Download as PDF, PPTX




![JSON Example
{
"custkey":
"450002",
"useragent":
{
"devicetype":
"pc",
"experience":
"browser",
"platform":
"windows"
},
"pagetype":
"home",
"productline":
"television",
"customerprofile":
{
"age":
20,
"gender":
"male",
"customerinterests":
[
"movies",
"fashion",
"music"
]
}
}](https://image.slidesharecdn.com/datawranglers-meetup11-4final-151206143416-lva1-app6891/75/Analyzing-Semi-Structured-Data-At-Volume-In-The-Cloud-7-2048.jpg)



![Clickstream Example
{
"custkey":
"450002",
"useragent":
{
"devicetype":
"pc",
"experience":
"browser",
"platform":
"windows"
},
"pagetype":
"home",
"productline":
"none",
"customerprofile":
{
"age":
20,
"gender":
"male",
"customerinterests":
[
"movies",
"fashion",
"music"
]
}
}](https://image.slidesharecdn.com/datawranglers-meetup11-4final-151206143416-lva1-app6891/75/Analyzing-Semi-Structured-Data-At-Volume-In-The-Cloud-15-2048.jpg)
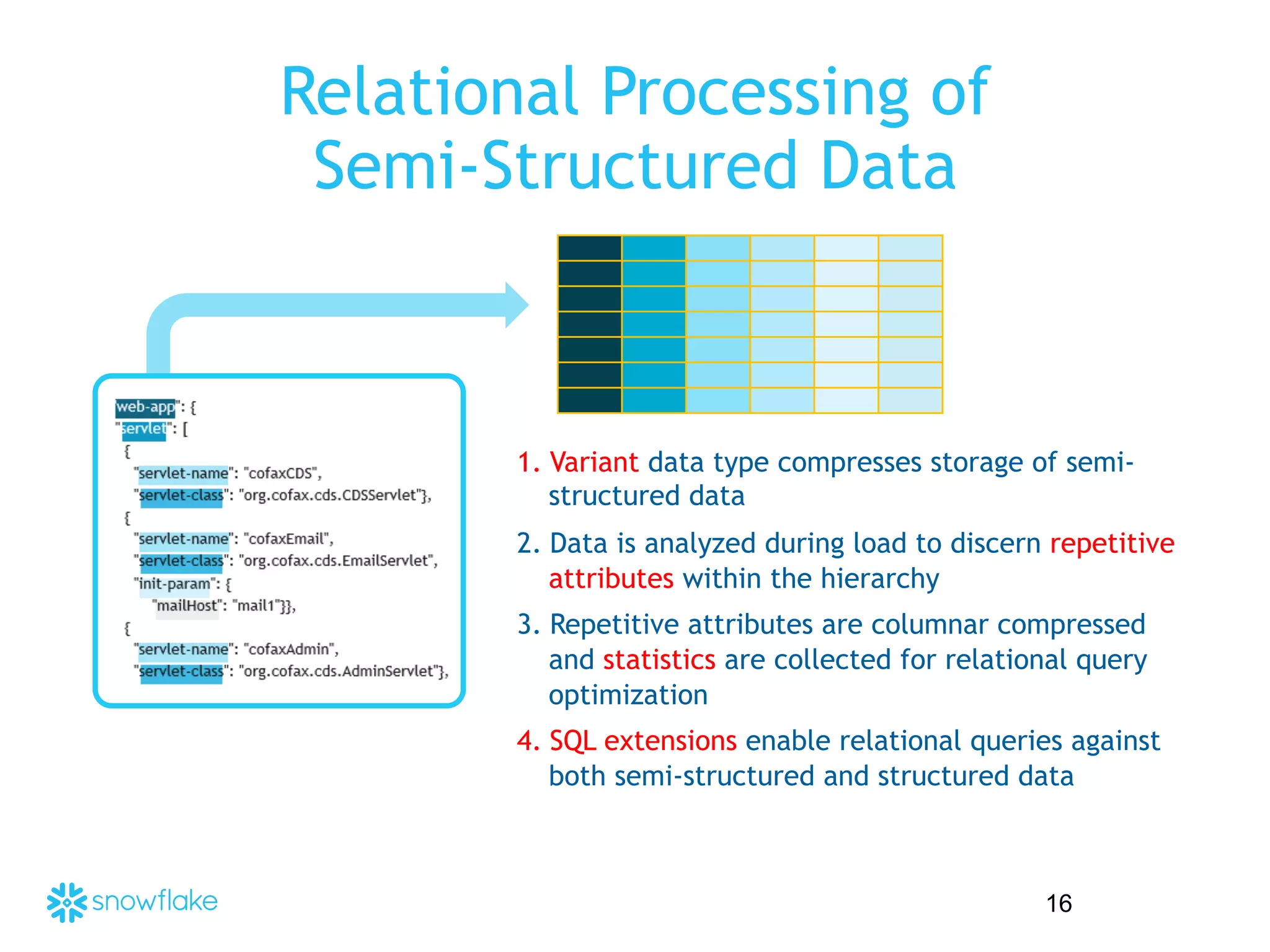


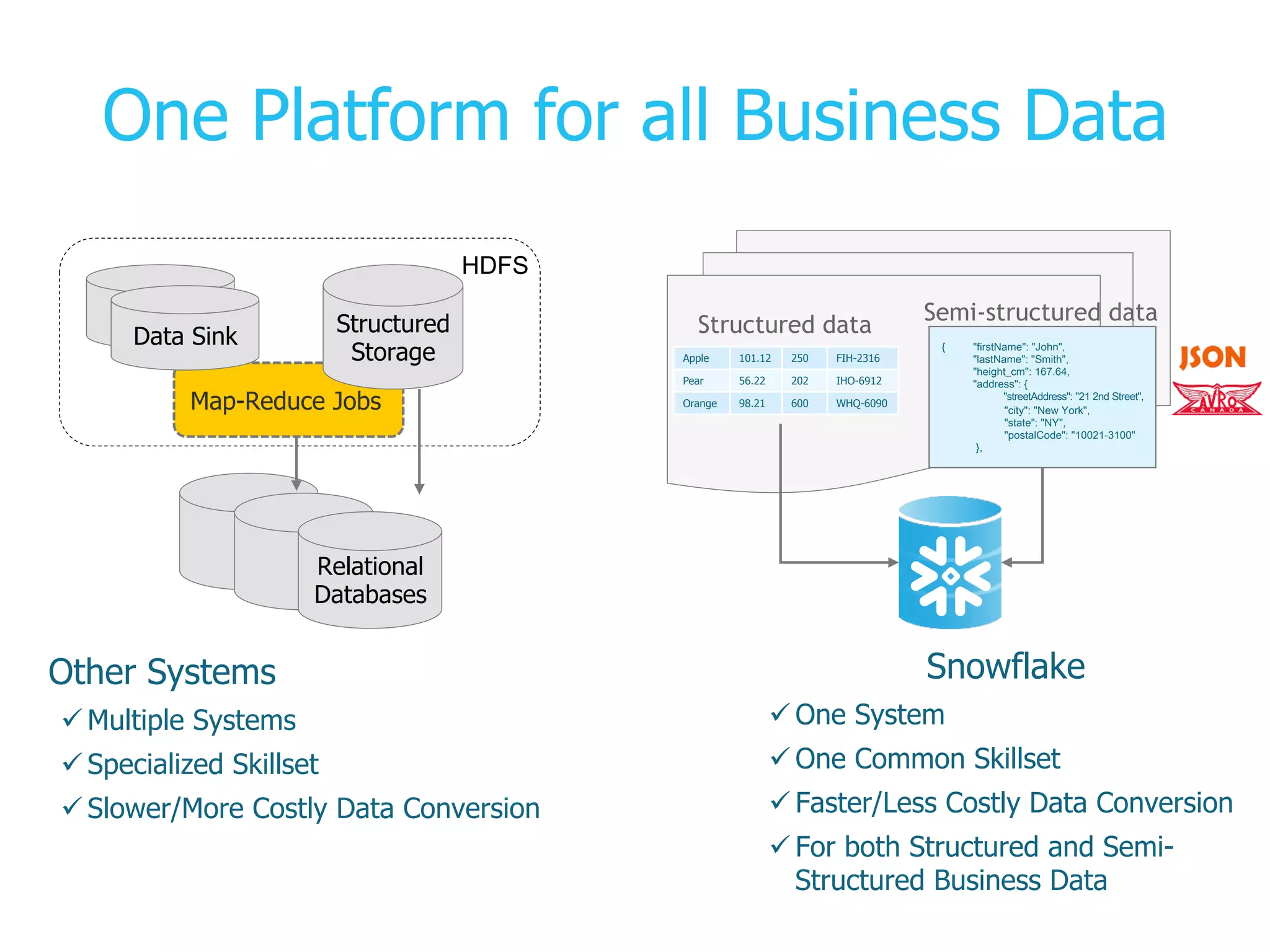


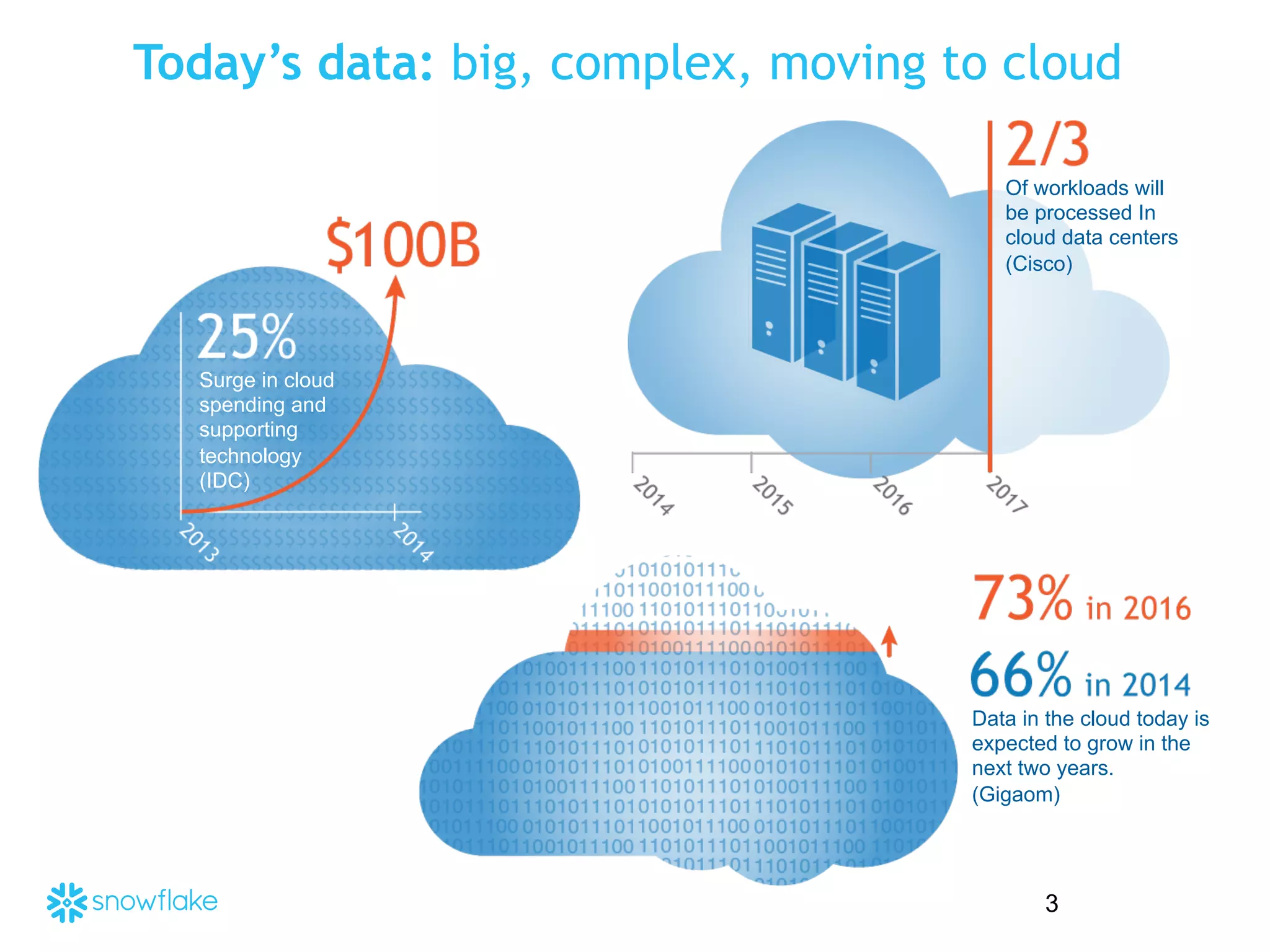
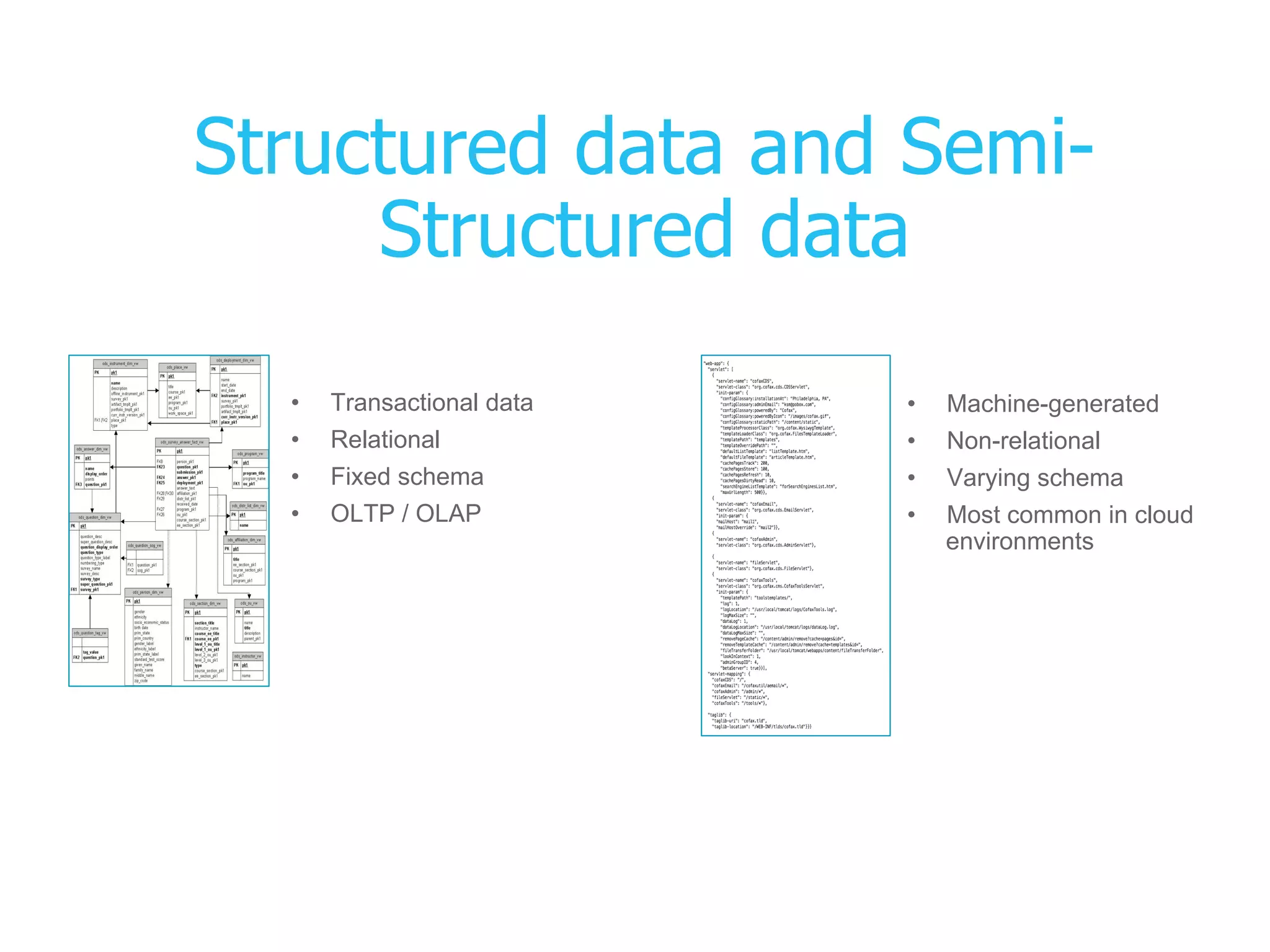
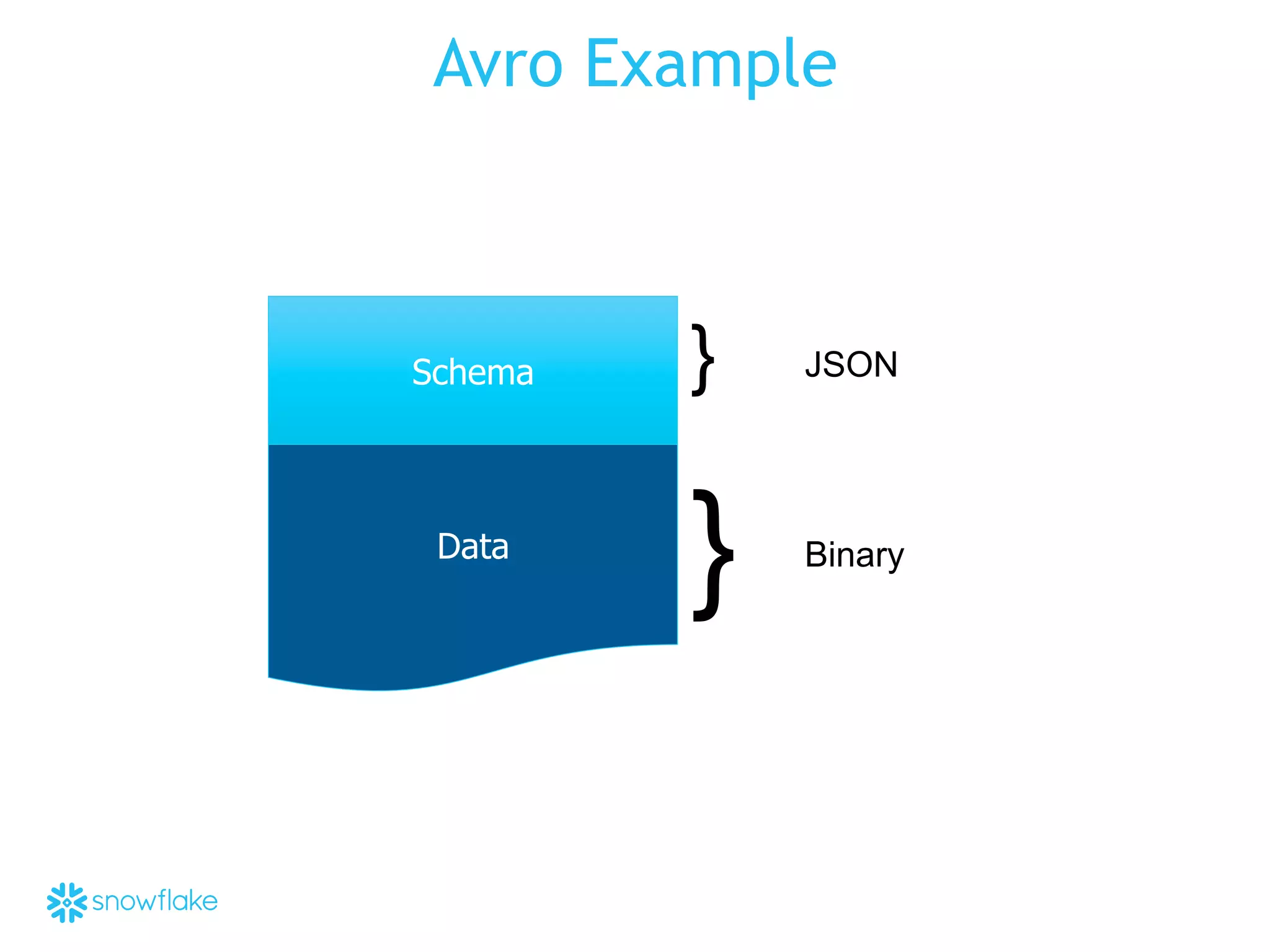
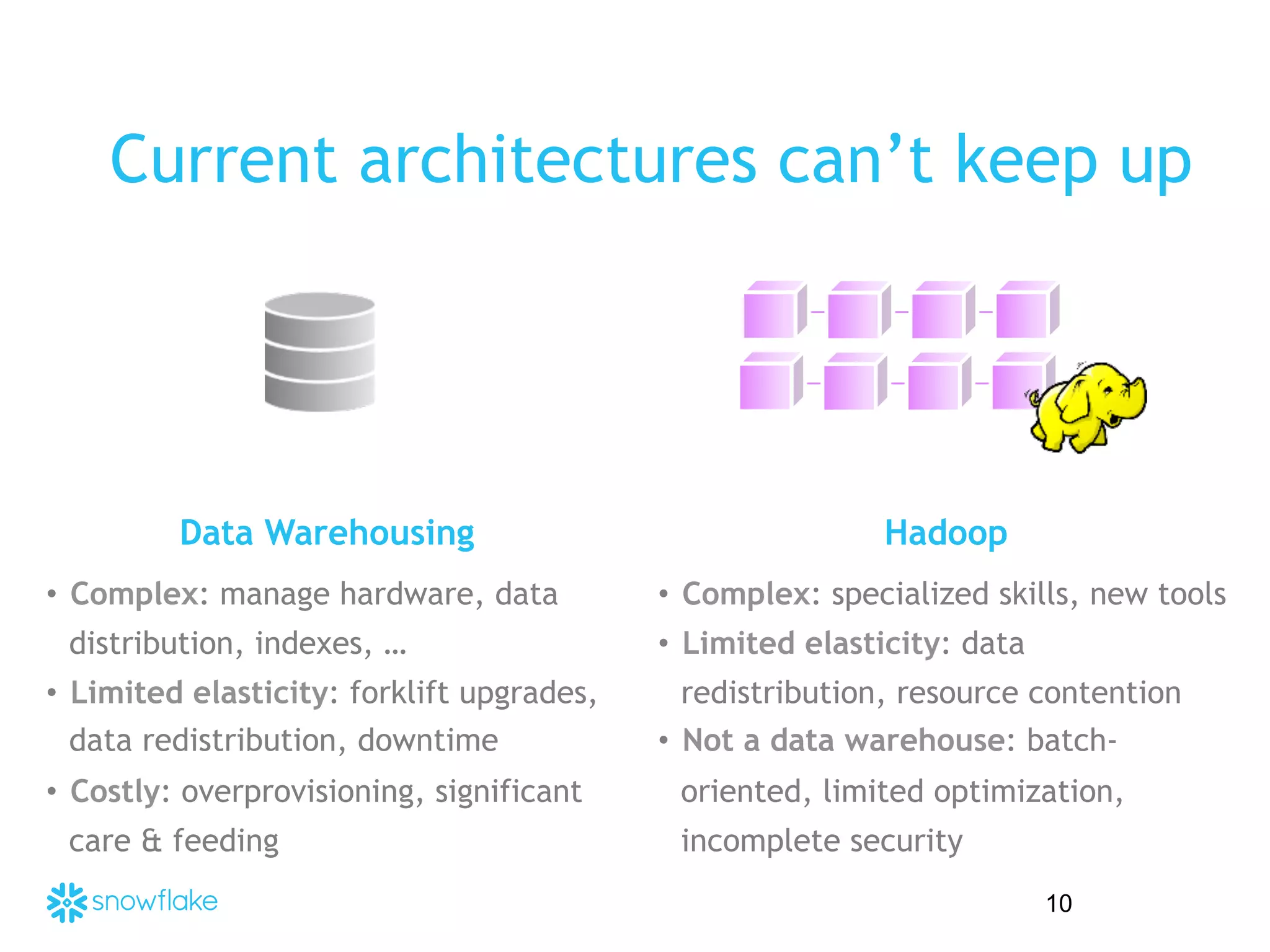
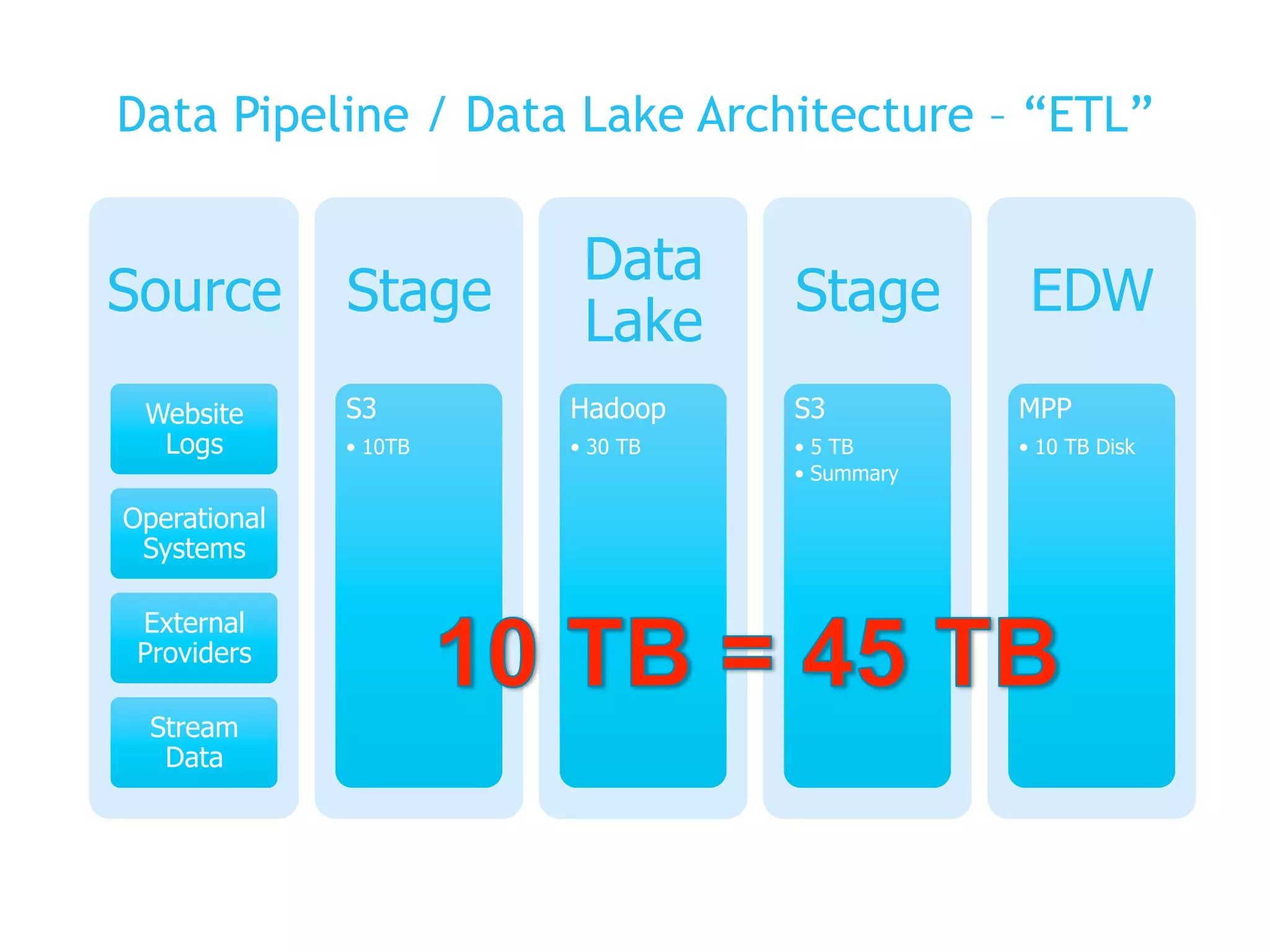
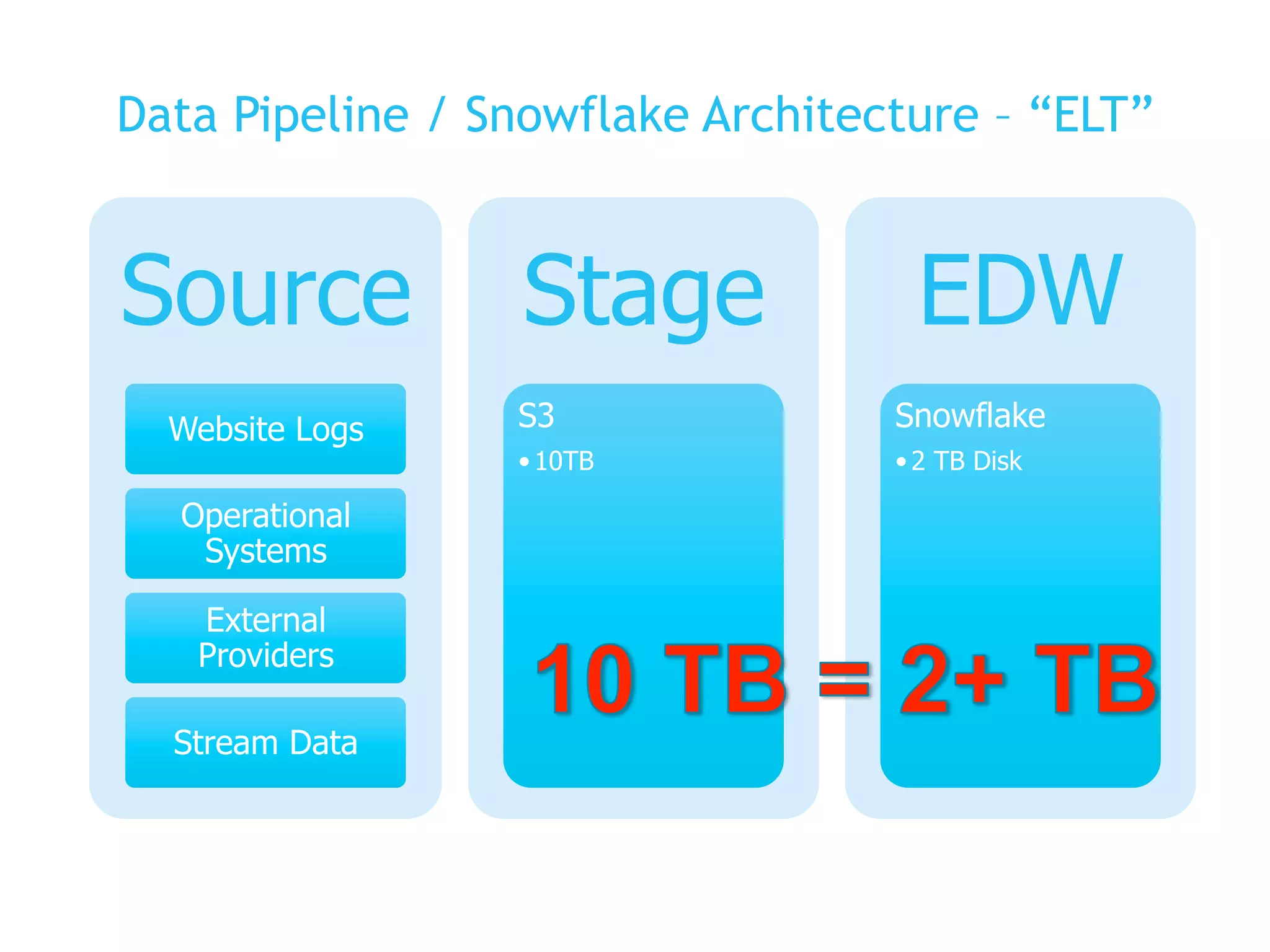
The presentation covers the analysis of semi-structured data in the cloud, highlighting the differences between structured and semi-structured data, and discussing ETL architectures. It demonstrates the challenges of traditional relational databases in handling such data and presents Snowflake's unique attributes for efficient processing, including compression and scalability. Two demo scenarios are provided: analyzing clickstream data and correlating social media metrics with sales.

















































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)
















