Downloaded 11 times





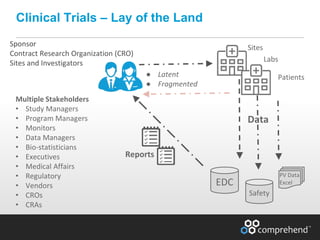


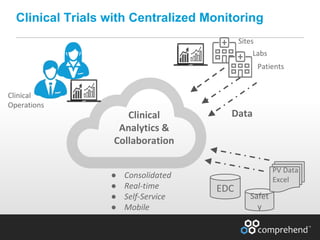






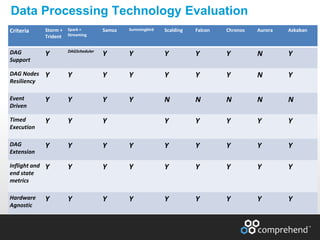

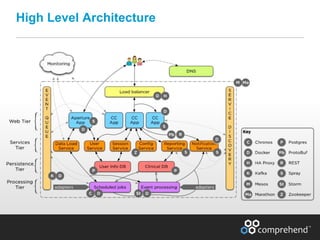

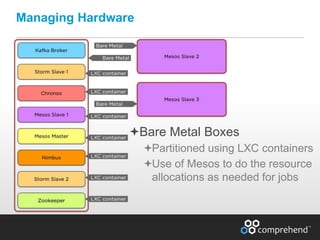



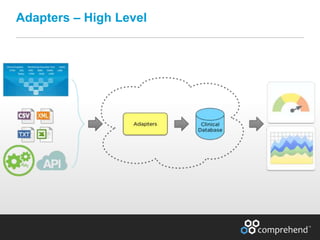
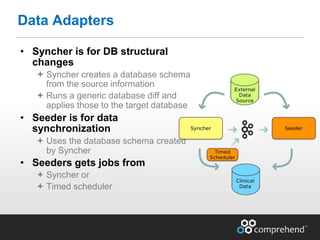
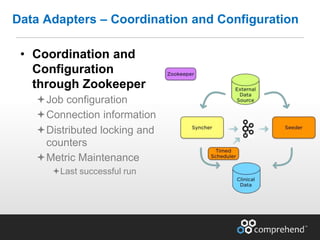
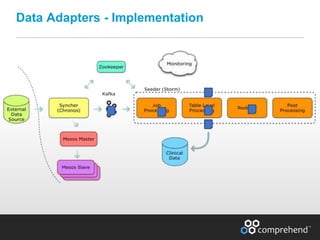












The document discusses redefining ETL pipelines using Apache technologies to enhance decision-making in clinical trials, covering business and technical requirements, technology evaluation, and high-level architecture. It explores challenges, implementation strategies, and future enhancements, emphasizing the need for real-time data processing, fault tolerance, and adaptive deployments. The presentation highlights various Apache technologies and design principles that can facilitate more efficient clinical data management and integration.



























































































