
Recommended
Recommended
More Related Content
Similar to Applying ocr to extract information : Text mining
Similar to Applying ocr to extract information : Text mining (20)
Recently uploaded
Recently uploaded (20)
Applying ocr to extract information : Text mining
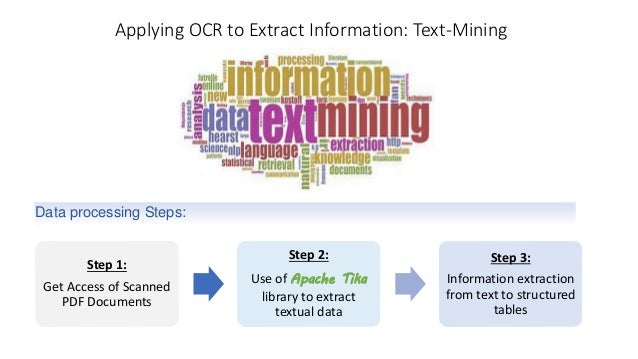
- 1. Applying OCR to Extract Information: Text-Mining Step 1: Get Access of Scanned PDF Documents Step 2: Use of Apache Tika library to extract textual data Step 3: Information extraction from text to structured tables Data processing Steps:
- 2. Applying OCR to Extract Information: Text-Mining Step 1: Access Scanned PDF documents Extracting/Connecting data to Hadoop server to get access of scanned PDF files (document) in Python Environment. Step 2: Text Extraction Use of parser from Apache Tika library to extract text from each assessment orders and store in a table form with two columns namely "Assessment Order ID" and "Actual Text". Synopsis of text extracted into a table: Step 3: Information Extraction from text Extracting following list of information with the use of Regular Expressions (pattern search) over Actual Text for each document. 1) Name 2) Financial Year 3) PAN 4) Legal Citation (which includes citation of SC, HC & ITAT) and 5) Legal Issues associated with each document
- 3. 1.Define 2.Design 3.Deploy 4.Analyze 5.Act Define: Identify specific requirements within use cases while highlighting risk factors and estimate value opportunities Design: Design a tracking strategy that captures the appropriate data with proper KPIs of the business requirement Deploy: Implement the technologies required to capture the data as along with the measurement strategy design Analyze: Insight driven analyses to expose challenges and identify opportunities Act: Leverage Analysis to describe and prescribe the challenges with solutions and uncover the hidden opportunities Analytics Cycle Text Analytics Text Analysis (TA) is a process which takes unseen texts as input and produces fixed-format, unambiguous data as output. This data may be used directly for display to users, or may be stored in a database or spreadsheet for later analysis, or may be used for indexing purposes in Information Retrieval (IR) applications.
- 4. Documents • Text Mining • Topic Modeling • Text Classification • Named Entity Recognition • Relation extraction • Event detection • Natural Language Toolkit (NLTK) • Gensim, • Scikit-Learn Multi-dimensional Text Mining Tools Word Frequency Analysis: • Most Frequent words • Frequency Distribution Results Text Classification: • Multi-label Domain Specific classified texts Collocation Analysis • Bigrams • Trigrams and • N-grams Keyword Analysis • Keyword Counts, • Most prominent Categories Topic Modeling • Discovering Topics and Categories Performance Measures • Accuracy, Precision, Recall, F-Measures Comprehensive tool set for • Data editing and visualization • Rapid application development • Manual annotation • Ontology management User Interface Text Analytics - Process Flow