Download to read offline


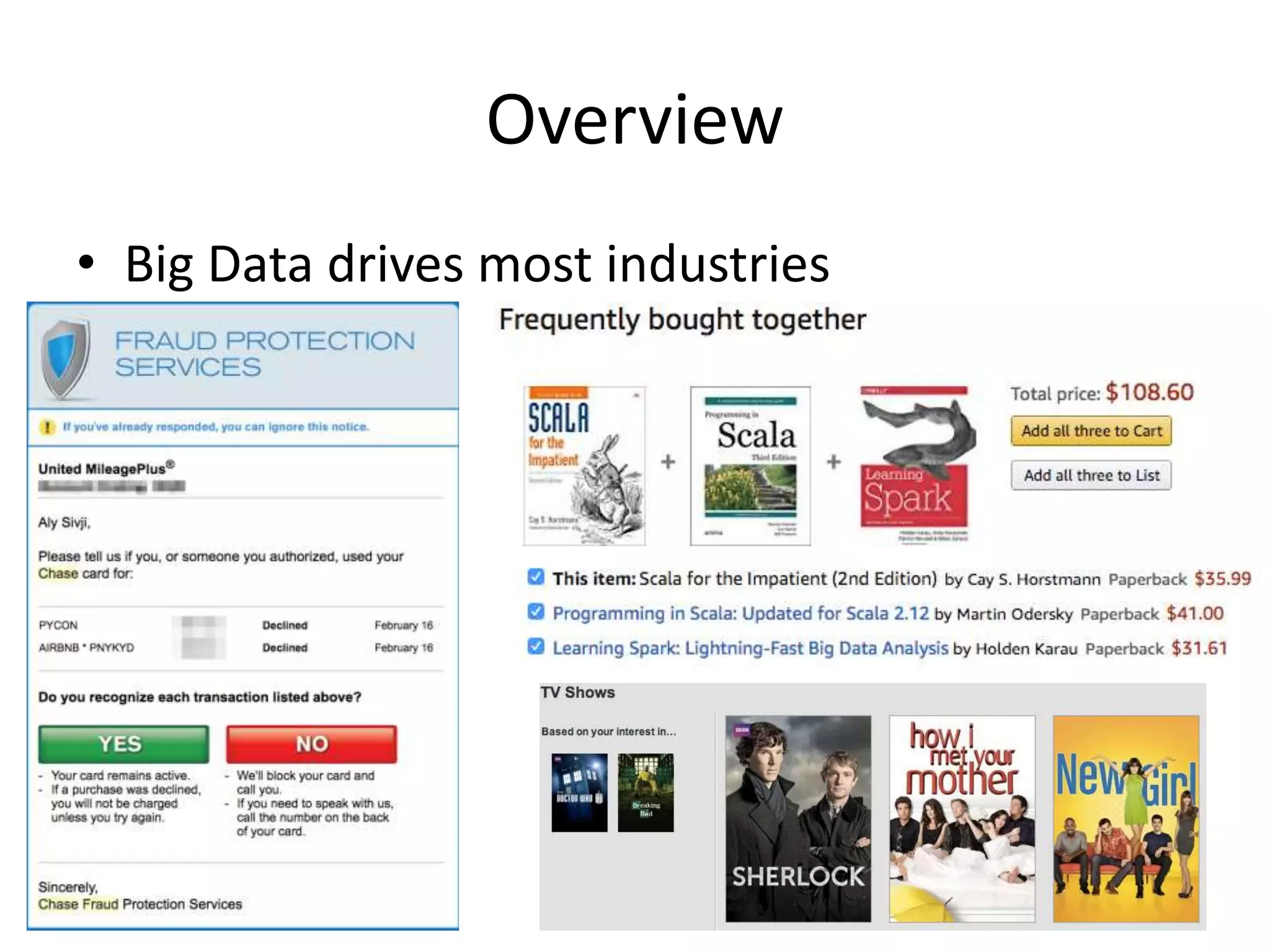

















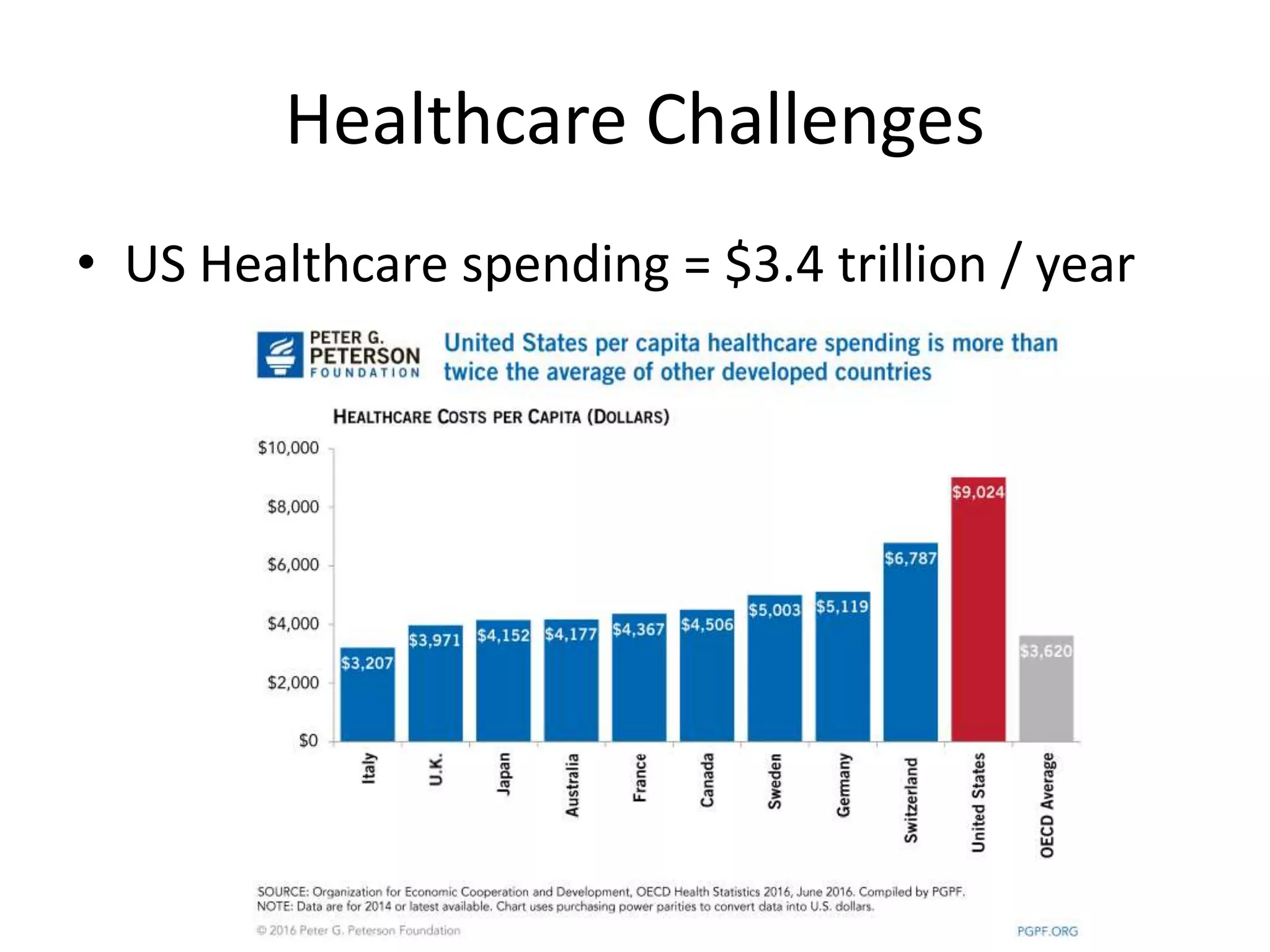
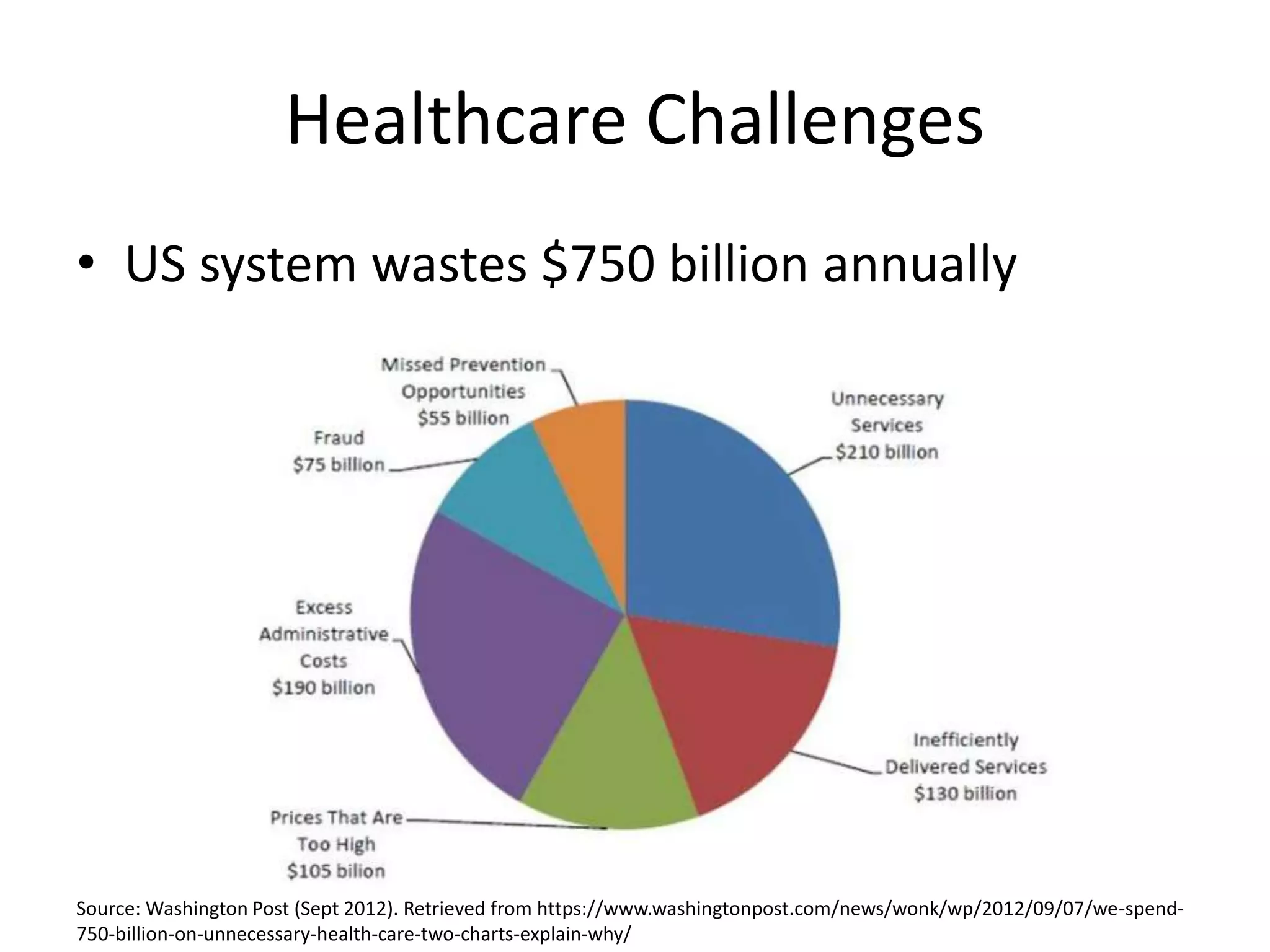


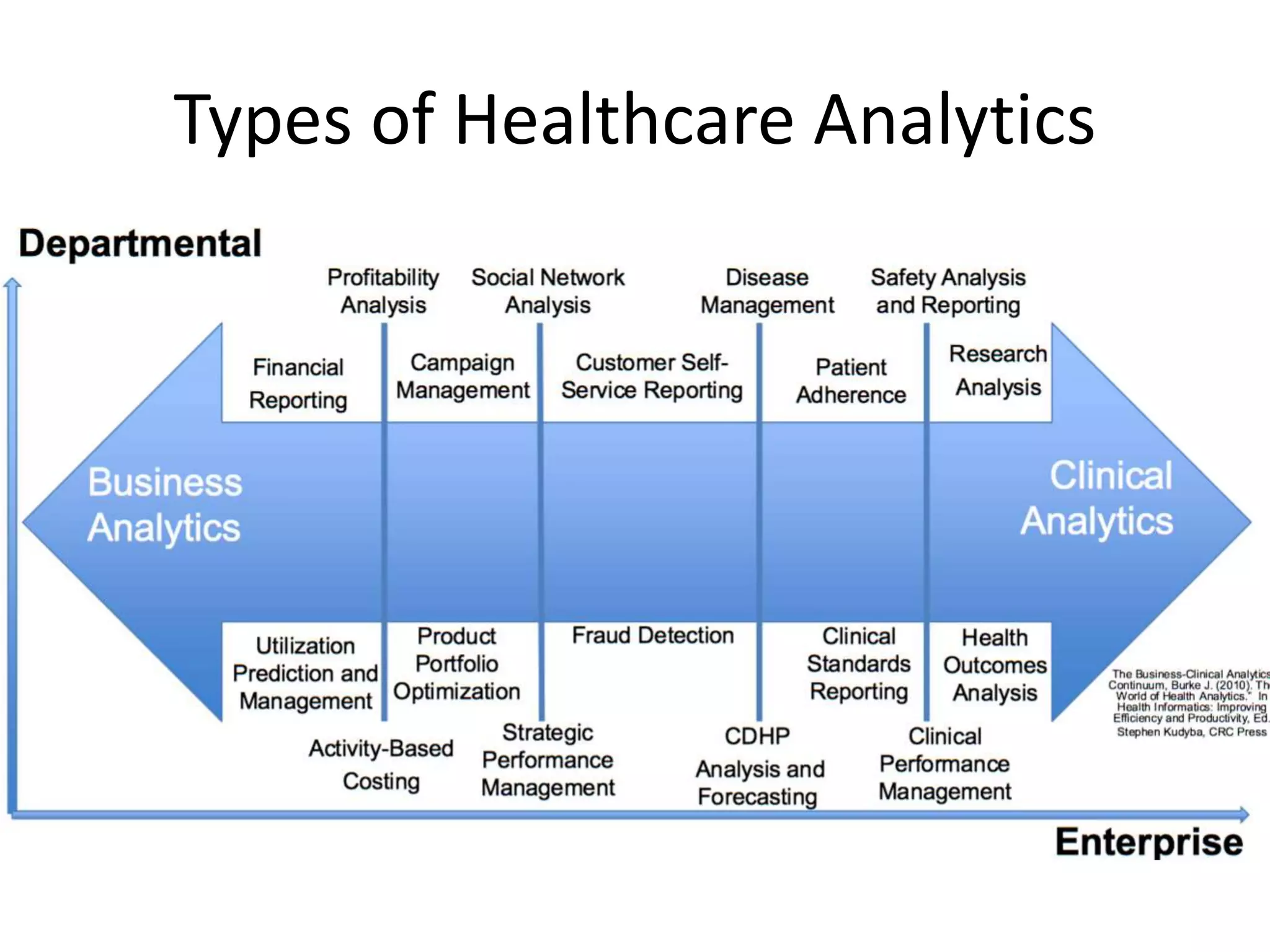




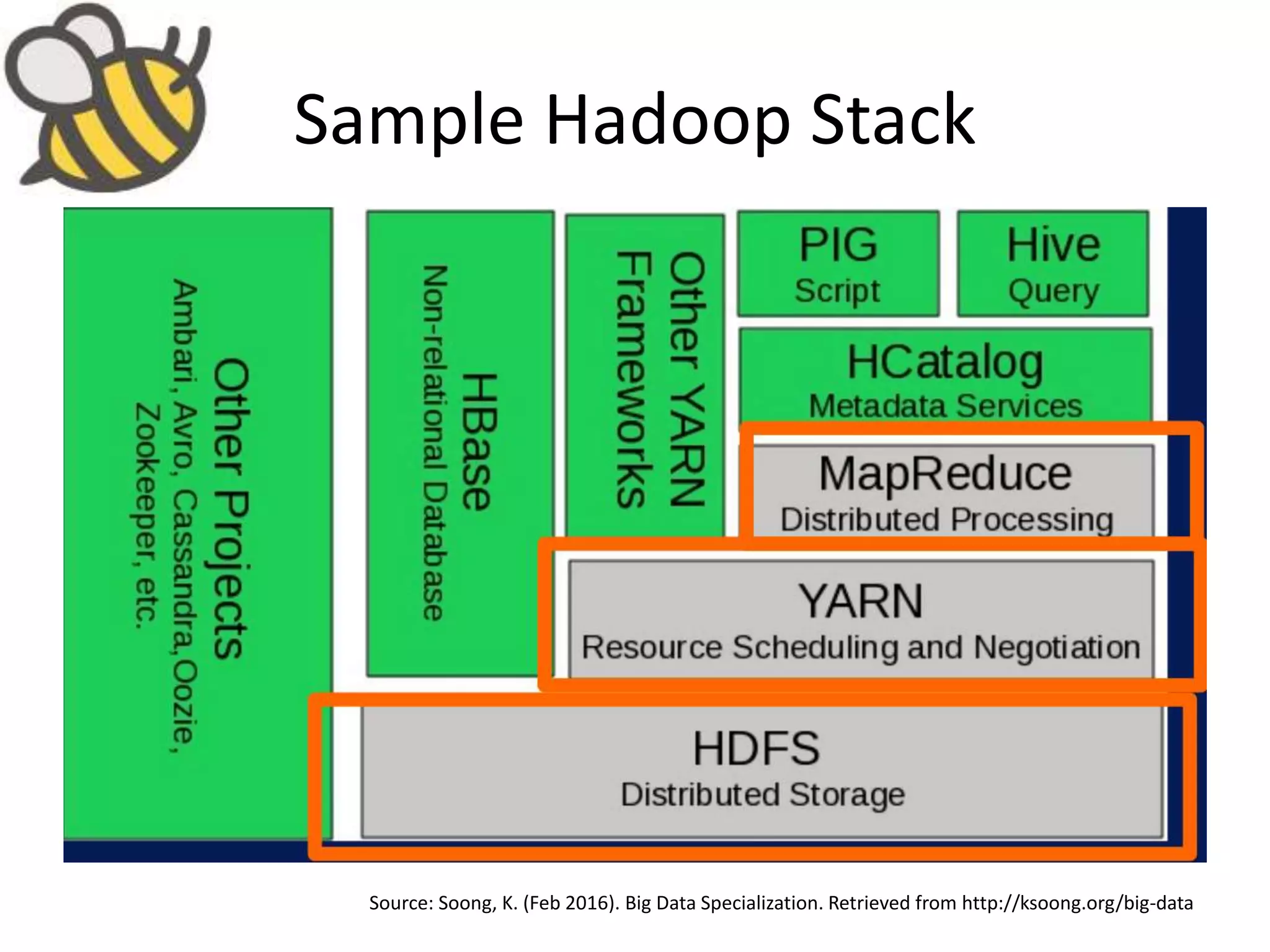






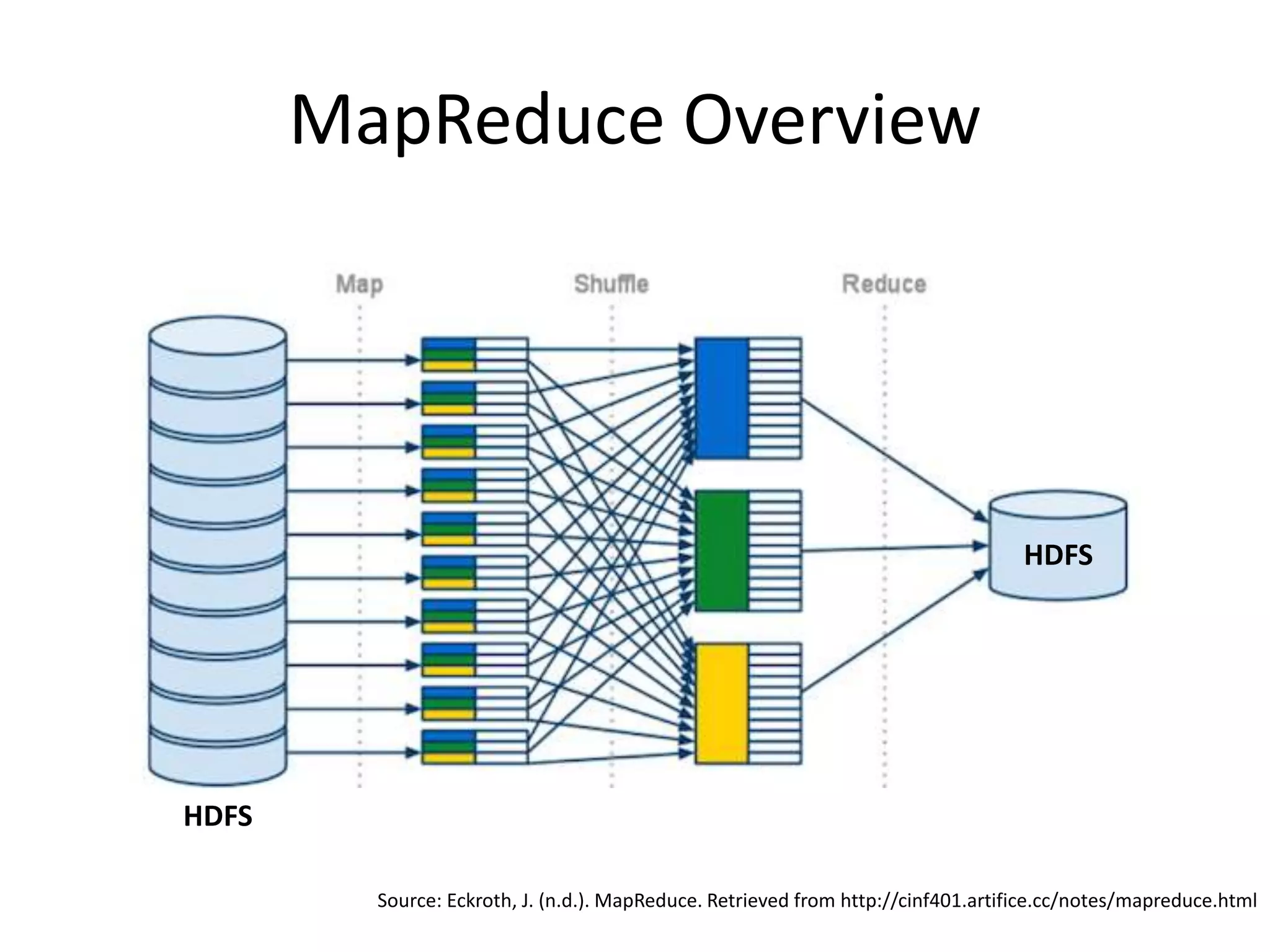
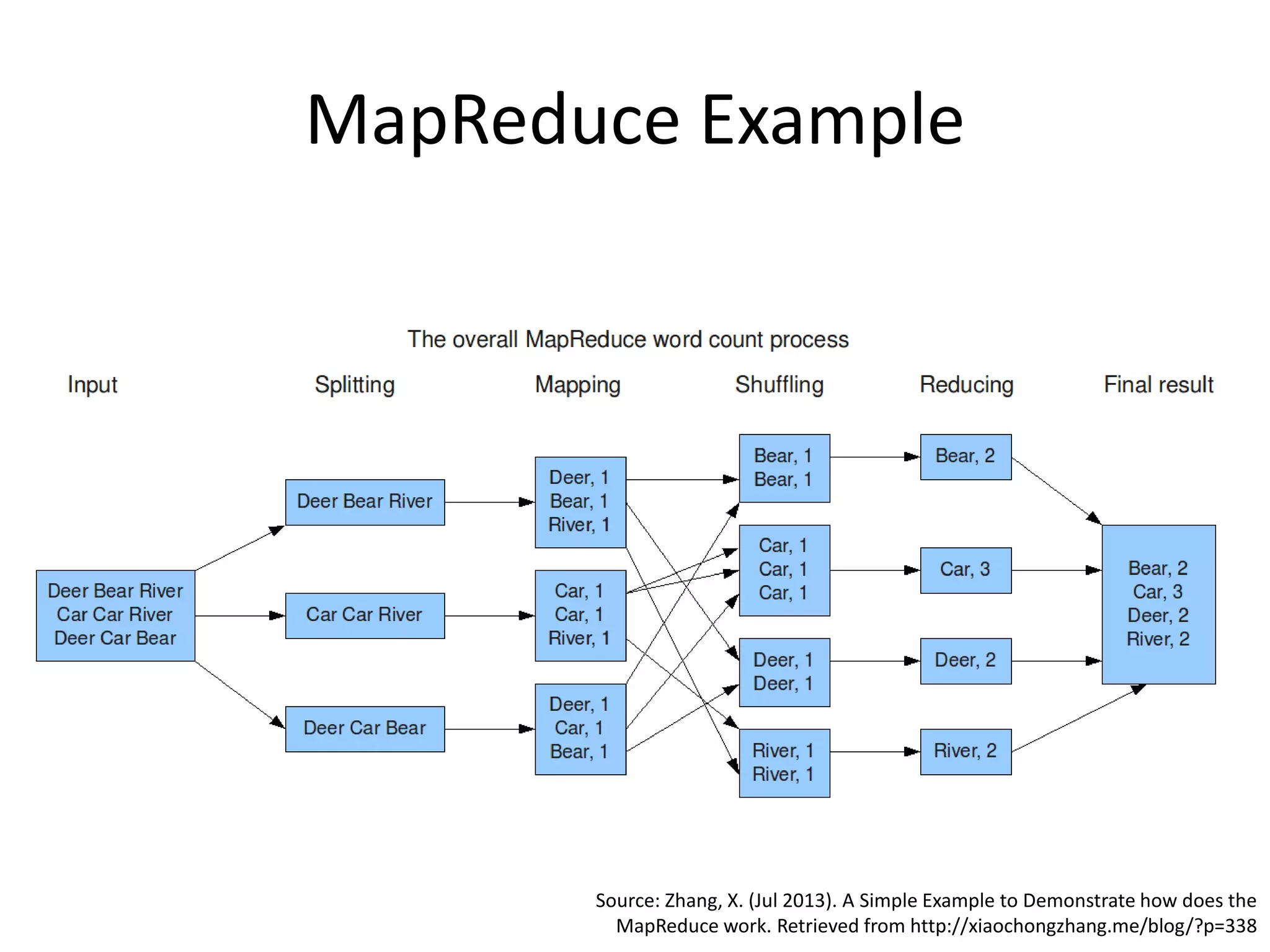






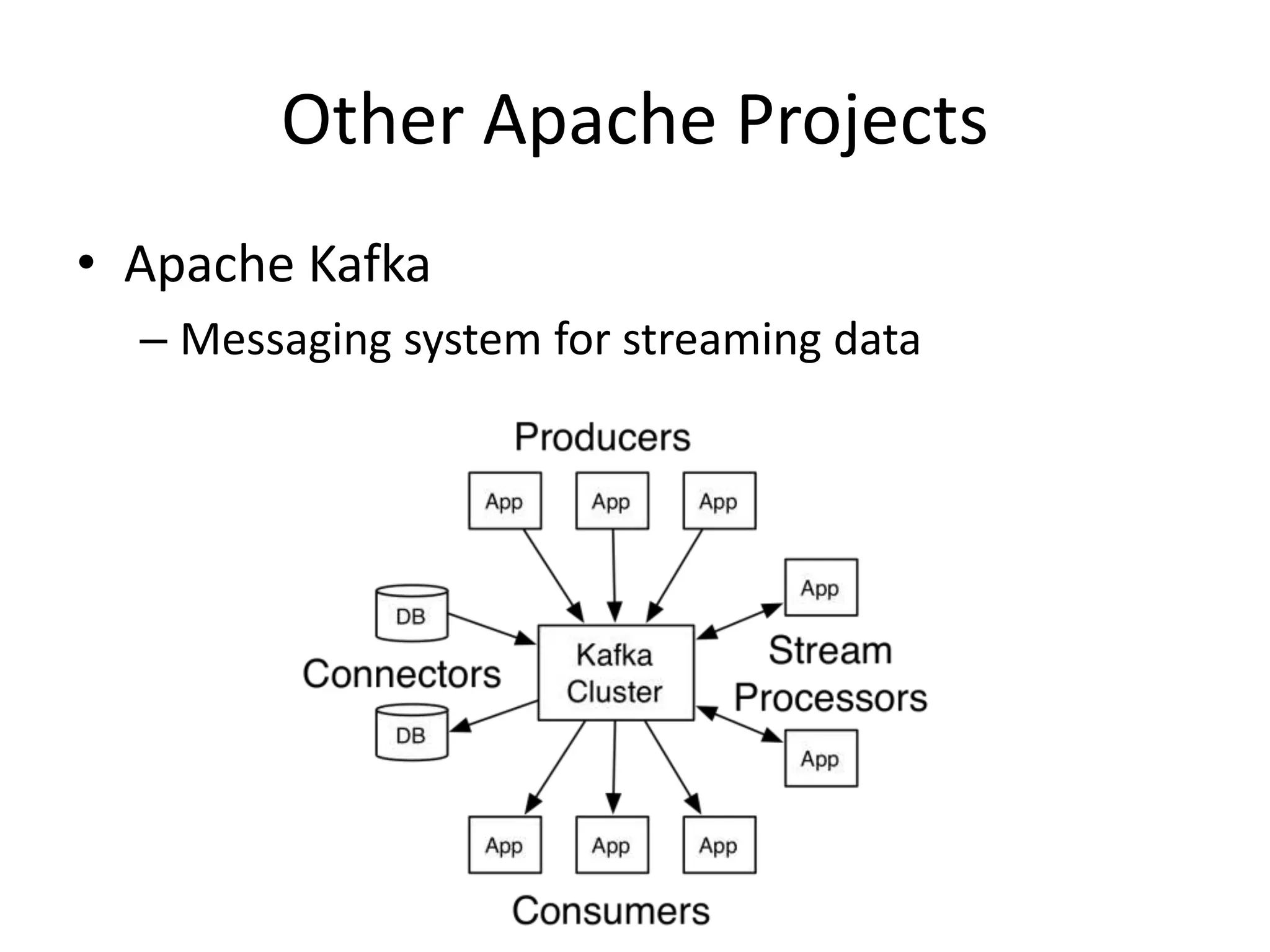







Aly Sivji's presentation discusses the potential of the Hadoop ecosystem in driving innovation in healthcare through big data and machine learning techniques. It addresses the historical development of electronic health records, the challenges facing the U.S. healthcare system, and how advanced analytics can enhance medical outcomes and reduce costs. Additionally, it explains the functionalities of various Hadoop components, including Apache Tez and Spark, as well as the benefits of using these technologies for data processing and analysis in a healthcare context.






















































































