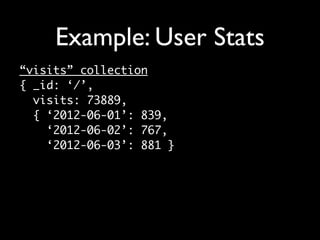
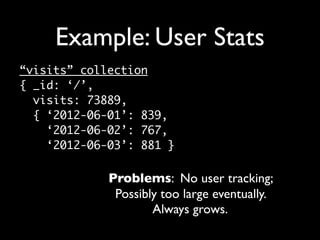
The document discusses schema design considerations for modeling data in MongoDB. It notes that while MongoDB is schemaless, applications are still responsible for schema design. It compares relational and MongoDB schema designs, highlighting that MongoDB uses embedded documents, has no joins, and requires duplicating or precomputing data. The document provides recommendations like combining related objects, optimizing for specific use cases, and doing aggregation work during writes rather than reads.