Stochastic Gradient Descent with Exponential Convergence Rates of Expected Classification Errors
The document presents two main results:
1) Stochastic Gradient Descent (SGD) achieves linear convergence rates for expected classification error under a strong low noise condition. The number of iterations needed for an epsilon solution is O(log(1/epsilon)).
2) Averaged SGD (ASGD) achieves even faster linear convergence rates under the same condition, requiring O(log(1/epsilon)) iterations for an epsilon solution.
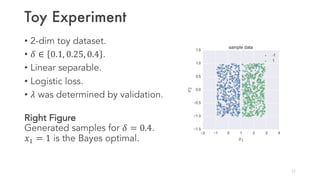
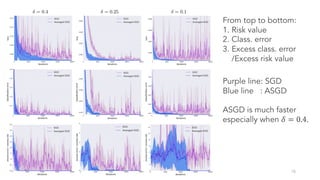
The results improve upon prior work by showing faster-than-sublinear convergence rates for more suitable loss functions like logistic loss. Toy experiments demonstrate the theoretical findings.



![Background
• Stochastic Gradient Descent (SGD)
Simple and effective method for training machine learning models.
Significantly faster than vanilla gradient descent.
• Convergence Rates
Expected risk: sublinear convergence 𝑂(1/𝑛&
), (𝛼 ∈ [1/2,1]).
Expected classification error: How fast dose it converge?
GD SGD
SGD: 𝑔/01 ← 𝑔/ − 𝜂𝐺6(𝑔/, 𝑍/) (𝑍/ ∼ 𝜌),
GD : 𝑔/01 ← 𝑔/ − 𝜂𝔼;<∼= 𝐺6 𝑔/, 𝑍/
Cost per iteration:
1 (SGD) vs #data examples (GD)
3](https://image.slidesharecdn.com/aistats2019-191109003401/85/Stochastic-Gradient-Descent-with-Exponential-Convergence-Rates-of-Expected-Classification-Errors-3-320.jpg)
![Background
Common way to bound classification error.
• Classification error bound via consistency of loss functions:
[T. Zhang(2004), P. Bartlett+(2006)]
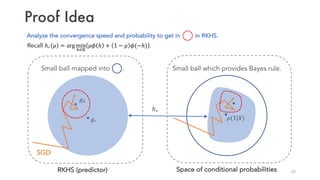
ℙ sgn 𝑔 𝑋 ≠ 𝑌 − ℙ sgn 2𝜌 1 𝑋 − 1 ≠ 𝑌 ≲ ℒ 𝑔 − ℒ∗
H
,
𝑔: predictor, ℒ∗: Bayes optimal for ℒ,
𝜌 1 𝑋 : conditional probability of label 𝑌 = 1.
𝑝 = 1/2 for logistic, exponential, and squared losses.
• Sublinear convergence 𝑂
1
KLM of excess classification error.
4
Excess classification error Excess risk](https://image.slidesharecdn.com/aistats2019-191109003401/85/Stochastic-Gradient-Descent-with-Exponential-Convergence-Rates-of-Expected-Classification-Errors-4-320.jpg)
![Background
Faster convergence rates of excess classification error.
• Low noise condition on 𝜌 𝑌 = 1 𝑋)
[A.B. Tsybakov(2004), P. Bartlett+(2006)]
improves the consistency property,
resulting in faster rates: 𝑂
1
K
. (still sublinear convergence)
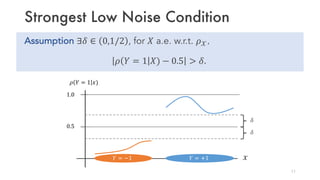
• Low noise condition (strongest version)
[V. Koltchinskii & O. Benzosova(2005), J-Y. Audibert & A.B. Tsybakov(2007)]
accelerates the rates for ERM to linear rates 𝑂 exp(−𝑛) .
5](https://image.slidesharecdn.com/aistats2019-191109003401/85/Stochastic-Gradient-Descent-with-Exponential-Convergence-Rates-of-Expected-Classification-Errors-5-320.jpg)
![Background
Faster convergence rates of excess classification error for SGD.
• Linear convergence rate
[L. Pillaud-Vivien, A. Rudi, & Francis Bach(2018)]
has been shown for the squared loss function under the strong low
noise condition.
• This work
shows the linear convergence for more suitable loss functions (e.g.,
logistic loss) under the strong low noise condition.
6](https://image.slidesharecdn.com/aistats2019-191109003401/85/Stochastic-Gradient-Descent-with-Exponential-Convergence-Rates-of-Expected-Classification-Errors-6-320.jpg)






















































![[ICLR2021 (spotlight)] Benefit of deep learning with non-convex noisy gradien...](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2021-210331133549-thumbnail.jpg?width=640&height=640&fit=bounds)














![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)











