Downloaded 33 times






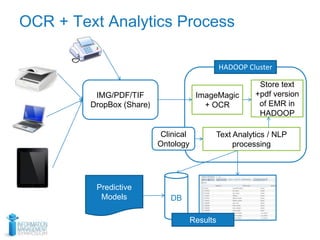



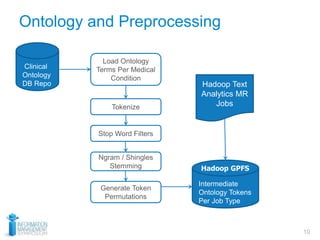




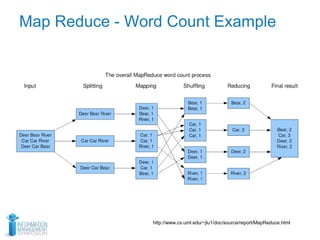









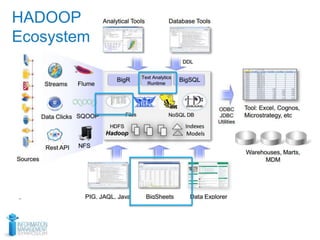


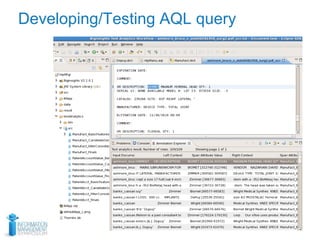
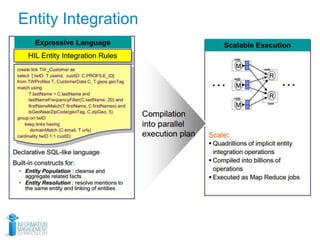


This document discusses using optical character recognition (OCR) and text analytics to analyze unstructured medical text from electronic and paper medical records. It describes Independence Blue Cross's distributed OCR and text analytics workflow that converts images to text and analyzes the text using tools like Hadoop, Lucene, and Weka. Business cases for this approach include product recalls, entity extraction from medical charts, and improving nurses' chart review processes. The document provides biographies of several individuals and describes components of the OCR, text analytics, Hadoop, and AQL systems.









































































