Download as PDF, PPTX











![DATA SAMPLE
INPUT (input.json)
{
"created_at":"Wed Aug 22 02:06:33 +0000 2012",
"entities":{
"hashtags":[
{
"indices":[103,111],
"text":"Angular"
}
],
"symbols":[],
"urls":[
{
"display_url":"buff.ly/2sr60pf",
"expanded_url":"http://buff.ly/2sr60pf",
"indices":[79,102],
"url":"https://t.co/xFox78juL1"
}
],
"user_mentions":[]
},
"favourites_count":57,
"followers_count":2145,
"friends_count":18,
"id":877994604561387500,
"id_str":"877994604561387520",
"listed_count":328,
"protected":false,
"source":"<a href="http://bufferapp.com" rel="nofollow">Buffer</a>",
"text":"Creating a Grocery List Manager Using Angular, Part 1: Add & Display Items https://t.co/xFox78juL1 #Angular",
"time_zone":"Wellington",
"truncated":false,
"user":{
"description":"Keep up with JavaScript tutorials, tips, tricks and articles at SitePoint.",
"id":772682964,
"id_str":"772682964",
"location":"Melbourne, Australia",
"name":"SitePoint JavaScript",
"screen_name":"SitePointJS",
"url":"http://t.co/cCH13gqeUK"
},
"utc_offset":43200
}
SIMPLE???? LET’zzzz see for more SAMPLE DATASETS
The below sample only shows nested complexity of json data.](https://image.slidesharecdn.com/jsontohiveschemagenerator-181220100107/85/Json-to-hive_schema_generator-12-320.jpg)

![SAMPLE EXAMPLE
INPUT (twitterInput.json)
{
"created_at":"Wed Aug 22 02:06:33 +0000 2012",
"entities":{
"hashtags":[
{
"indices":[103,111],
"text":"Angular"
}
],
"symbols":[],
"urls":[
{
"display_url":"buff.ly/2sr60pf",
"expanded_url":"http://buff.ly/2sr60pf",
"indices":[79,102],
"url":"https://t.co/xFox78juL1"
}
],
"user_mentions":[]
},
"favourites_count":57,
"followers_count":2145,
"friends_count":18,
"id":877994604561387500,
"id_str":"877994604561387520",
"listed_count":328,
"protected":false,
"source":"<a href="http://bufferapp.com" rel="nofollow">Buffer</a>",
"text":"Creating a Grocery List Manager Using Angular, Part 1: Add & Display Items https://t.co/xFox78juL1 #Angular",
"time_zone":"Wellington",
"truncated":false,
"user":{
"description":"Keep up with JavaScript tutorials, tips, tricks and articles at SitePoint.",
"id":772682964,
"id_str":"772682964",
"location":"Melbourne, Australia",
"name":"SitePoint JavaScript",
"screen_name":"SitePointJS",
"url":"http://t.co/cCH13gqeUK"
},
"utc_offset":43200
}](https://image.slidesharecdn.com/jsontohiveschemagenerator-181220100107/85/Json-to-hive_schema_generator-14-320.jpg)



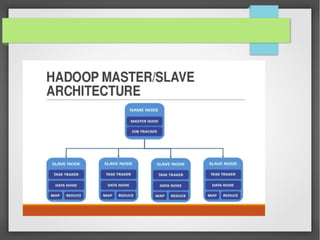
The document discusses the significance of big data and introduces Hadoop's ecosystem, particularly its core components like HDFS and MapReduce. It also provides an overview of Apache Hive, focusing on its ability to analyze large datasets and utilize JSON data through a schema generator tool designed to simplify handling complex JSON structures. Challenges of managing semi-structured JSON data and the tool's role in generating Hive schemas efficiently are highlighted, showcasing its value in big data processing.

















![[124]네이버에서 사용되는 여러가지 Data Platform, 그리고 MongoDB](https://cdn.slidesharecdn.com/ss_thumbnails/124mongodb-181011042943-thumbnail.jpg?width=640&height=640&fit=bounds)
![Naver속도의, 속도에 의한, 속도를 위한 몽고DB (네이버 컨텐츠검색과 몽고DB) [Naver]](https://cdn.slidesharecdn.com/ss_thumbnails/naver-190916181334-thumbnail.jpg?width=640&height=640&fit=bounds)




































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)











