



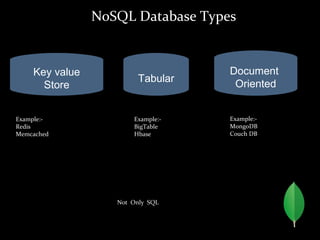










![var p ={"_id" : ObjectId("5915523a101c77bf2ffbc642"),
"author" : DBRef("author", "5126bc054aed4daf9e2ab772"),
"title" : "Introduction to MongoDB",
"body" : "MongoDB ",
"timestamp" : "01-04-12",
"tags" : [ "MongoDB", "NoSQL"],
"comments" : [{
"author" : DBRef("author",
– "5126bc054aed4daf9e2ab772"),
"date" : "02-04-12",
"text" : "Did you see.. ",
"upvotes" : 7
}]
}
> db.posts.save(p);
Understanding the Document Model.](https://image.slidesharecdn.com/mongodb-presentationfinal-180308122515/85/Mongo-Bb-NoSQL-tutorial-22-320.jpg)



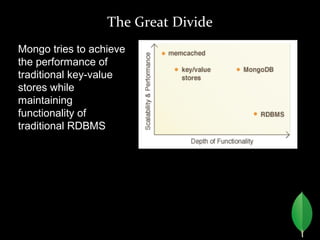
![Where, Join, Group By
!=”A” {$ne:”A”}
>25 {$gt:25}
>25 AND <=50 {$gt:25, $lte:50}
Like 'bc%' /^bc/
<25 OR >=50 {$or: [{$lt:25}, {$gte:50}]}
Join:-
Wrong Place...
Or Map Reduce](https://image.slidesharecdn.com/mongodb-presentationfinal-180308122515/85/Mongo-Bb-NoSQL-tutorial-26-320.jpg)











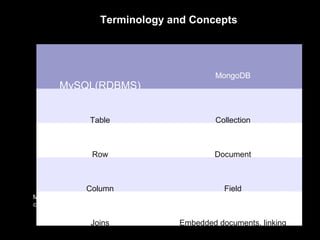
![// find posts which has ‘MongoDB’ tag.
> db.posts.find({tags: ‘MongoDB’});
// find posts by author’s comments.
> db.posts.find({‘comments.author’:
DBRef(‘User’,2)}).count();
// find posts written after 31st
March.
> db.posts.find({‘timestamp’: {‘gte’: Date(’31-03-12’)}});
// find posts written by authors around [22, 42]
> db.posts.find({‘author.location’: {‘near’:[22, 42]});
What about Queries? So Simple
$gt, $lt, $gte, $lte, $ne, $all, $in, $nin, count, limit, skip, group, etc…](https://image.slidesharecdn.com/mongodb-presentationfinal-180308122515/85/Mongo-Bb-NoSQL-tutorial-42-320.jpg)
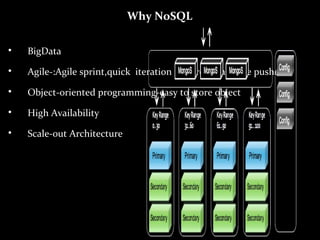

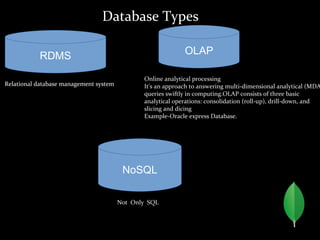
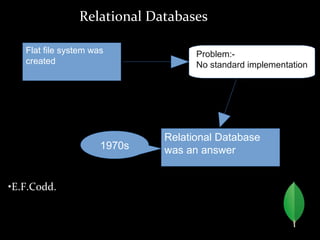
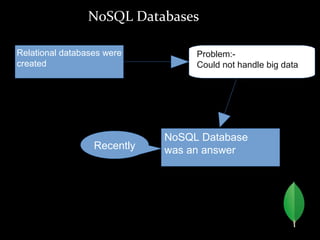
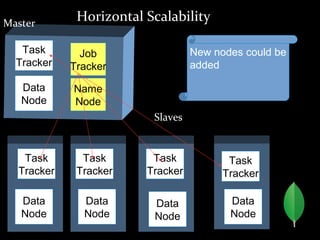
MongoDB is a horizontally scalable, schema-free, document-oriented NoSQL database. It stores data in flexible, JSON-like documents, allowing for easy storage and retrieval of data without rigid schemas. MongoDB provides high performance, high availability, and easy scalability. Some key features include embedded documents and arrays to reduce joins, dynamic schemas, replication and failover for availability, and auto-sharding for horizontal scalability.













































![nosql [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/nosqlautosaved-230721181148-0ee7f758-thumbnail.jpg?width=640&height=640&fit=bounds)





















