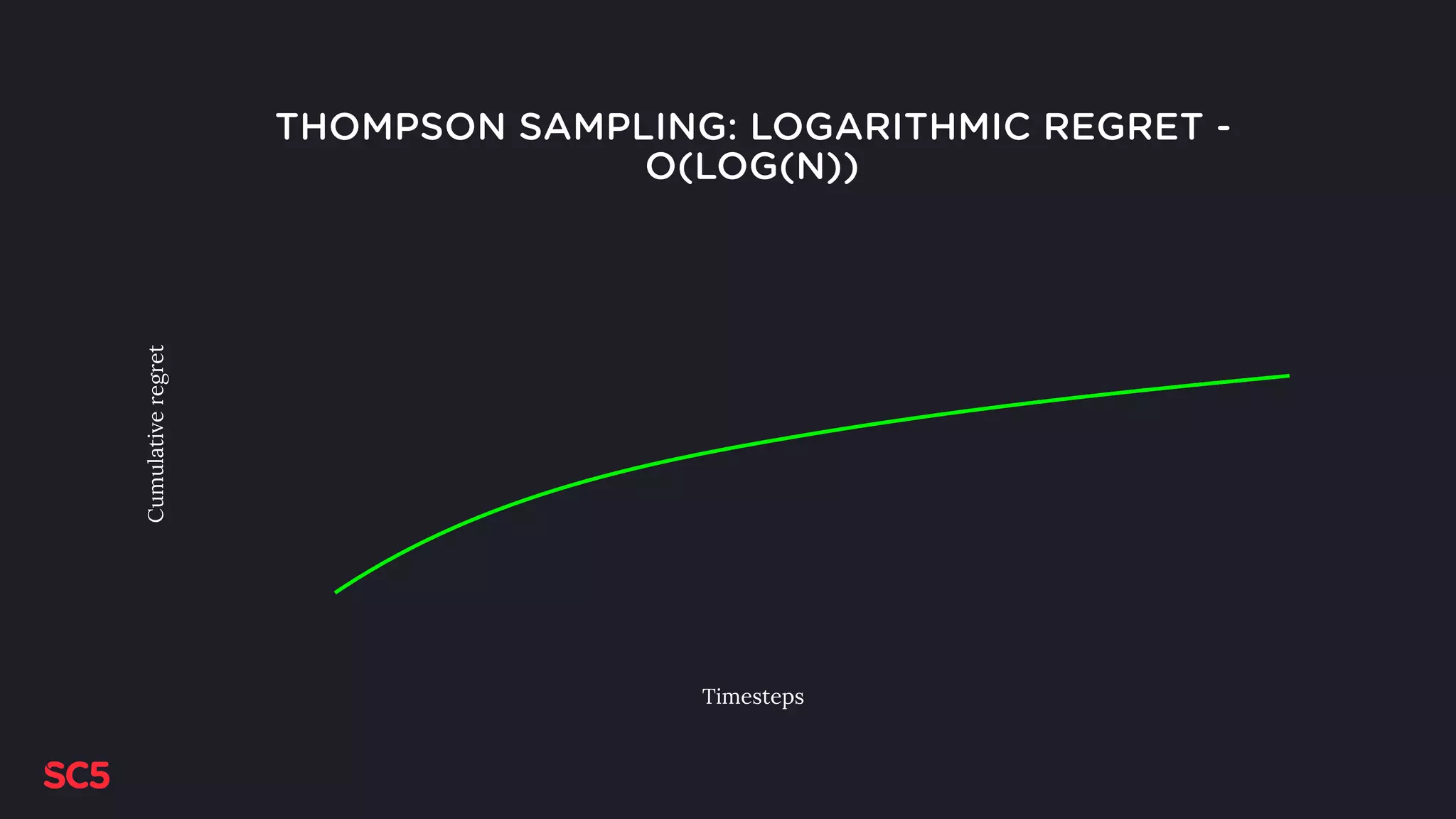
Explains Thompson Sampling, showcasing its advantages with examples and how it updates distributions over time.
Discusses the difference between standard multi-armed bandits and contextual bandits, including adversarial contexts.
Emphasizes the complexity of contemporary contextual bandit algorithms and various practical applications in real life.
Gives tips for implementing contextual bandits and introduces new Azure services, concluding with a call for questions.















































































