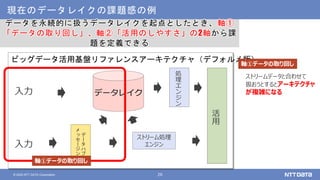
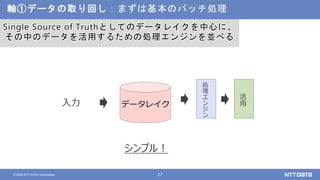
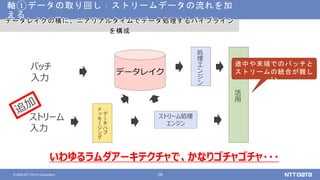
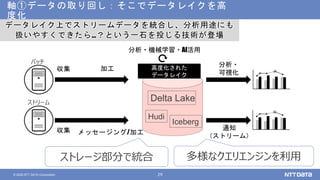
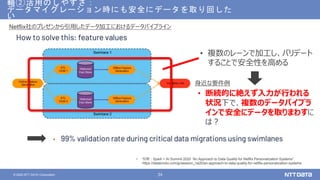
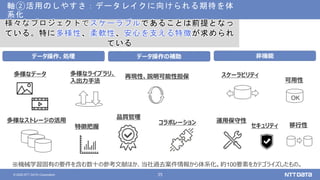
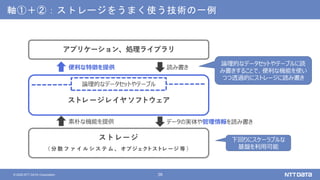
NTTデータが考えるデータ基盤の次の一手 ~AI活用のために知っておくべき新潮流とは?~ (NTTデータ テクノロジーカンファレンス 2020 発表資料) 2020年10月14日(水) NTTデータ システム技術本部 デジタル技術部 土橋 昌 講演動画は、YouTubeチャンネル「NTT DATA Tech」にて公開中! https://www.youtube.com/watch?v=gi9stEV45as




























































![[Oracle Innovation Summit Tokyo 2018] 水環境の持続を支えるクラウド型ICTプラットフォーム「Water Busine...](https://cdn.slidesharecdn.com/ss_thumbnails/ist18a-2-180822044642-thumbnail.jpg?width=640&height=640&fit=bounds)

























