Download as PDF, PPTX






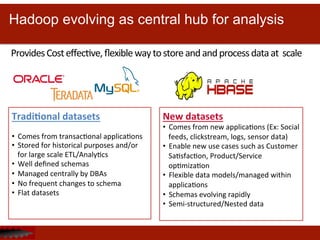
![Data landscape is changing
New
types
of
applica<ons
• Social,
mobile,
Web,
“Internet
of
Things”,
Cloud…
• IteraDve/Agile
in
nature
• More
users,
more
data
New
data
models
&
data
types
• Flexible
(schema-‐less)
data
• Rapidly
changing
• Semi-‐structured/Nested
data
{
"data":
[
"id":
"X999_Y999",
"from":
{
"name":
"Tom
Brady",
"id":
"X12"
},
"message":
"Looking
forward
to
2014!",
"acDons":
[
{
"name":
"Comment",
"link":
"hhp://www.facebook.com/X99/posts
Y999"
},
{
"name":
"Like",
"link":
"hhp://www.facebook.com/X99/posts
Y999"
}
],
"type":
"status",
"created_Dme":
"2013-‐08-‐02T21:27:44+0000",
"updated_Dme":
"2013-‐08-‐02T21:27:44+0000"
}
}
JSON](https://image.slidesharecdn.com/apachecon-forupload-140409160932-phpapp02/85/Building-Highly-Flexible-High-Performance-Query-Engines-6-320.jpg)
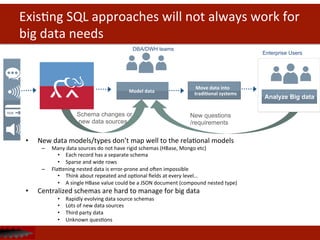

![Flexible
schema
management
{
“ID”:
1,
“NAME”:
“Fairmont
San
Francisco”,
“DESCRIPTION”:
“Historic
grandeur…”,
“AVG_REVIEWER_SCORE”:
“4.3”,
“AMENITY”:
{“TYPE”:
“gym”,
DESCRIPTION:
“fitness
center”
},
{“TYPE”:
“wifi”,
“DESCRIPTION”:
“free
wifi”},
“RATE_TYPE”:
“nightly”,
“PRICE”:
“$199”,
“REVIEWS”:
[“review_1”,
“review_2”],
“ATTRACTIONS”:
“Chinatown”,
}
JSON
ExisDng
SQL
soluDons
X
HotelID
AmenityID
1
1
1
2
ID
Type
Descrip
Don
1
Gym
Fitness
center
2
Wifi
Free
wifi](https://image.slidesharecdn.com/apachecon-forupload-140409160932-phpapp02/85/Building-Highly-Flexible-High-Performance-Query-Engines-10-320.jpg)
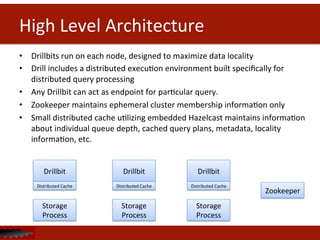
![Drill
{
“ID”:
1,
“NAME”:
“Fairmont
San
Francisco”,
“DESCRIPTION”:
“Historic
grandeur…”,
“AVG_REVIEWER_SCORE”:
“4.3”,
“AMENITY”:
{“TYPE”:
“gym”,
DESCRIPTION:
“fitness
center”
},
{“TYPE”:
“wifi”,
“DESCRIPTION”:
“free
wifi”},
“RATE_TYPE”:
“nightly”,
“PRICE”:
“$199”,
“REVIEWS”:
[“review_1”,
“review_2”],
“ATTRACTIONS”:
“Chinatown”,
}
JSON
Drill
Flexible
schema
management
HotelID
AmenityID
1
1
1
2
ID
Type
Descrip
Don
1
Gym
Fitness
center
2
Wifi
Free
wifi
Drill
doesn’t
require
any
schema
defini<ons
to
query
data
making
it
faster
to
get
insights
from
data
for
users.
Drill
leverages
schema
defini<ons
if
exists.](https://image.slidesharecdn.com/apachecon-forupload-140409160932-phpapp02/85/Building-Highly-Flexible-High-Performance-Query-Engines-11-320.jpg)











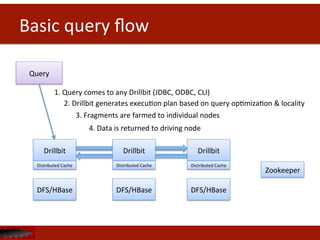




![Data
Format
Example
Donut
Price
Icing
Bacon
Maple
Bar
2.19
[Maple
FrosDng,
Bacon]
Portland
Cream
1.79
[Chocolate]
The
Loop
2.29
[Vanilla,
Fruitloops]
Triple
Chocolate
PenetraDon
2.79
[Chocolate,
Cocoa
Puffs]
Record
Encoding
Bacon
Maple
Bar,
2.19,
Maple
FrosDng,
Bacon,
Portland
Cream,
1.79,
Chocolate
The
Loop,
2.29,
Vanilla,
Fruitloops,
Triple
Chocolate
PenetraDon,
2.79,
Chocolate,
Cocoa
Puffs
Columnar
Encoding
Bacon
Maple
Bar,
Portland
Cream,
The
Loop,
Triple
Chocolate
PenetraDon
2.19,
1.79,
2.29,
2.79
Maple
FrosDng,
Bacon,
Chocolate,
Vanilla,
Fruitloops,
Chocolate,
Cocoa
Puffs](https://image.slidesharecdn.com/apachecon-forupload-140409160932-phpapp02/85/Building-Highly-Flexible-High-Performance-Query-Engines-31-320.jpg)








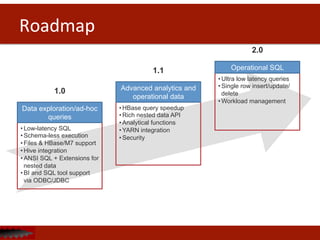



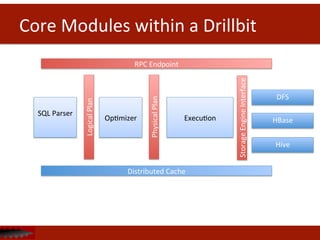
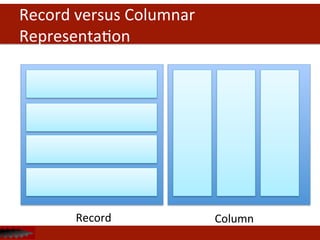
The document discusses Apache Drill, an open source SQL query engine for analysis of data in Hadoop. It provides an overview of Drill, highlighting its ability to handle flexible schemas, analyze semi-structured and nested data from NoSQL sources, and integrate with existing business intelligence tools through a familiar SQL interface. The document also notes that traditional SQL approaches do not always work well for new big data applications and data models, and that Drill aims to address these challenges.



![[PASS Summit 2016] Azure DocumentDB: A Deep Dive into Advanced Features](https://cdn.slidesharecdn.com/ss_thumbnails/passdocdbadvfeatures-161029023827-thumbnail.jpg?width=640&height=640&fit=bounds)


































































































