Downloaded 67 times



























The document discusses the technologies and methodologies for self-service data ingestion using Apache NiFi, StreamSets, and Kafka. It provides an overview of each tool's features, challenges in data ingestion, and potential use cases with relevant demo cases. The author, Guido Schmutz, is an experienced consultant in IT, specializing in big data and data flow processing.
Introduction of the presentation on self-service data ingestion solutions using NiFi, StreamSets & Kafka.
Guido Schmutz’s extensive experience, roles at Trivadis, and expertise in IT, Oracle, and Big Data.
Trivadis as a leading IT consulting firm with 600+ employees, expertise in multiple fields, and a strong operational presence.
Outline of the agenda covering Data Flow Processing, Apache NiFi, StreamSets Data Collector, Kafka Connect.
Introduction to Data Flow Processing as a framework for managing data ingestion and movement.
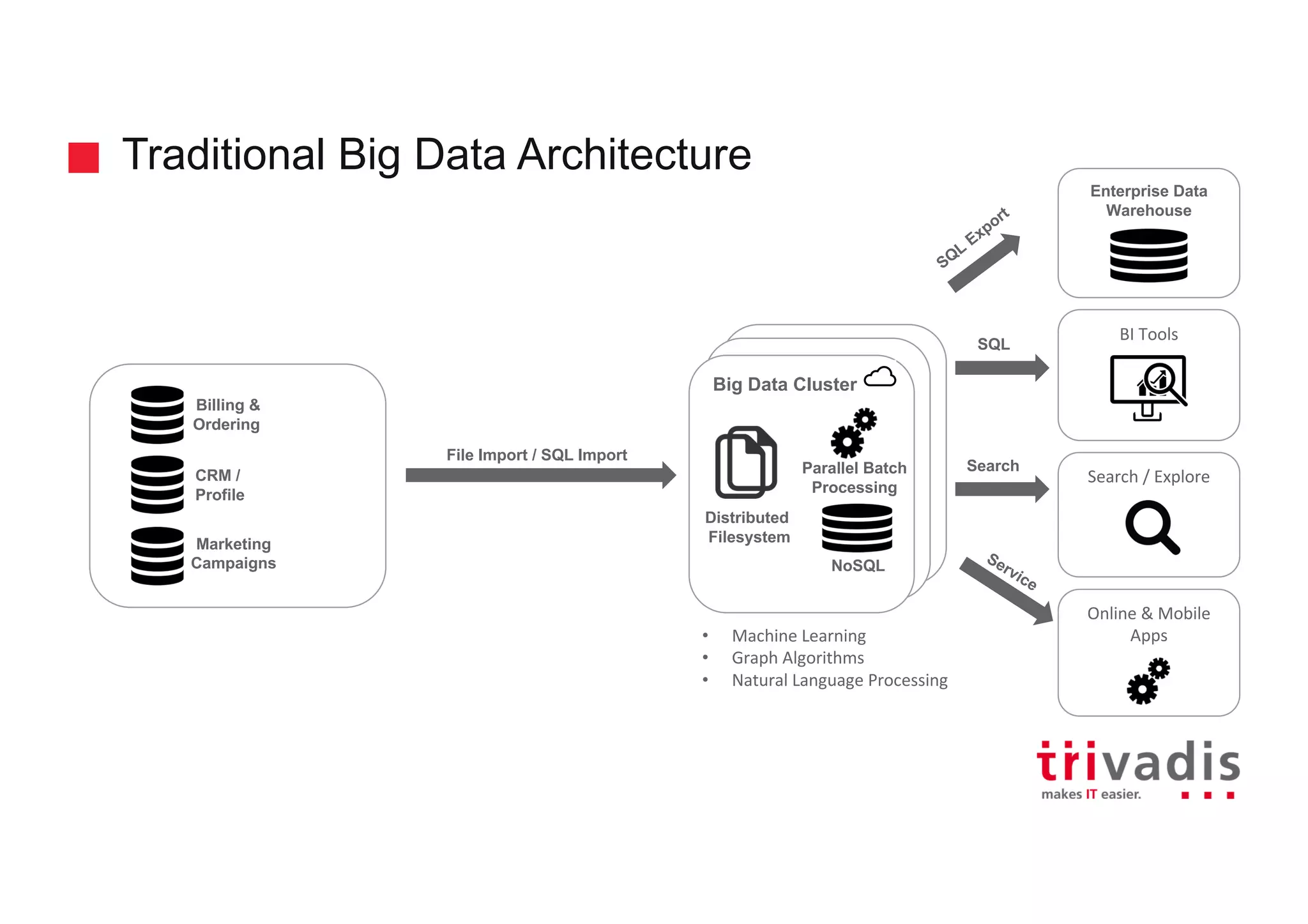
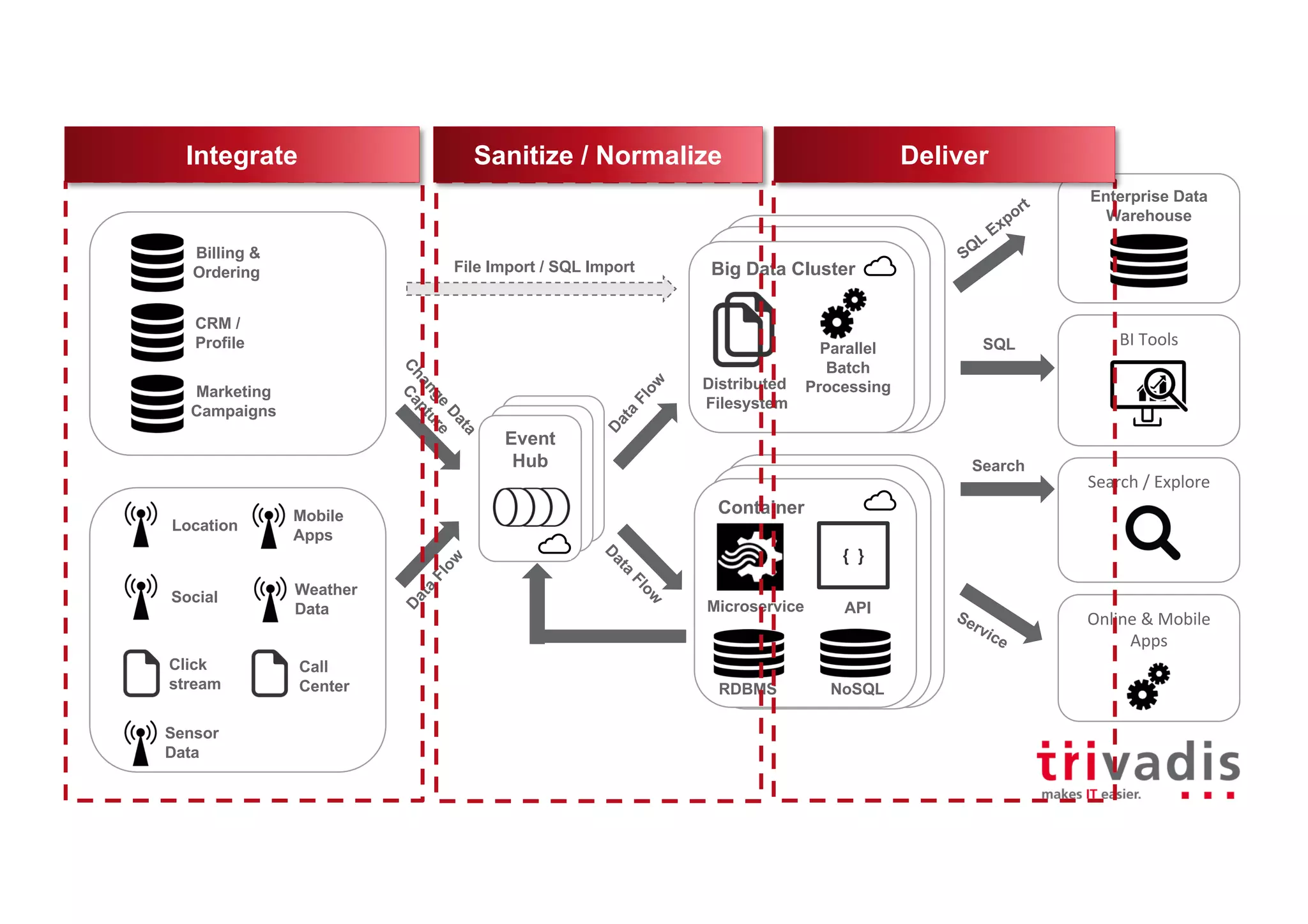
Description of traditional big data architecture involving batch processing, data warehouses, and BI tools.
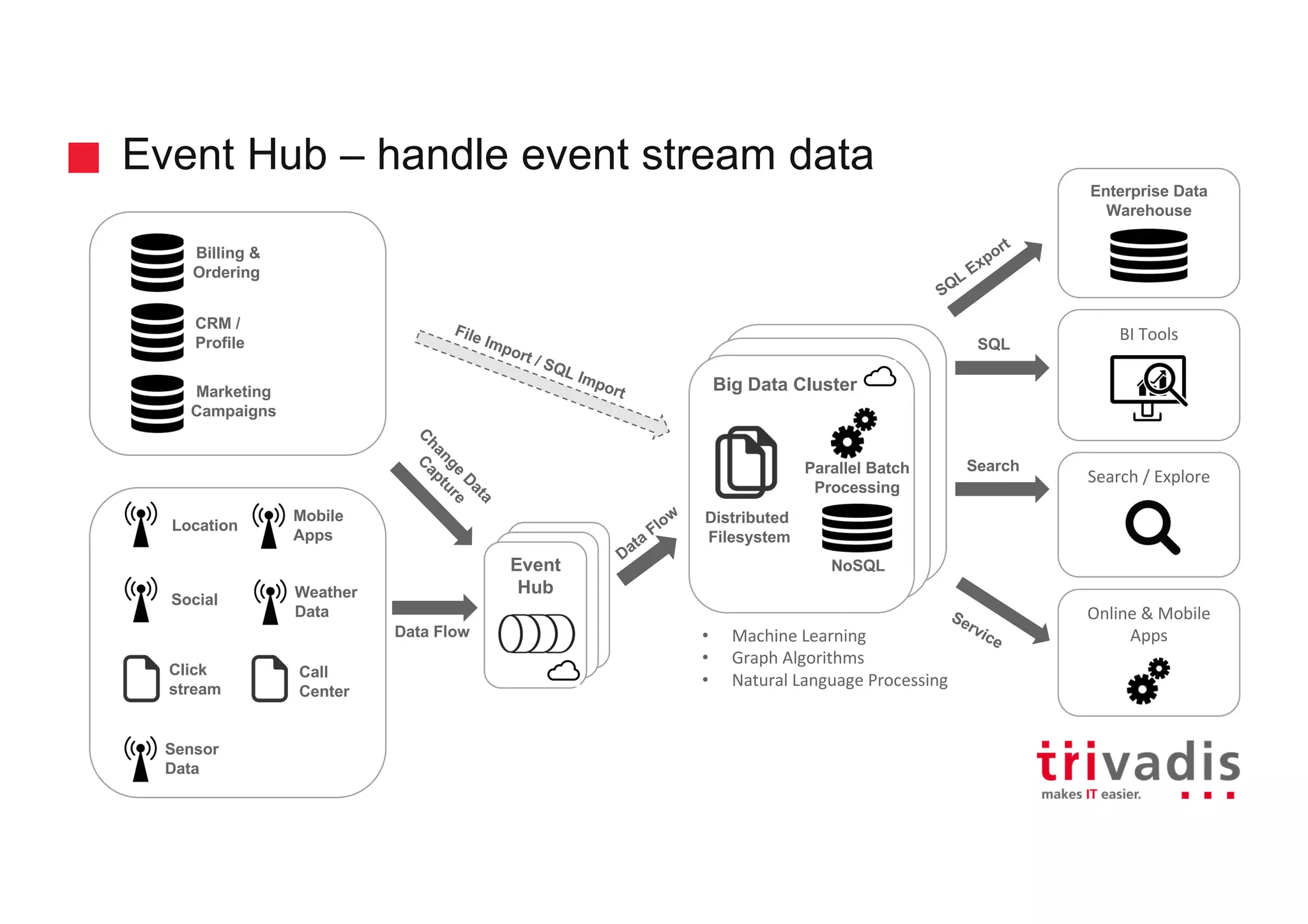
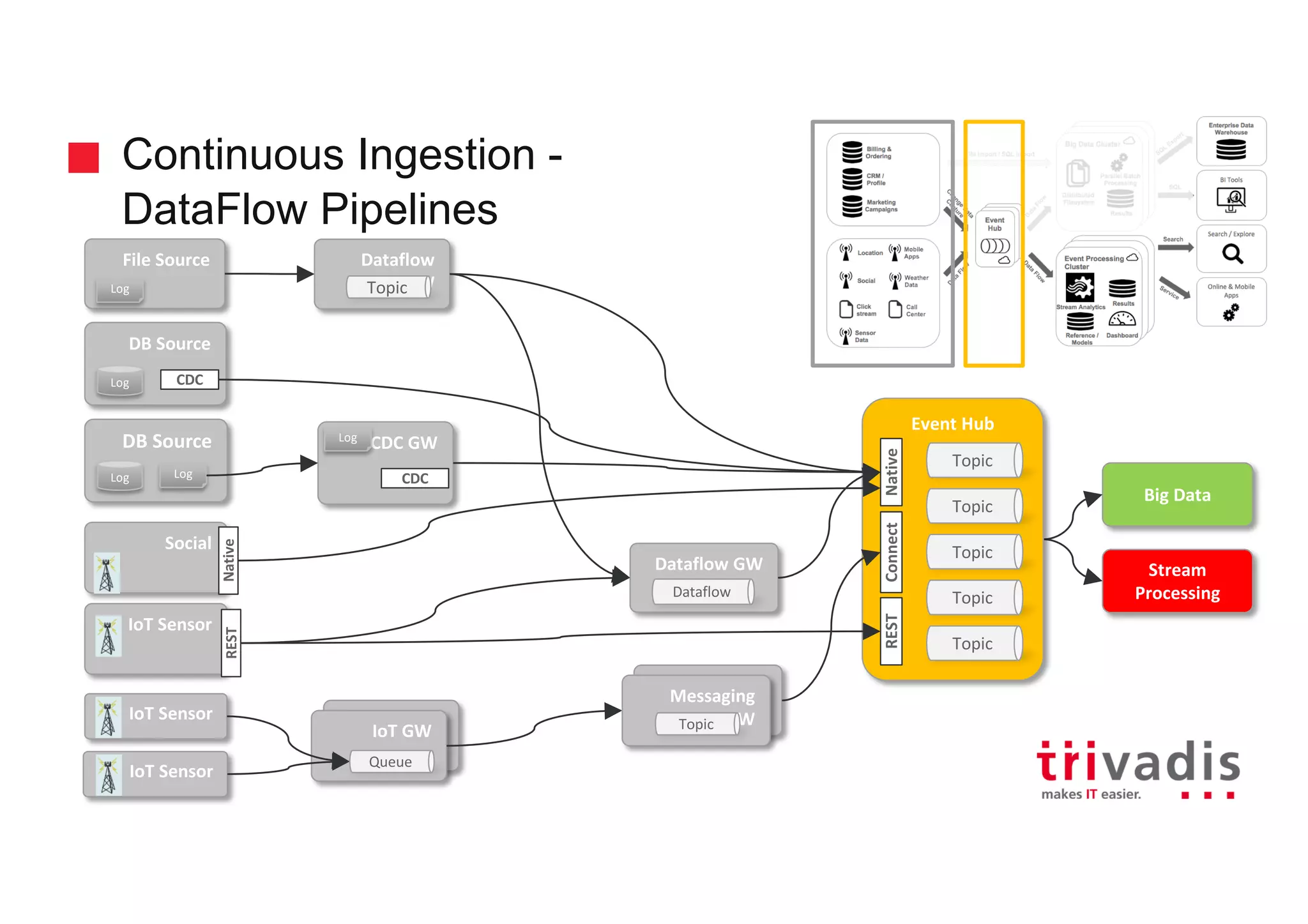
Role of Event Hub in processing event stream data, including various sources like CRM and sensor data.
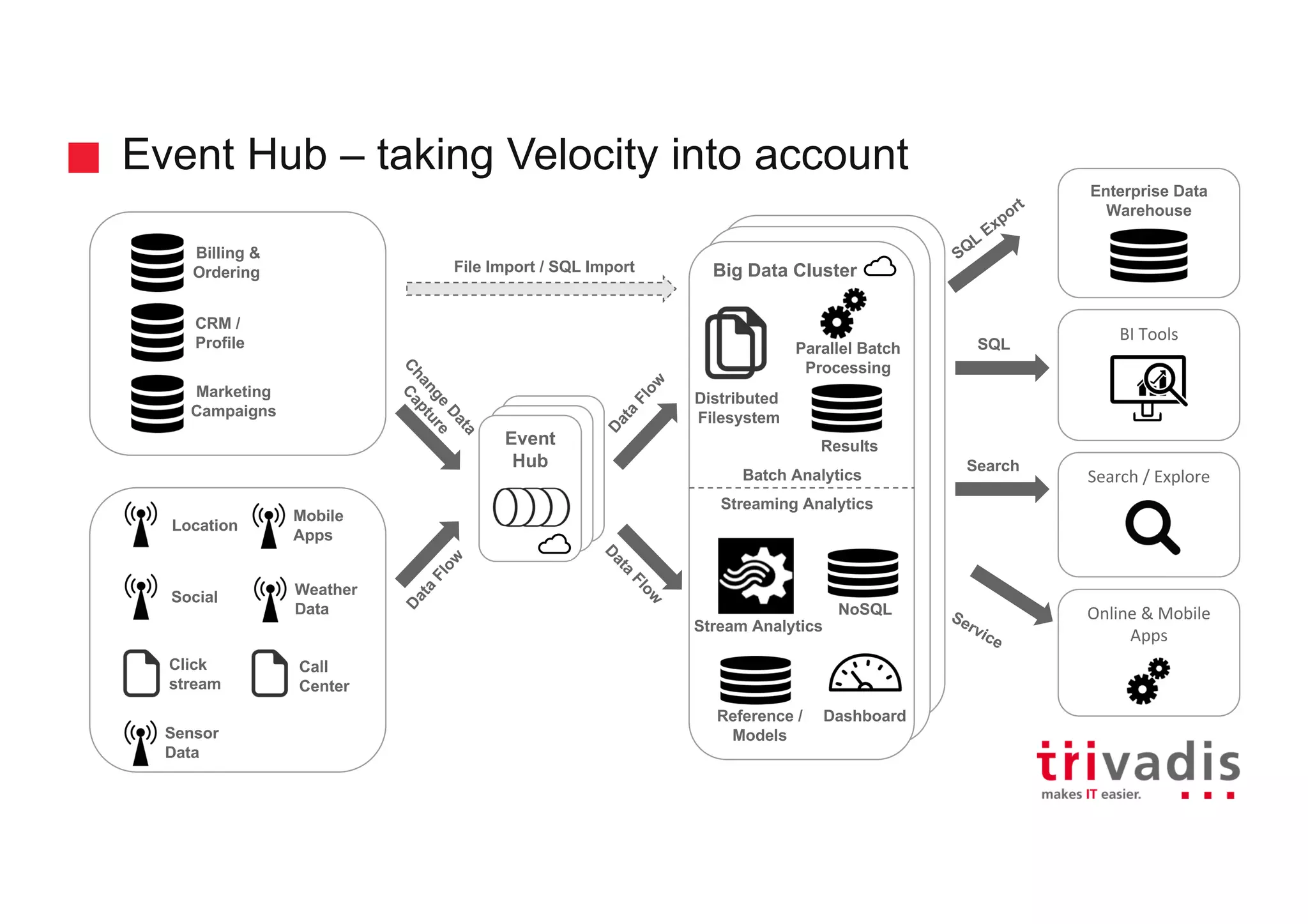
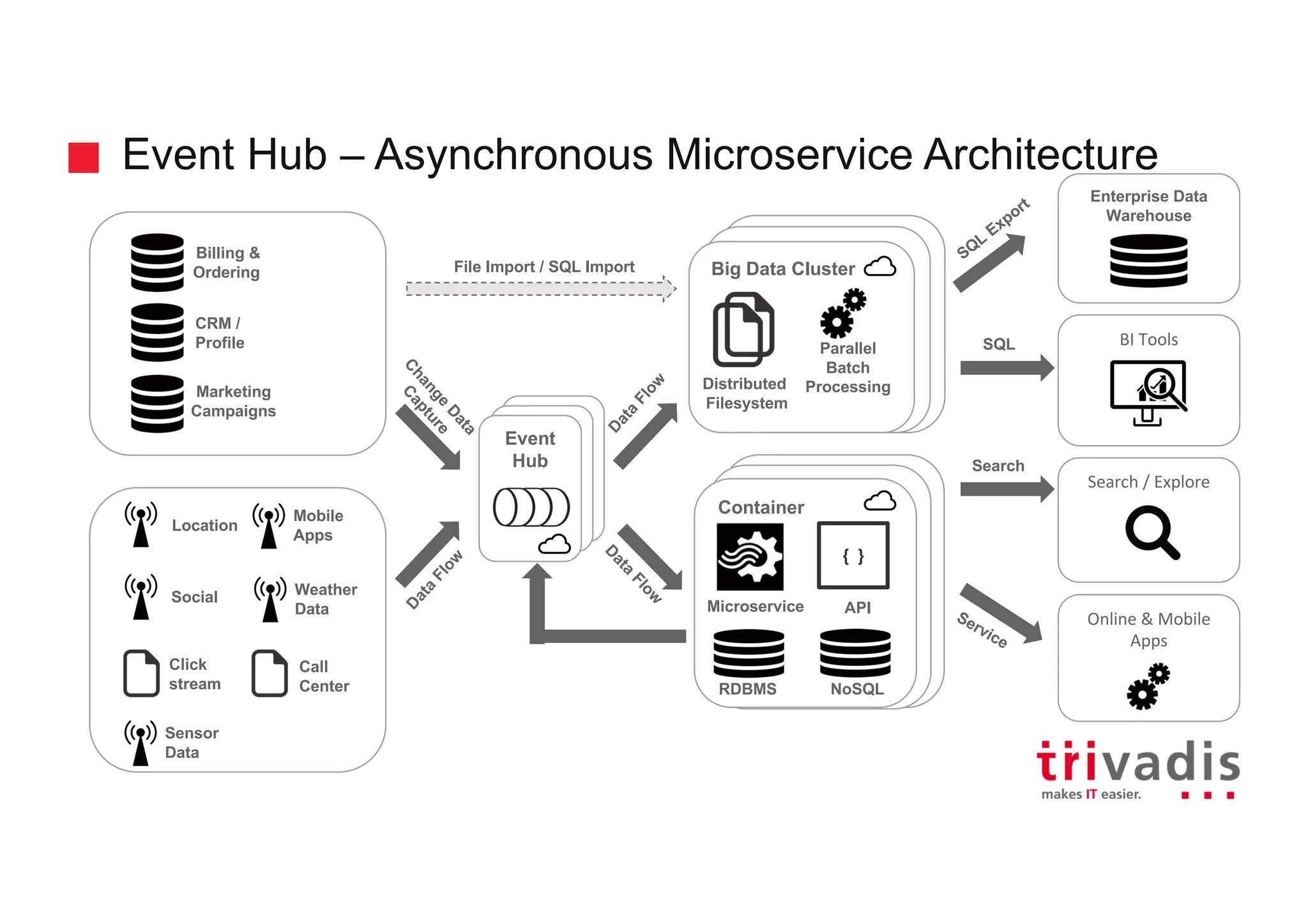
Architecture considerations for using Event Hubs with a focus on microservices and data integration.
Details on IoT data ingestion pipelines and handling data from multiple sensors to Cloud platforms.
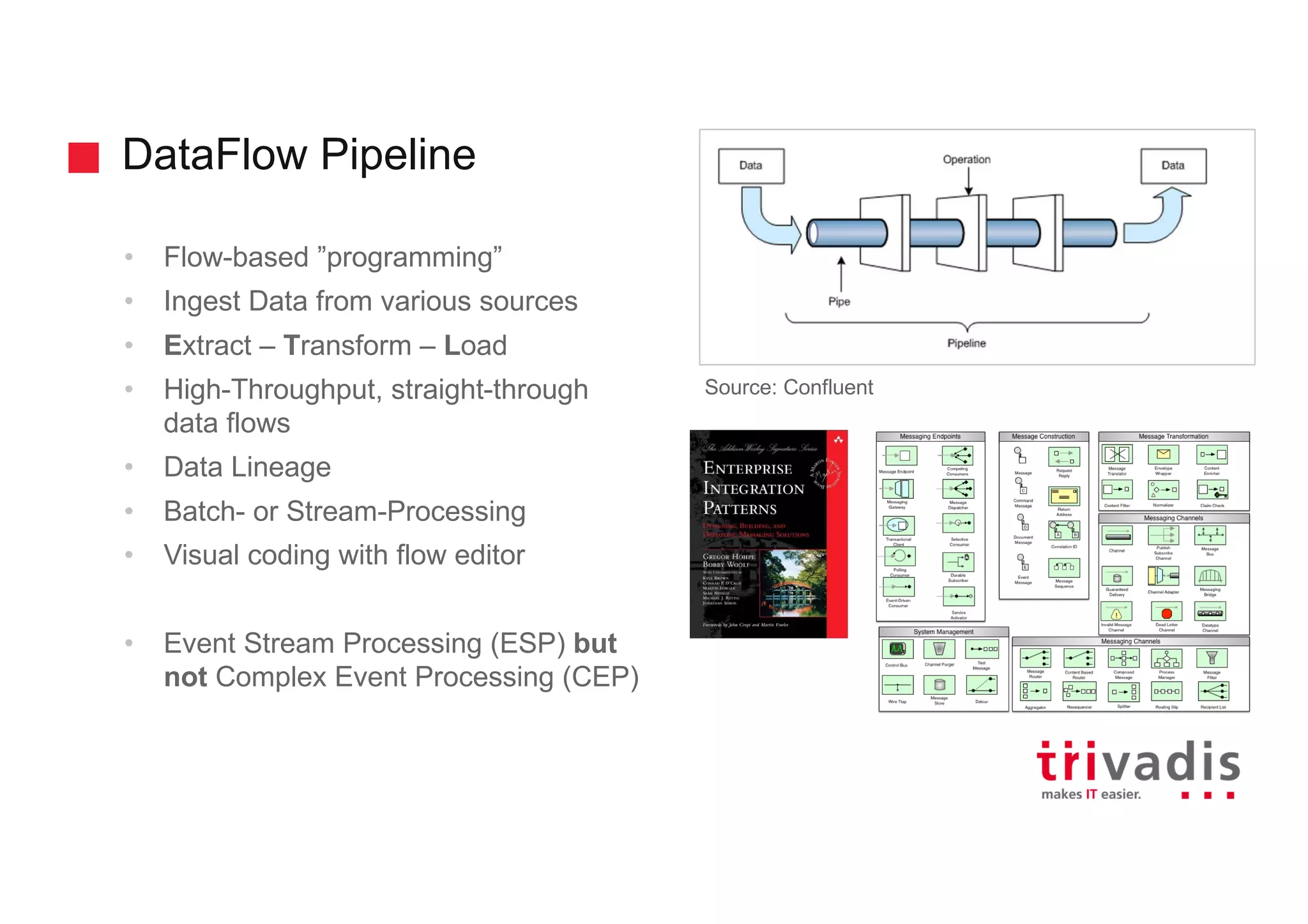
Key characteristics of data flow pipelines focusing on high-throughput, data lineage, and processing methodologies.
Overview of key challenges faced during data ingestion including infrastructure, data quality, and transformation issues.
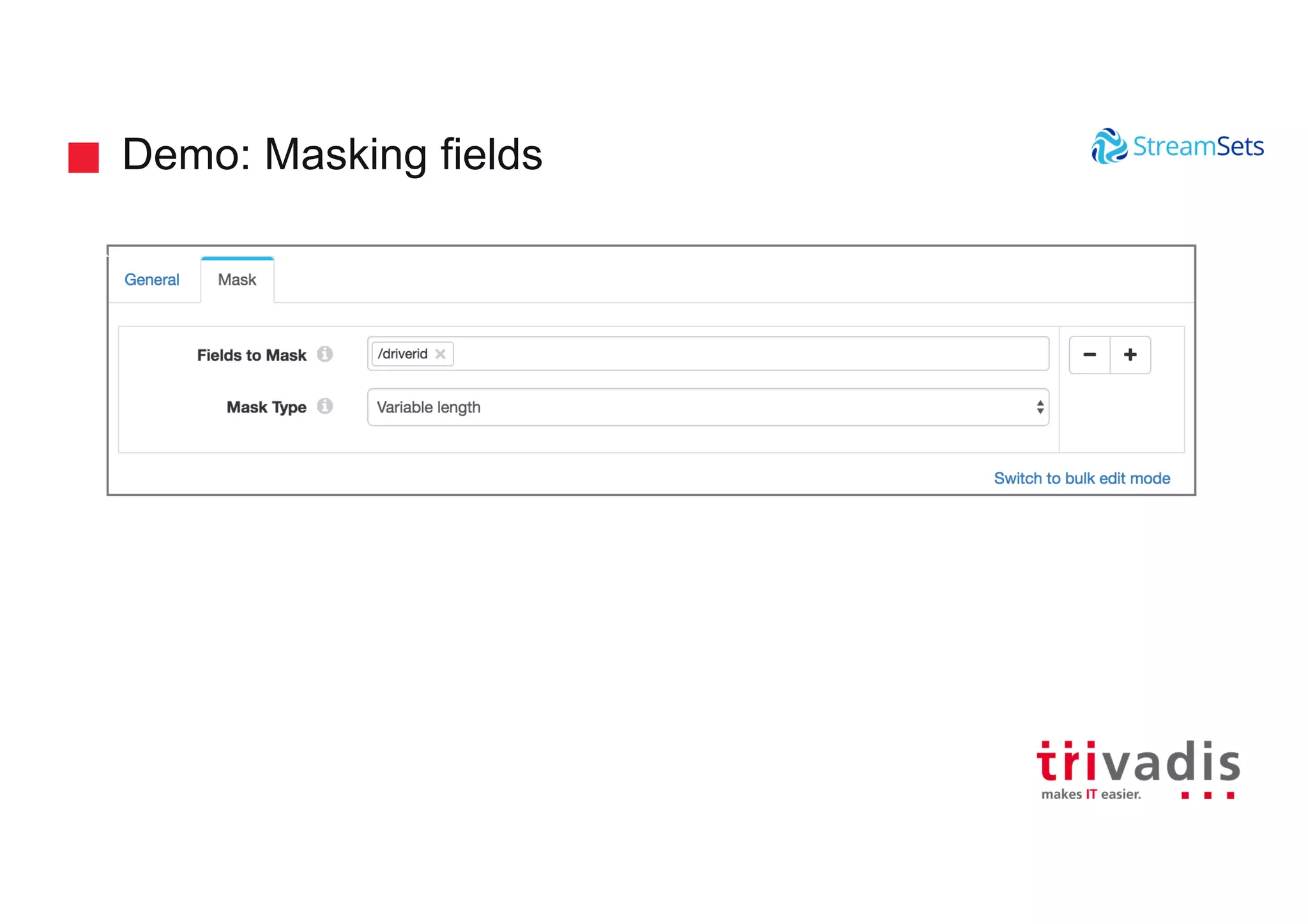
Different types of transformations during data ingestion, including zero transformation and enriching data.
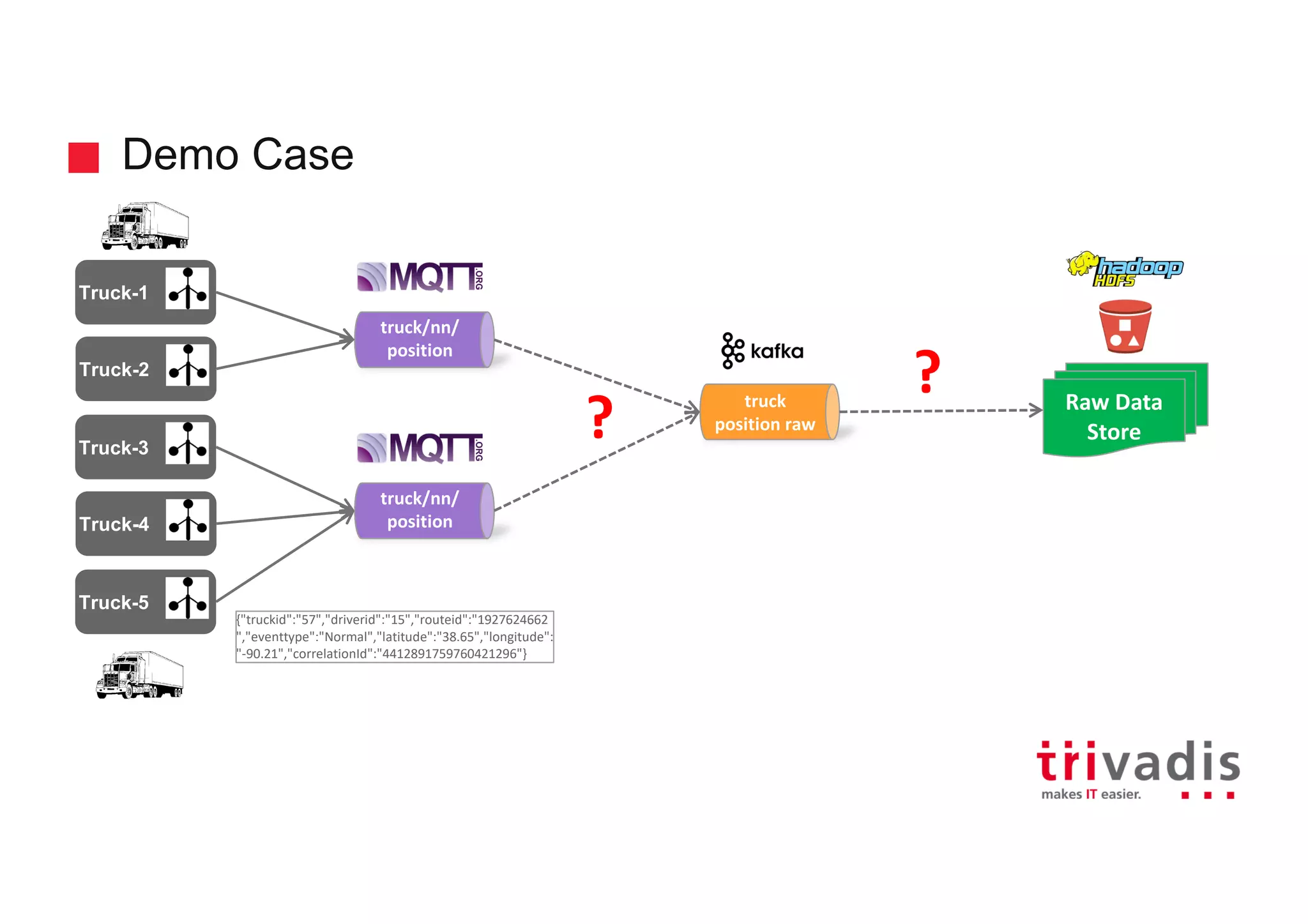
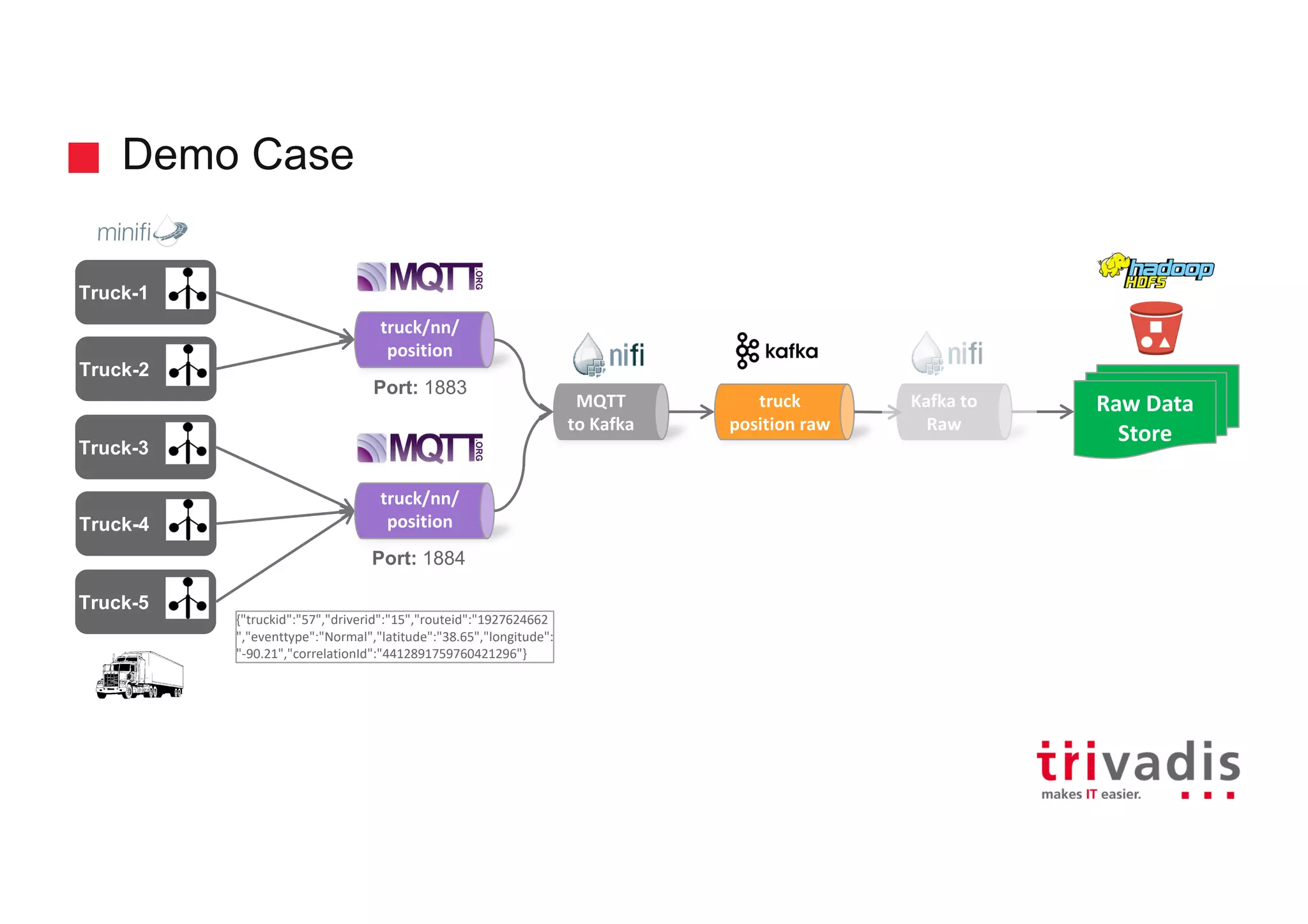
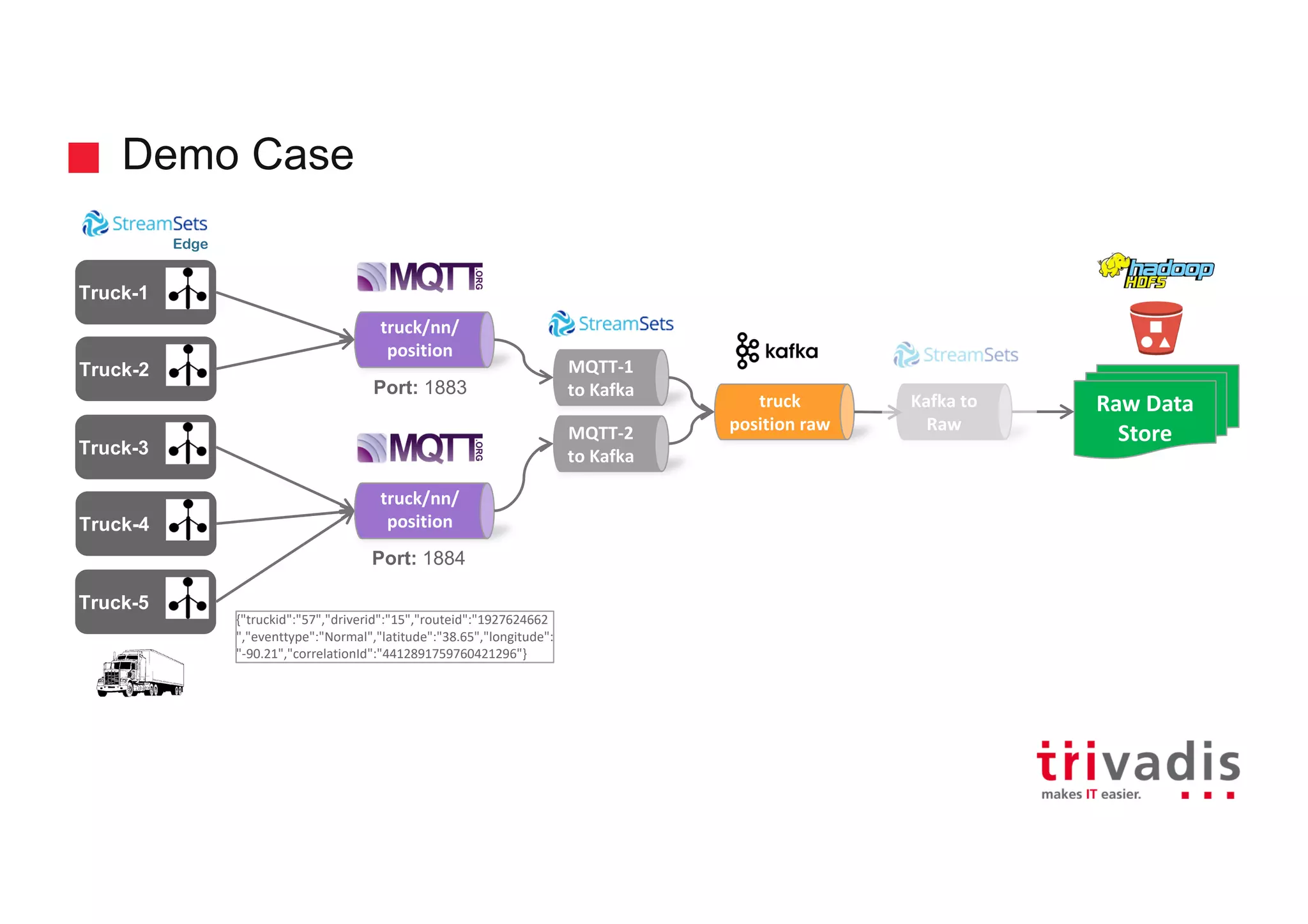
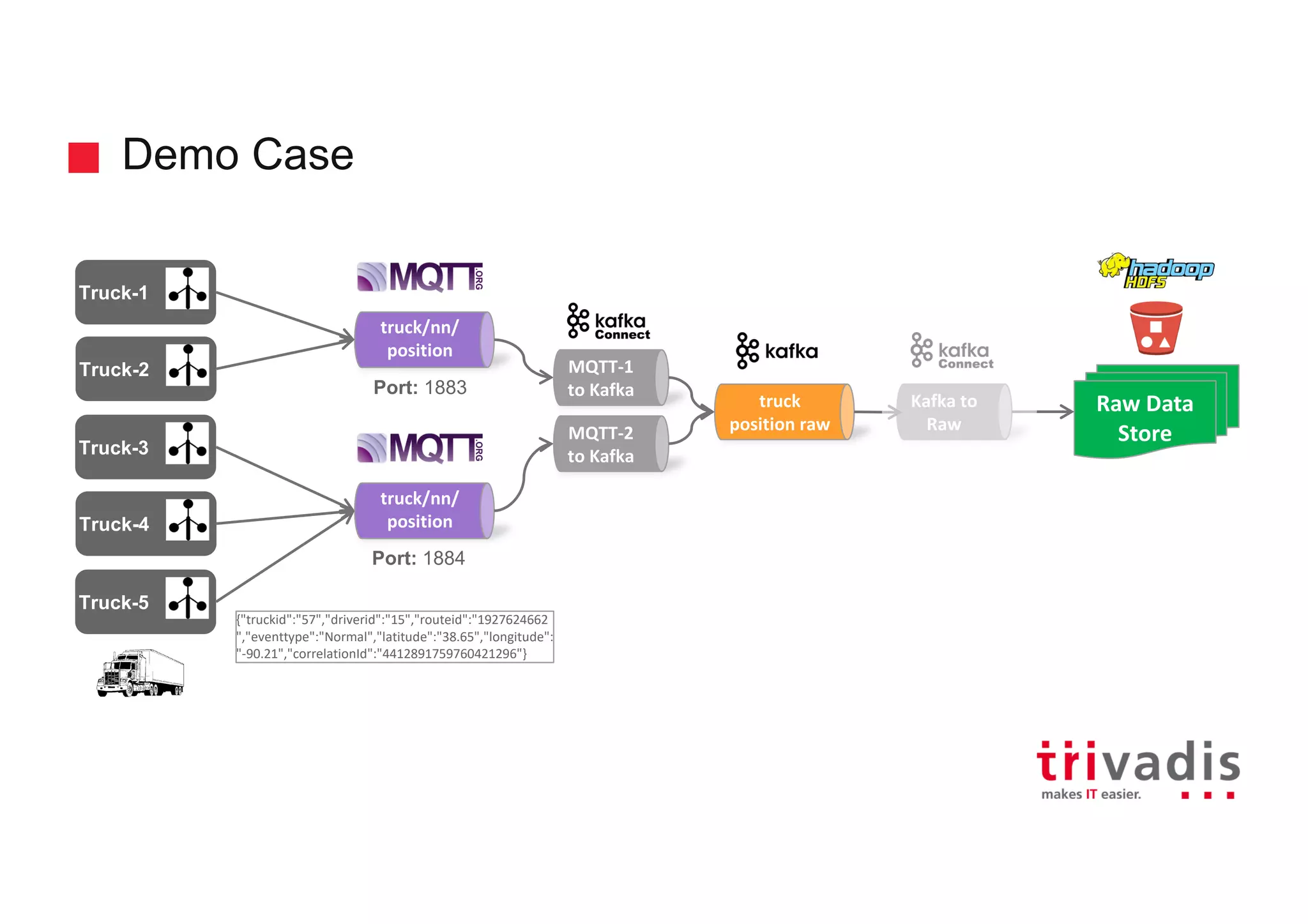
Demonstration case of processing truck data with raw data illustrations.
Overview of Apache NiFi including its history, features, and unique flow-based programming approach.
List of processors used in NiFi for source and sink operations, enabling data movement and transformation.
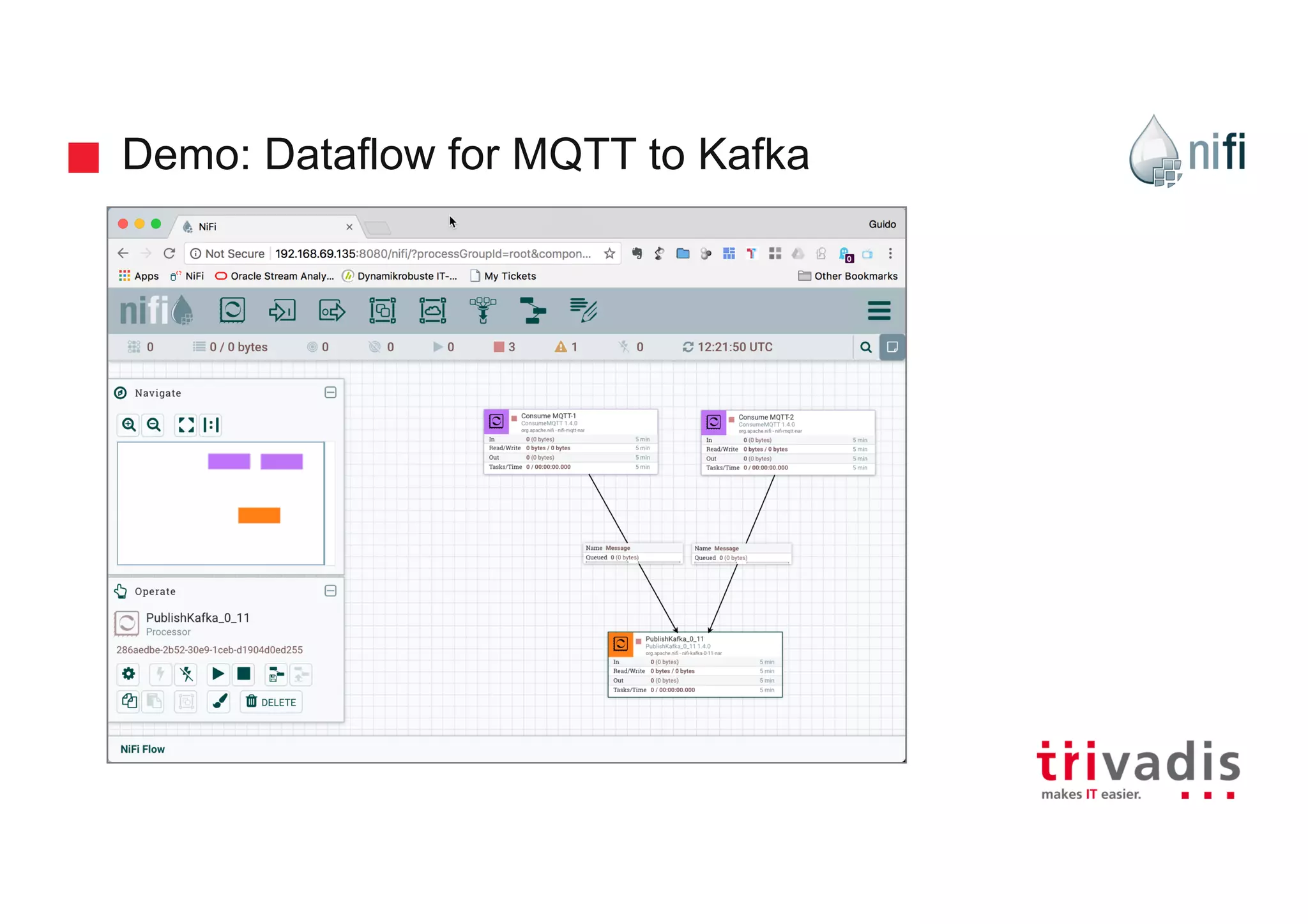
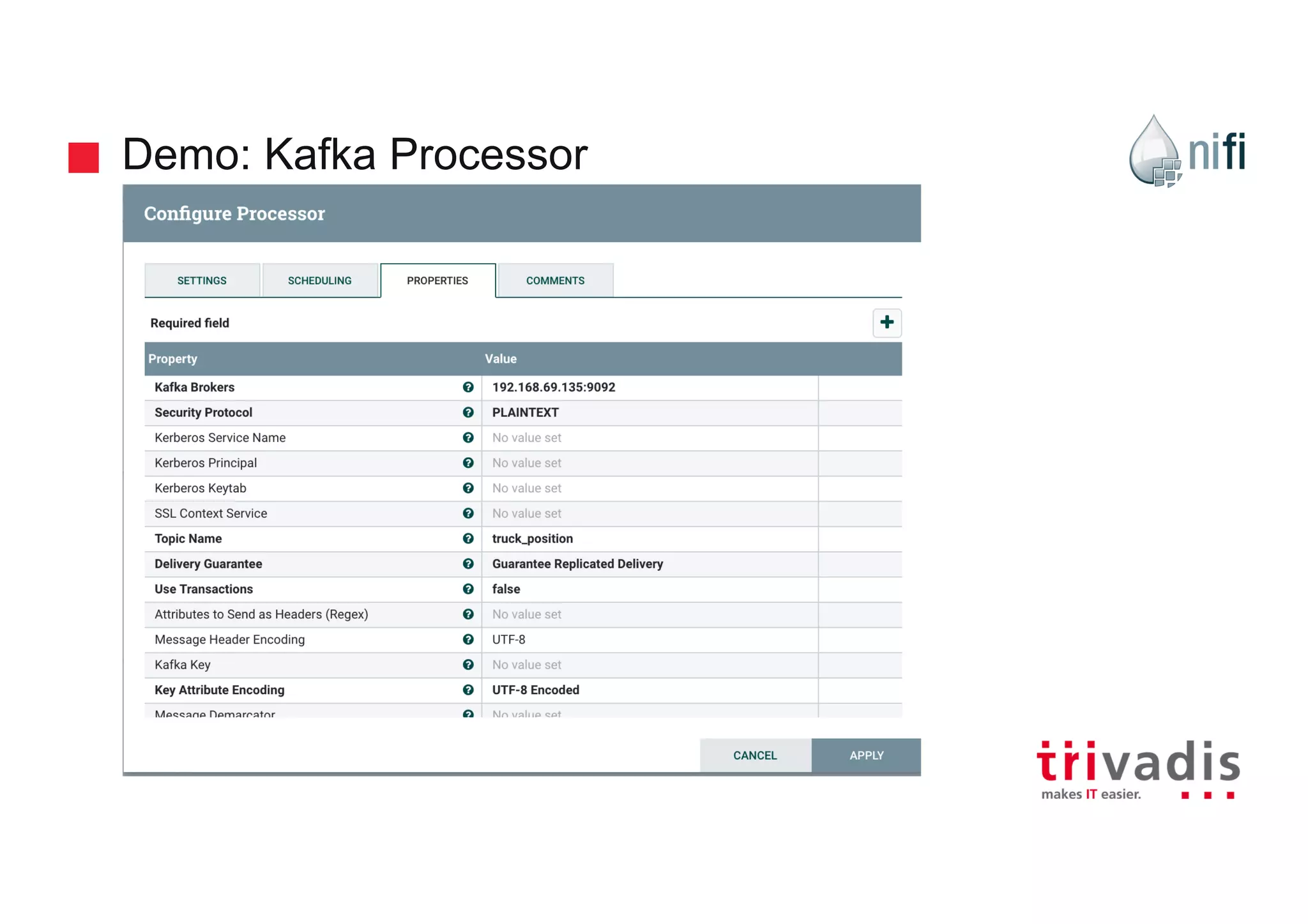
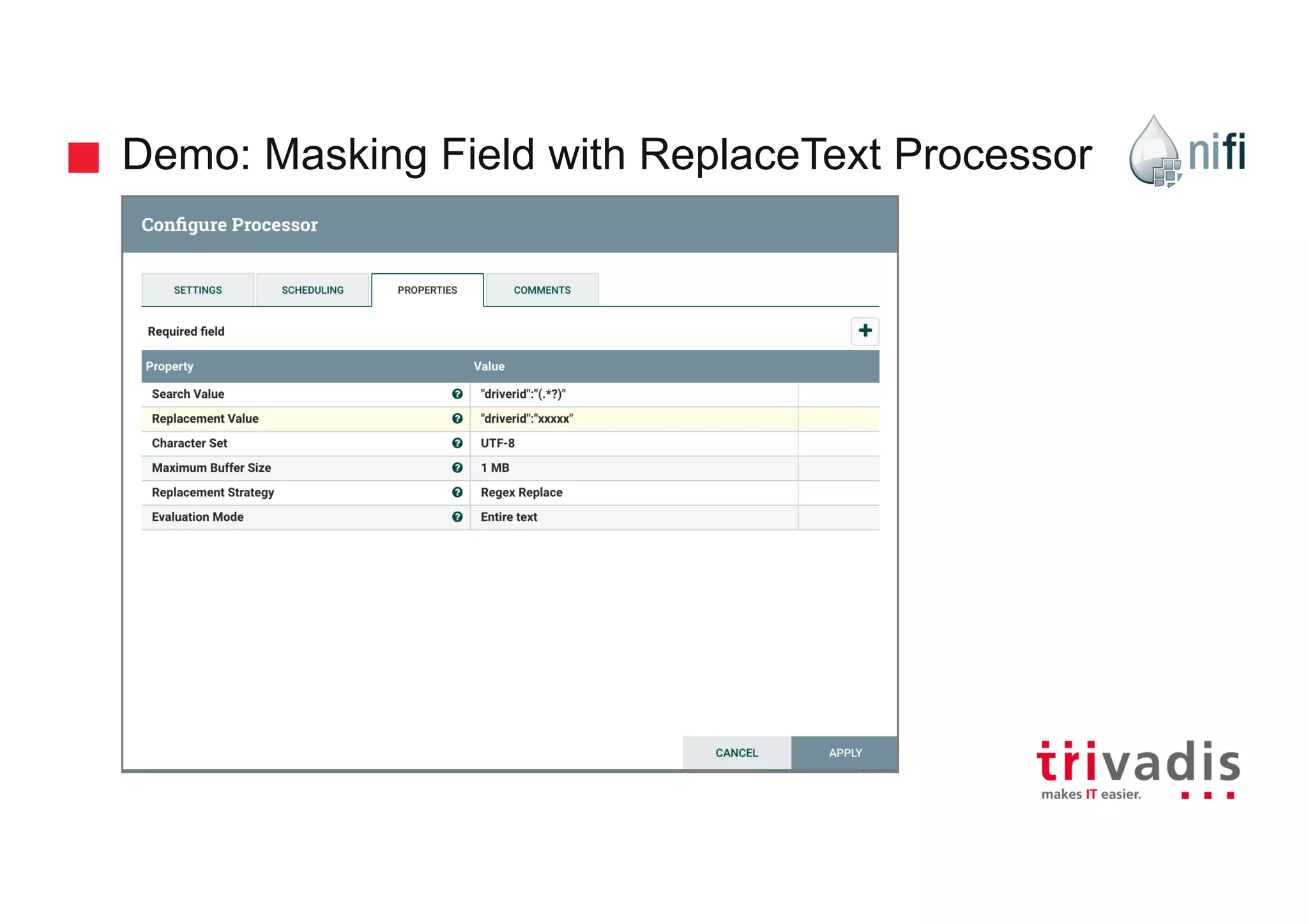
Practical demonstrations of data flow from MQTT to Kafka using various NiFi processors.
Introduction to StreamSets as an innovative solution for big data ingestion incorporating visual approaches.
Detailing origin and processor stages in StreamSets, highlighting types of processing and data flow management.
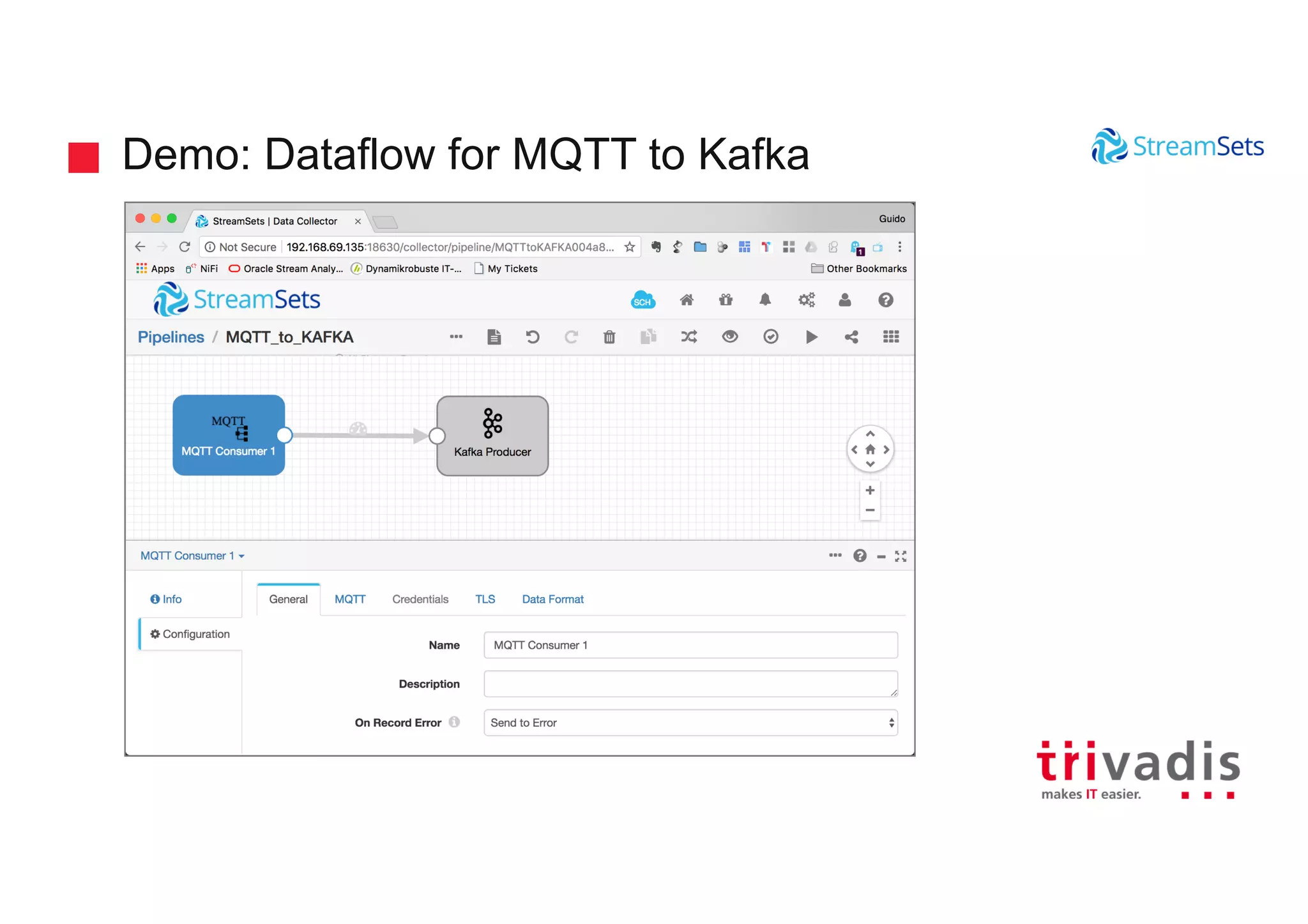
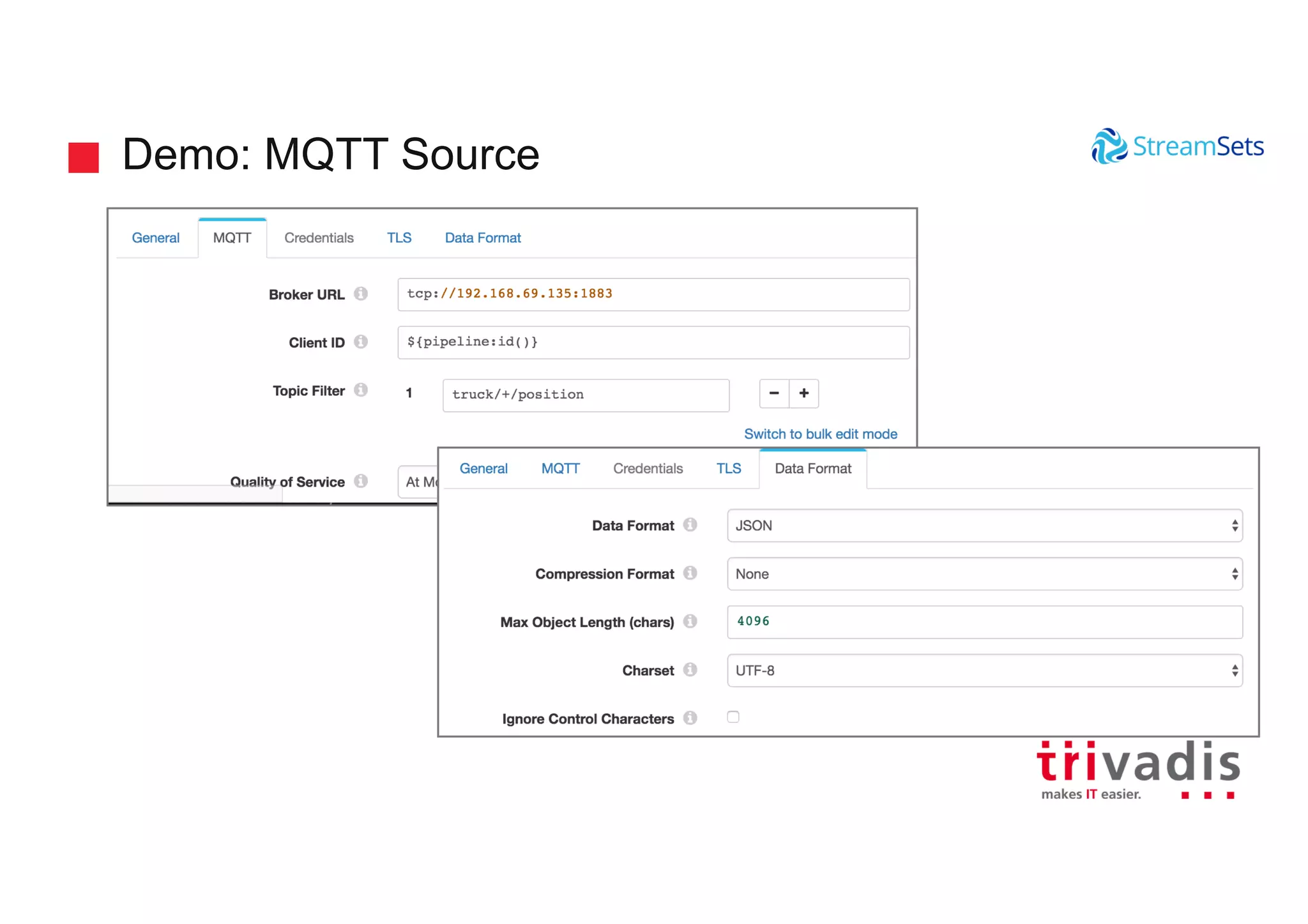
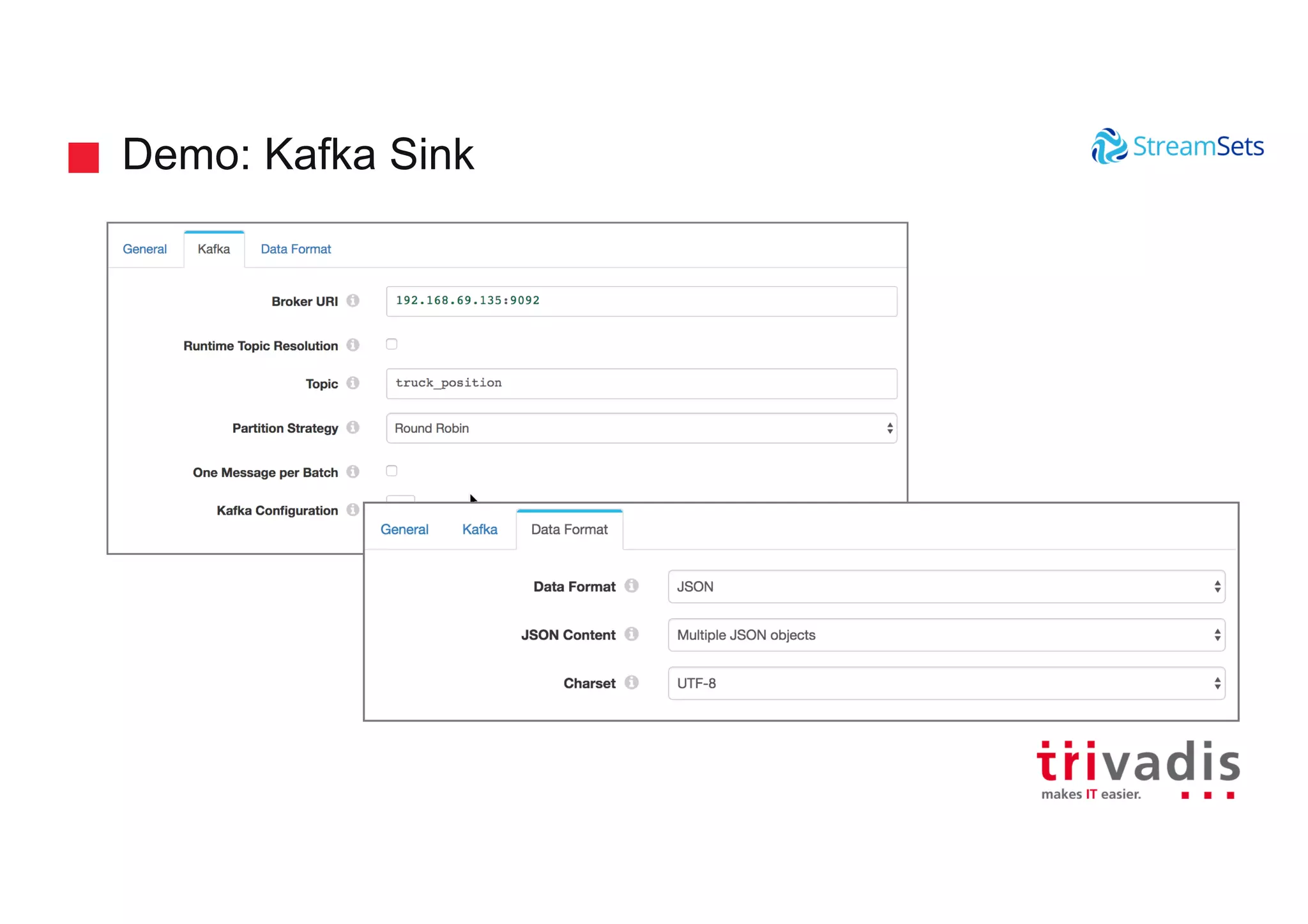
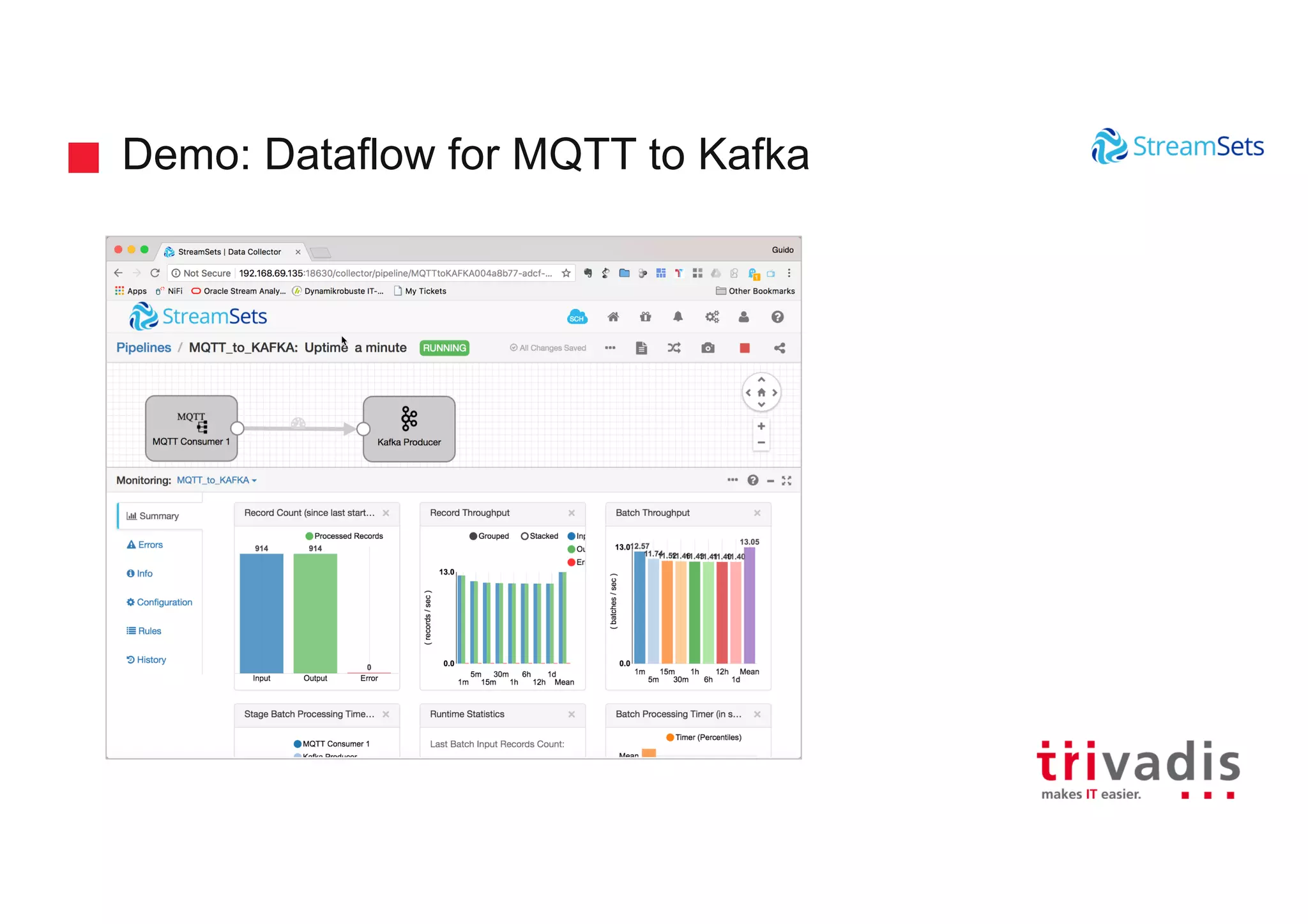
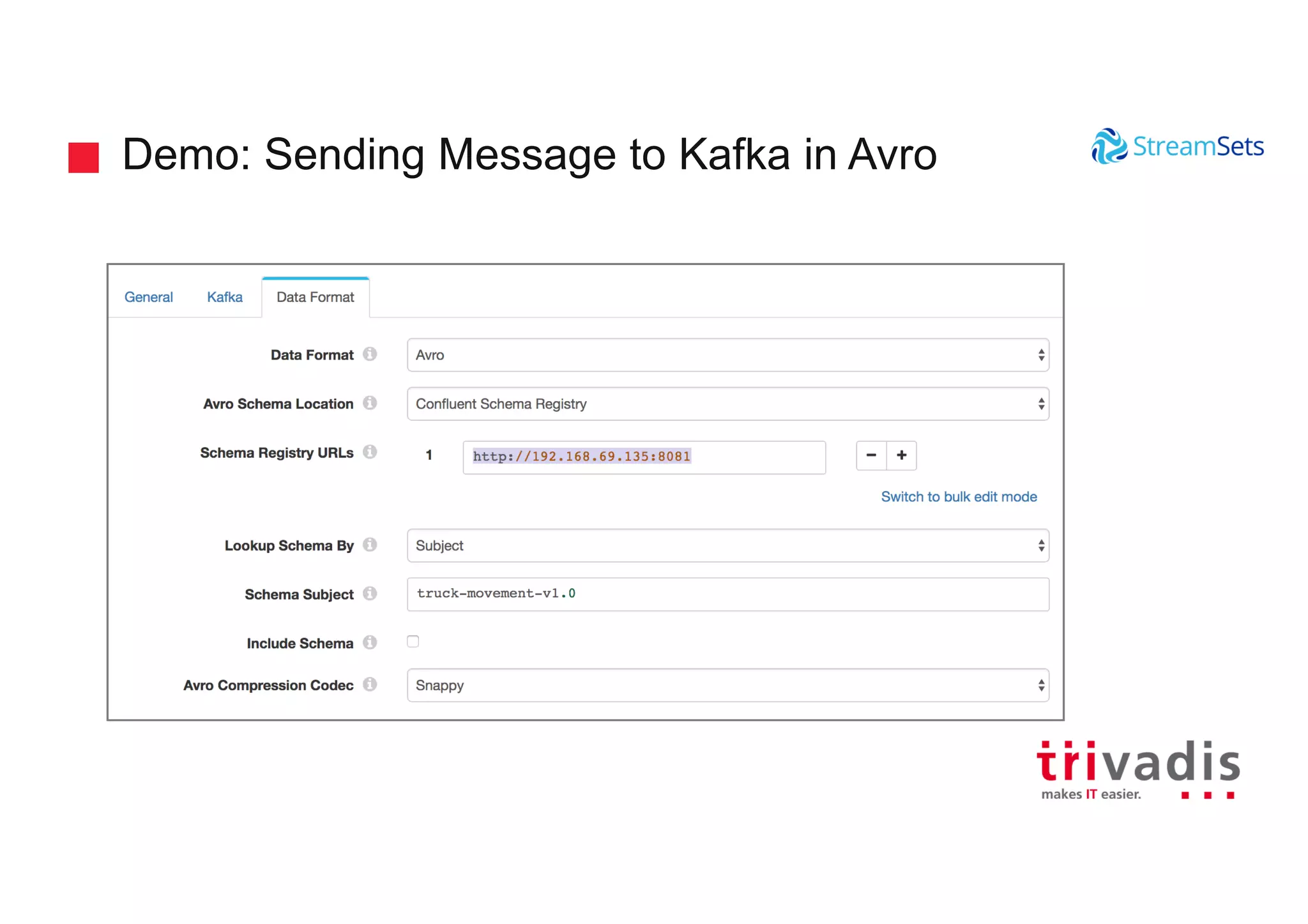
Demonstrations showcasing data ingestion concepts within StreamSets including MQTT and Kafka integration.
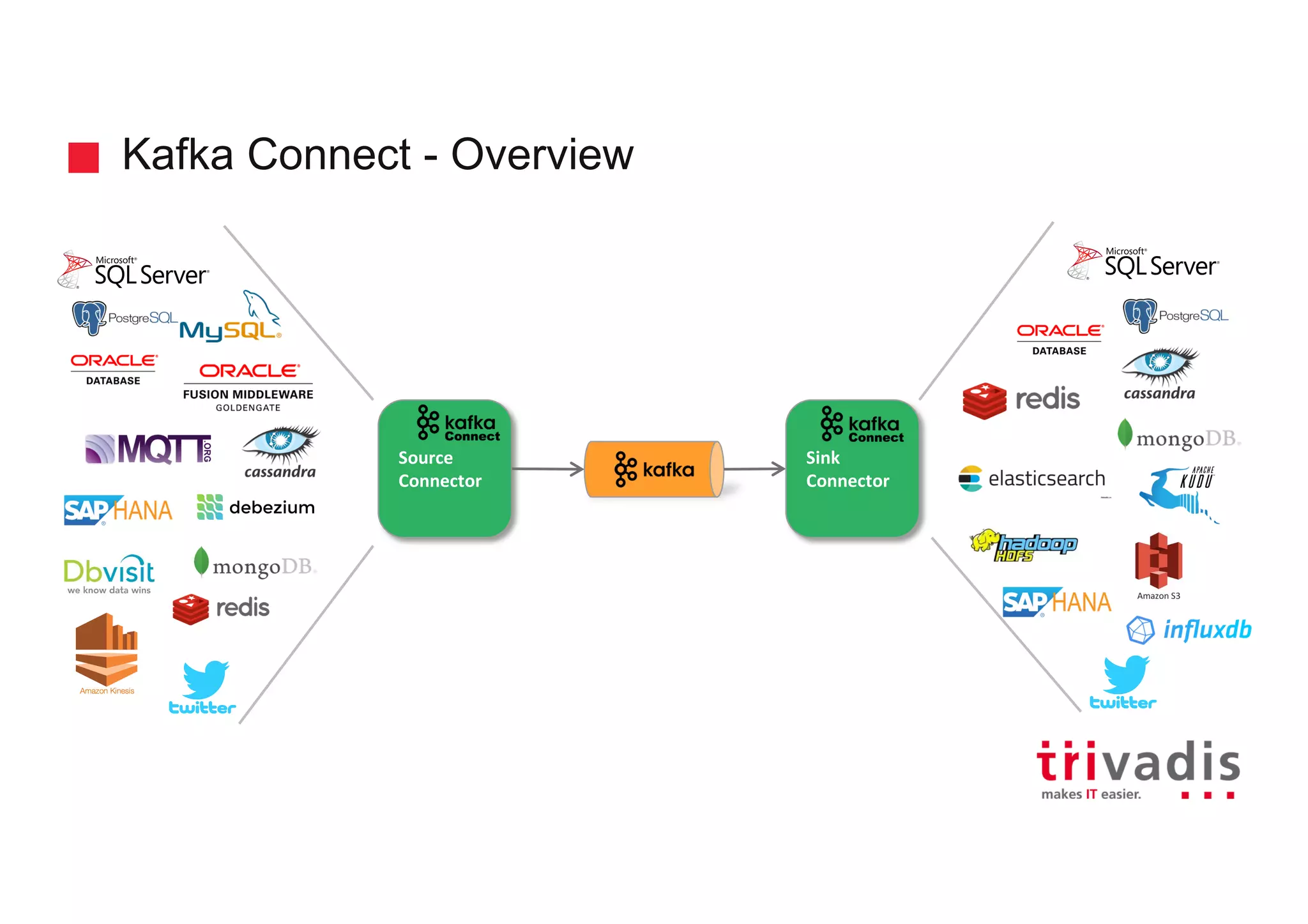
Overview of Kafka Connect, its architecture, source and sink connectors, and transformation functionality.
Demonstration of configuring and using Kafka Connect for streaming data workflows.
Comparative summary of Apache NiFi, StreamSets, and Kafka Connect addressing their strengths and functions.
Final reflection on the importance of correctly utilizing technology for effective data management.














![[DSC Europe 22] Overview of the Databricks Platform - Petar Zecevic](https://cdn.slidesharecdn.com/ss_thumbnails/petarzecevic-databricksoverview-221130080703-c60d93de-thumbnail.jpg?width=640&height=640&fit=bounds)























































![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)














