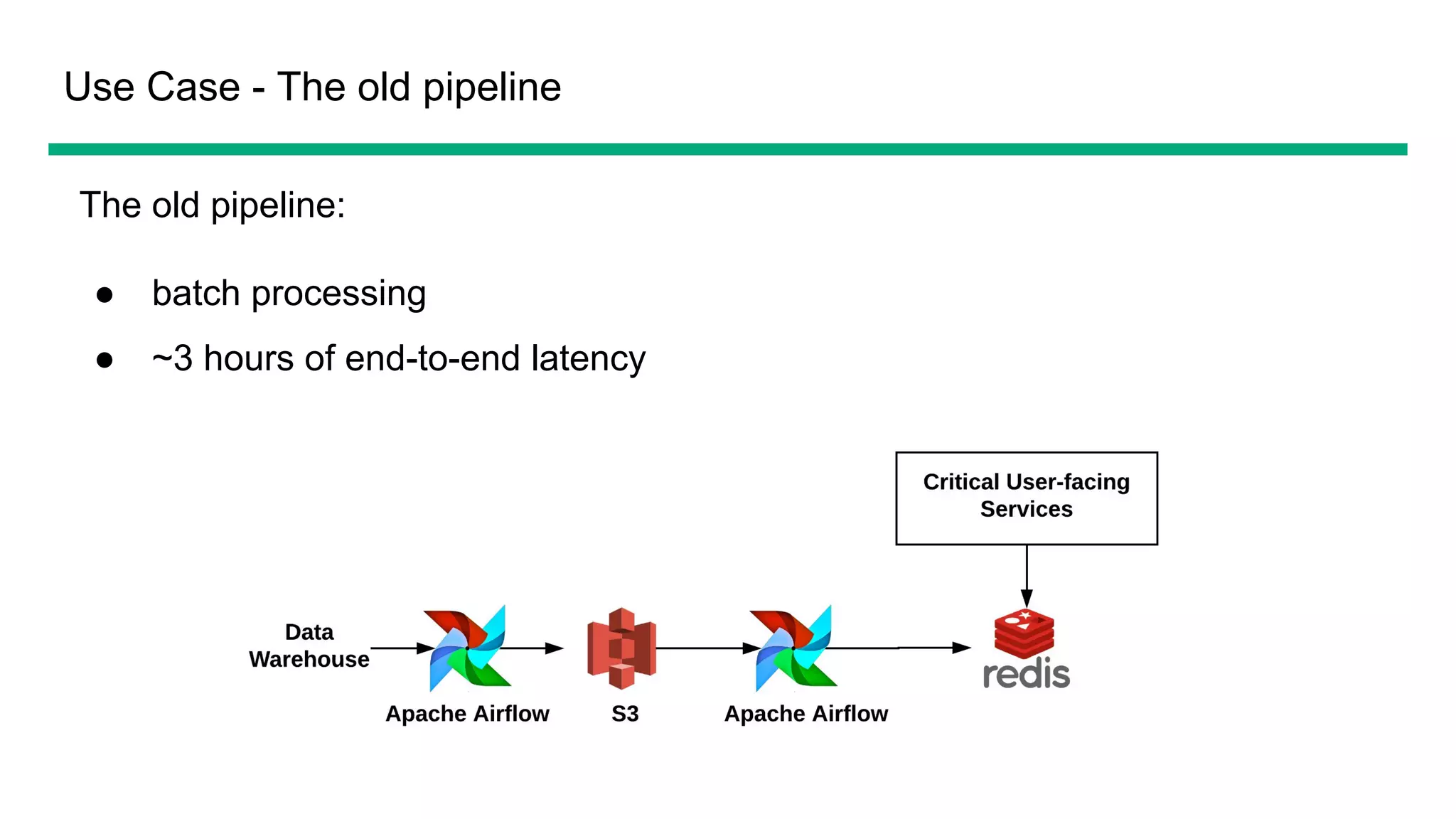
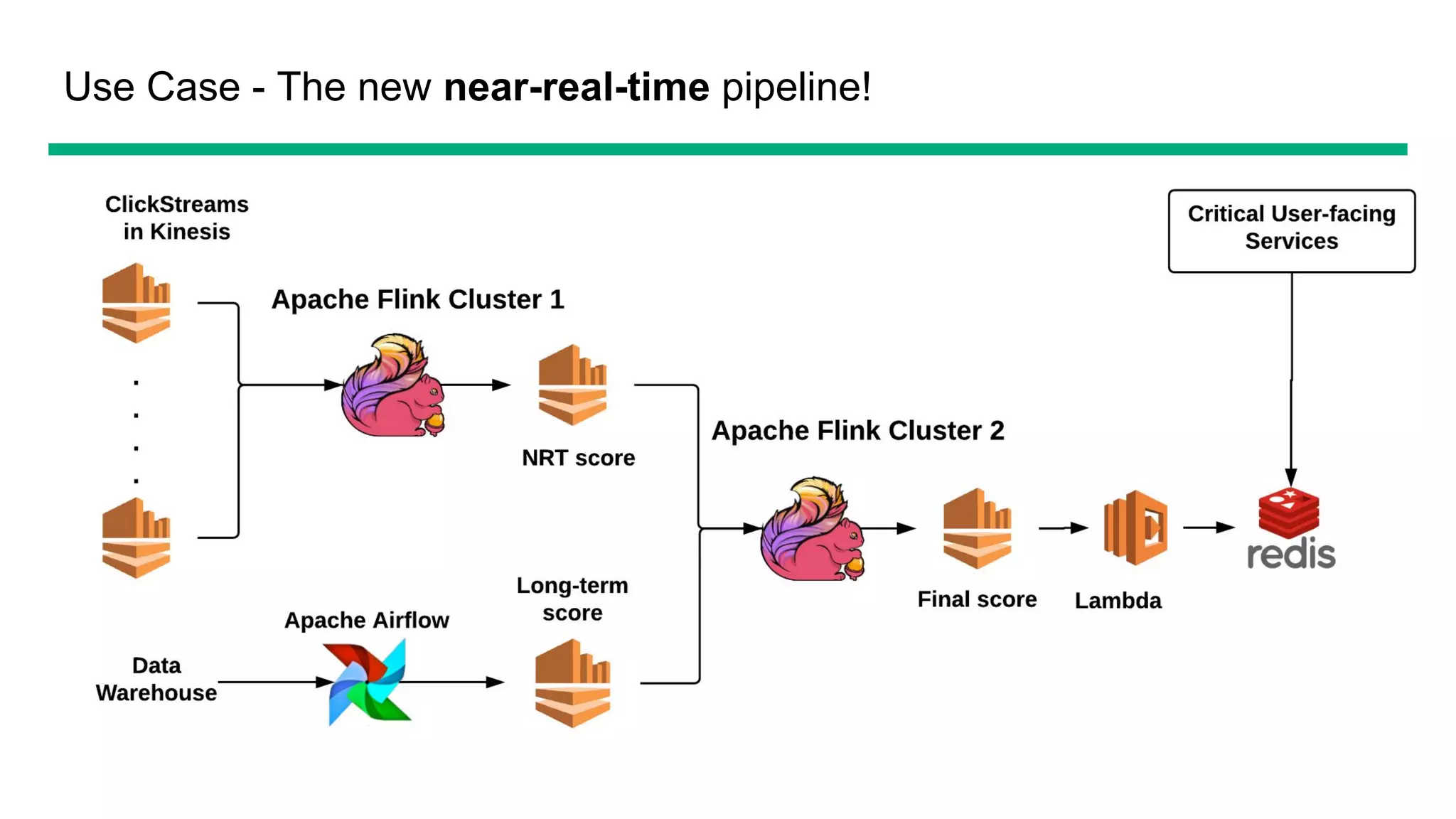
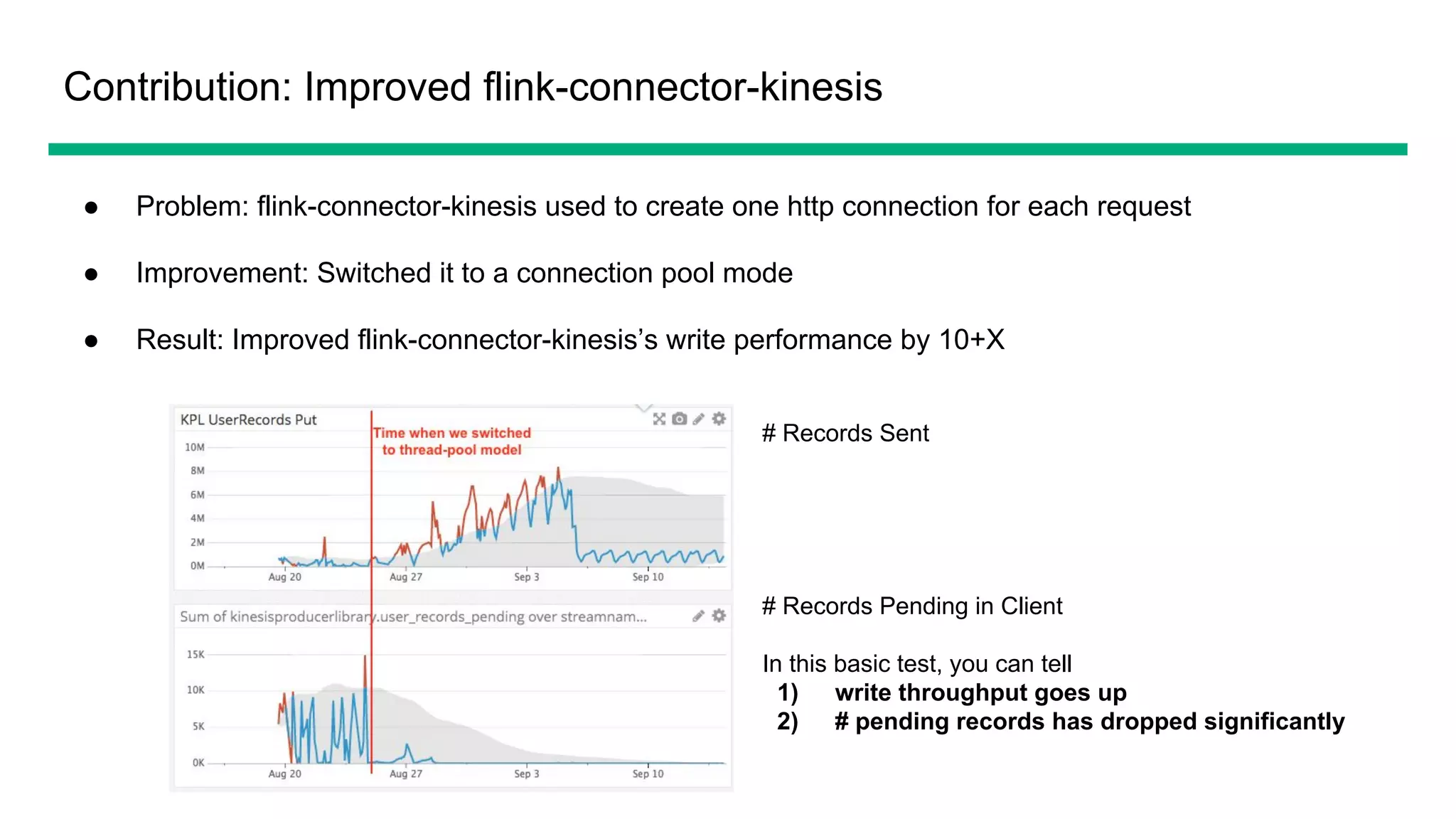
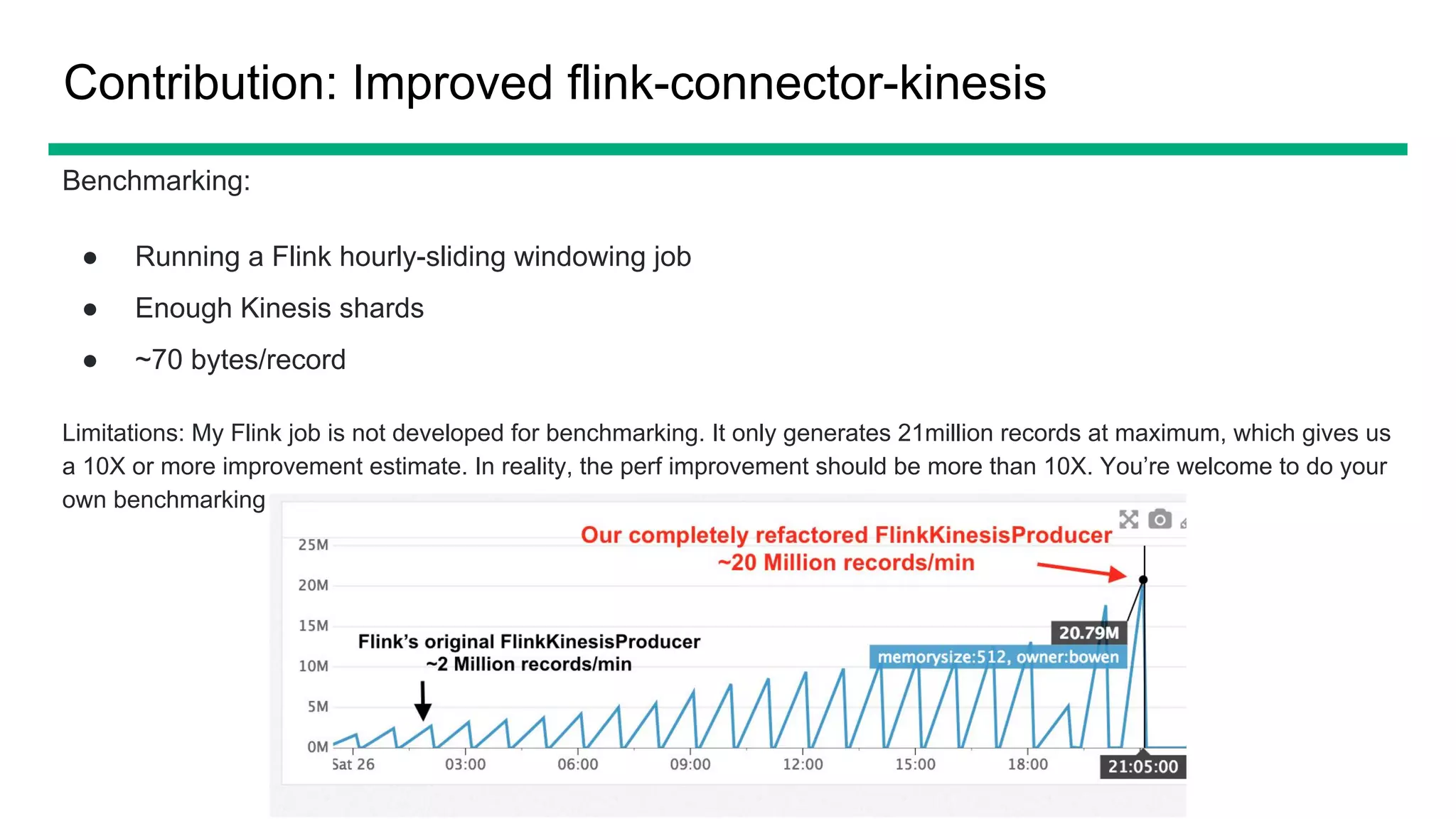
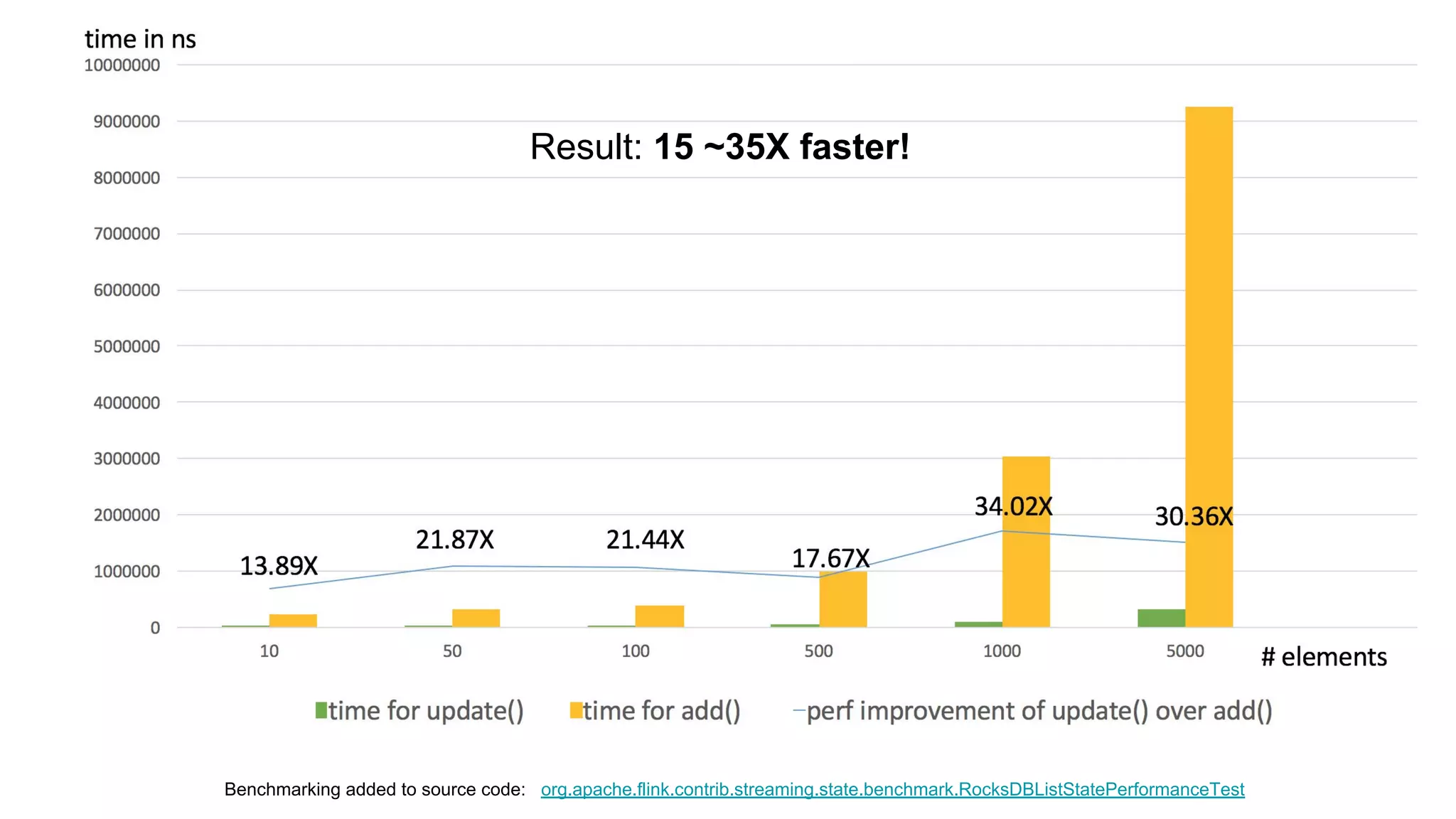
The document provides an overview of OfferUp's implementation of large-scale, near-real-time stream processing using Apache Flink, highlighting significant advancements in processing latency from approximately 3 hours to 1 minute. Key design considerations include data correctness, failure recovery, and replay capability, with contributions to Apache Flink documented, such as major performance improvements to the flink-connector-kinesis and flink's liststate APIs. The discussion also emphasizes the platform's handling of billions of records daily and the importance of efficient data processing in the context of personalized user experiences.



















































































![ANPARA THERMAL POWER STATION[1] sangam.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/anparathermalpowerstation1sangam-251121115219-9261cde4-thumbnail.jpg?width=640&height=640&fit=bounds)










