Downloaded 106 times


![Analytics Use Case: Site Facing
select sum(pageView) from T
where memberId = 456,
pageKey = “profilePage”,
privacySettings in (…)
group by time,[title|geo|industry]
Pre-defined query format with different
primary key values
Use Case Response Latency Query Rate Possible Solutions
Site facing 100ms (99 percentile) 1000s qps KV Store](https://image.slidesharecdn.com/sigmod-final-180725033925/75/Pinot-Realtime-OLAP-for-530-Million-Users-Sigmod-2018-4-2048.jpg)
![Analytics Use Case: Anomaly Detection
for d1 in [us, ca, … ]
for d2 in [chrome, ie, … ]
…
select sum(pageView), time from T
where country = d1, browser = d2
group by time
Identifying all issues requires us to monitor
all possible combinations
Periodic machine generated queries (bursty)
Use Case Response Latency Query Rate Possible Solutions
Anomaly Detection
sub-second to
few seconds
10-100s qps Streaming Engine](https://image.slidesharecdn.com/sigmod-final-180725033925/75/Pinot-Realtime-OLAP-for-530-Million-Users-Sigmod-2018-5-2048.jpg)


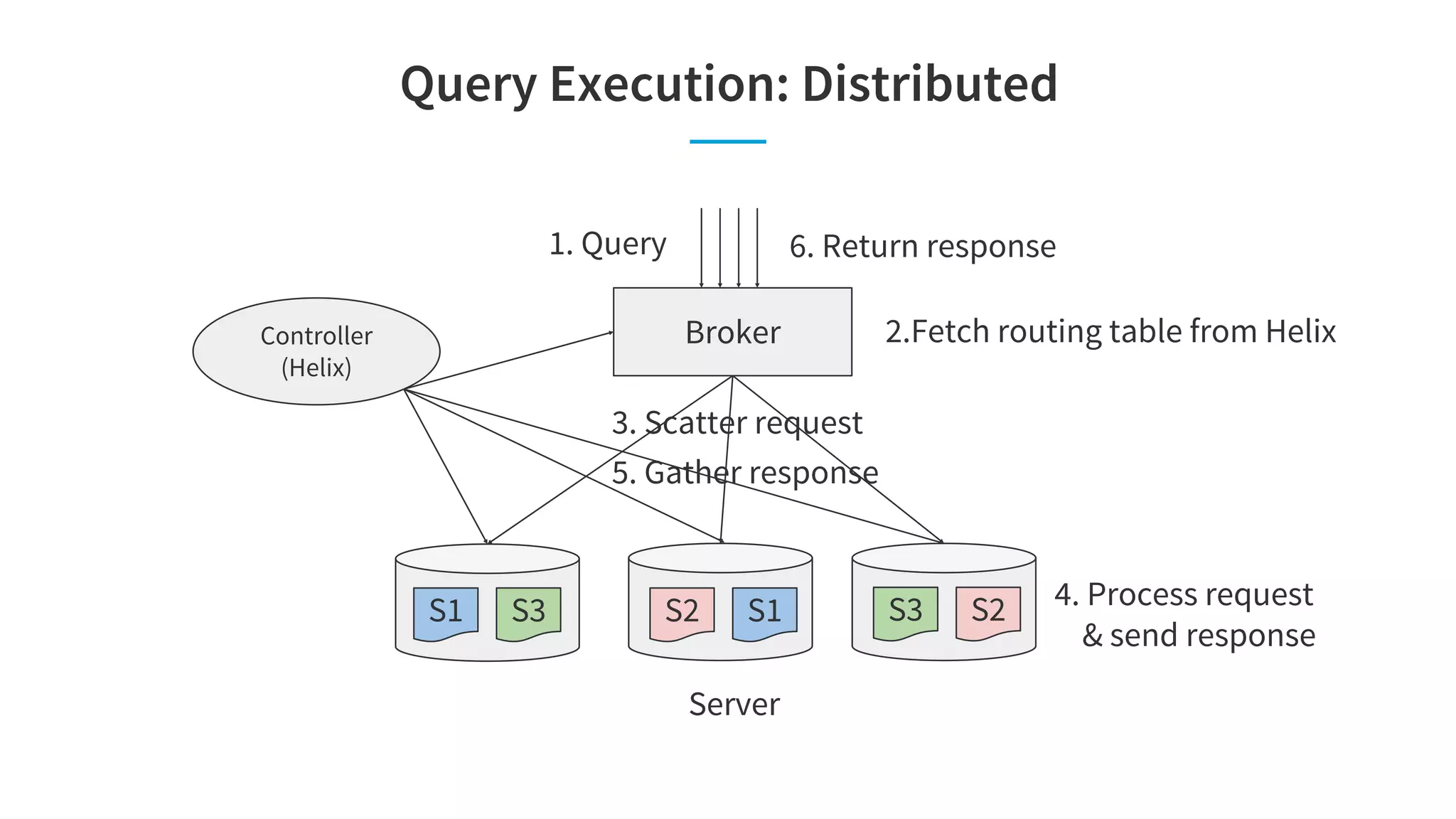
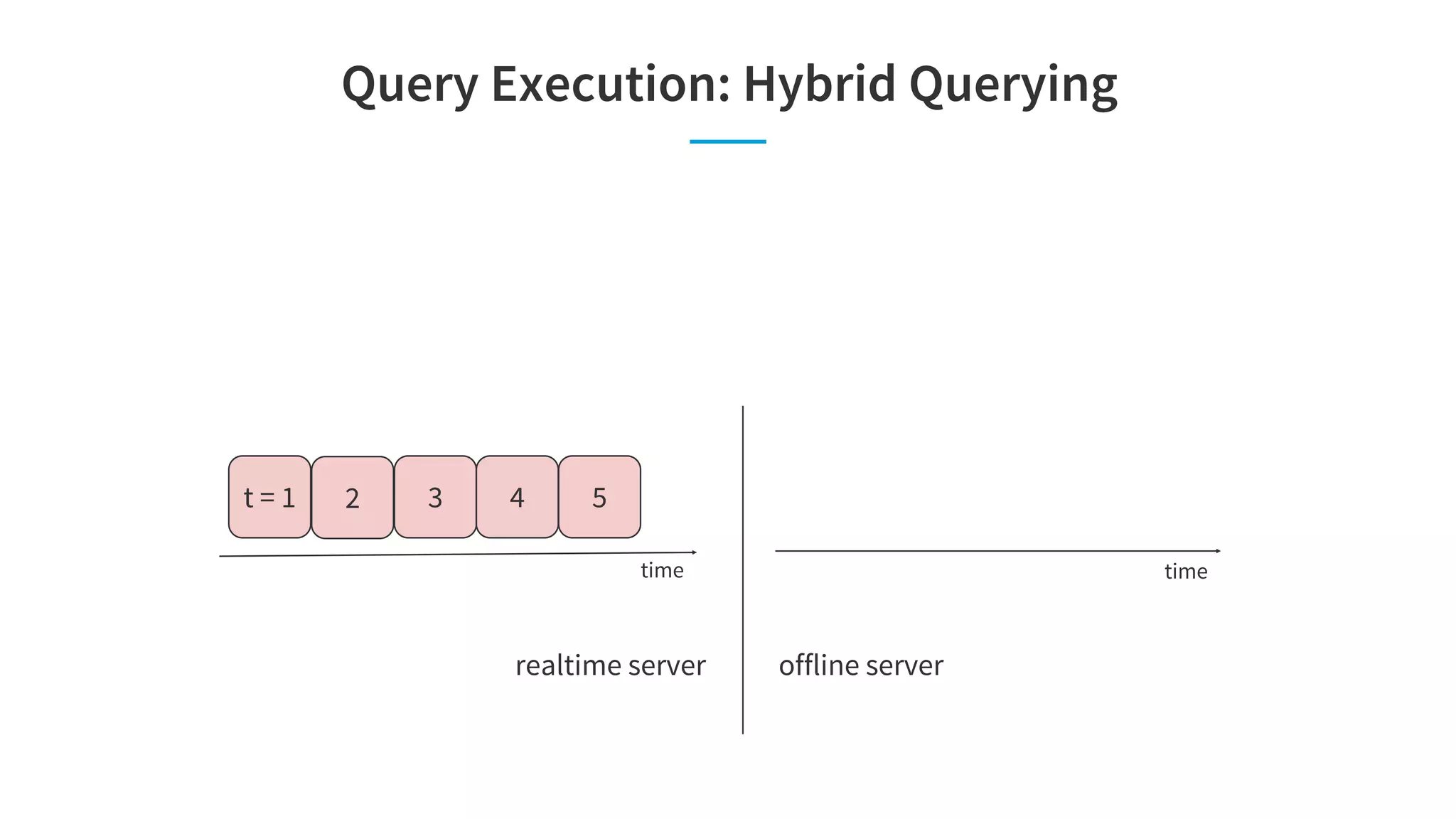
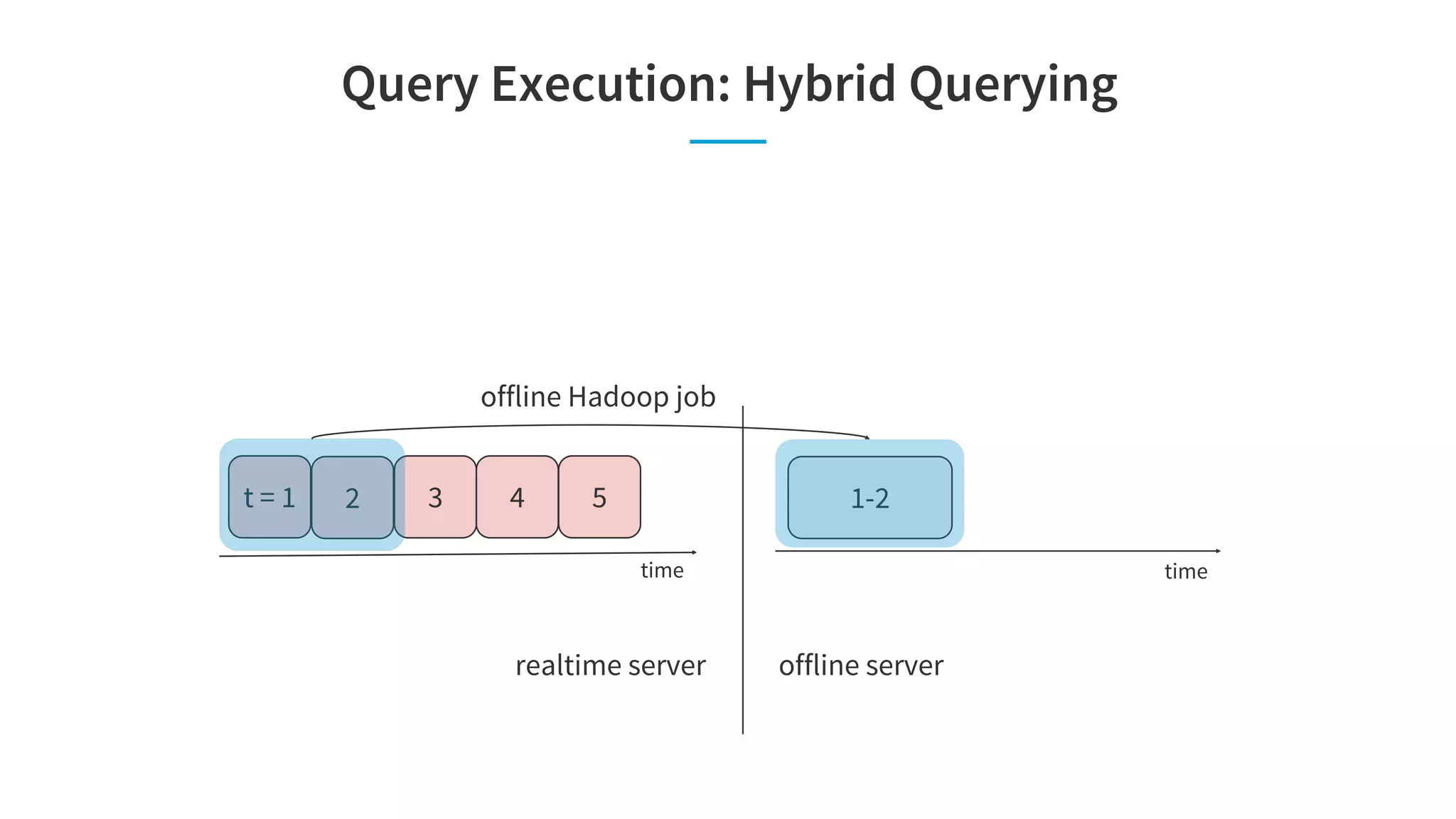
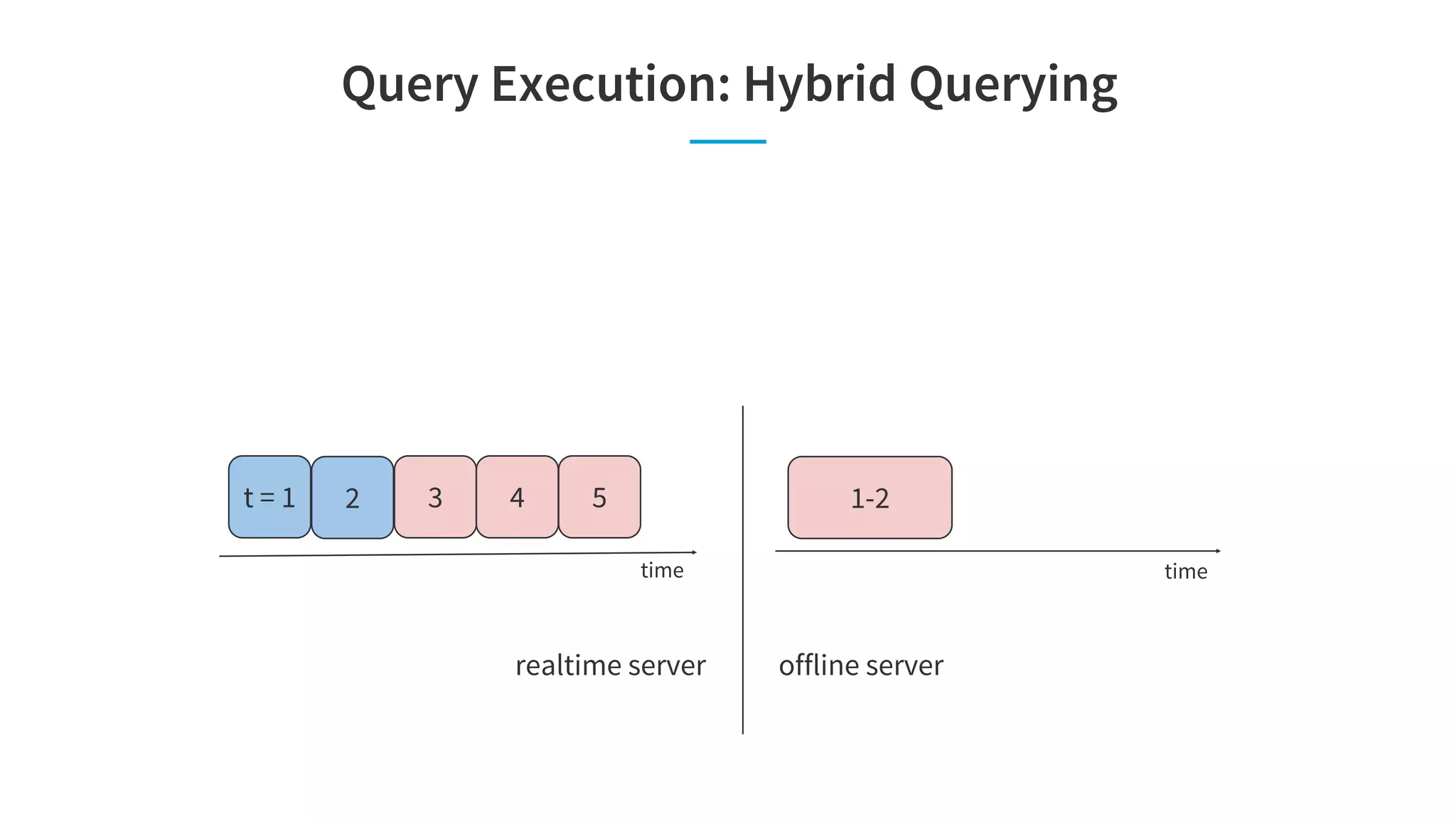
![Site Facing
Use Case Response Latency Query Rate Possible Solutions
Site facing 100ms (99 percentile) 1000s qps KV Store
select sum(pageView) from T
where memberId = xx, privacySettings in…
group by time,[title|geo|industry]
● ● ● ●
● ●
●●●●
● ● ● ●
● ●
●●●●
● ● ● ●
● ●
●● ●●100
1000
10000
10 1000
Queries per second
Latency(milliseconds)
druid
pinot
● ● ● ● ● ●●● ●●●●●
● ● ● ● ● ●●● ●●●●●
● ● ● ● ● ●●● ●●●●●
100
1000
10000
10 100 1000
Queries per second
Latency(milliseconds)
pinot
druid](https://image.slidesharecdn.com/sigmod-final-180725033925/75/Pinot-Realtime-OLAP-for-530-Million-Users-Sigmod-2018-23-2048.jpg)


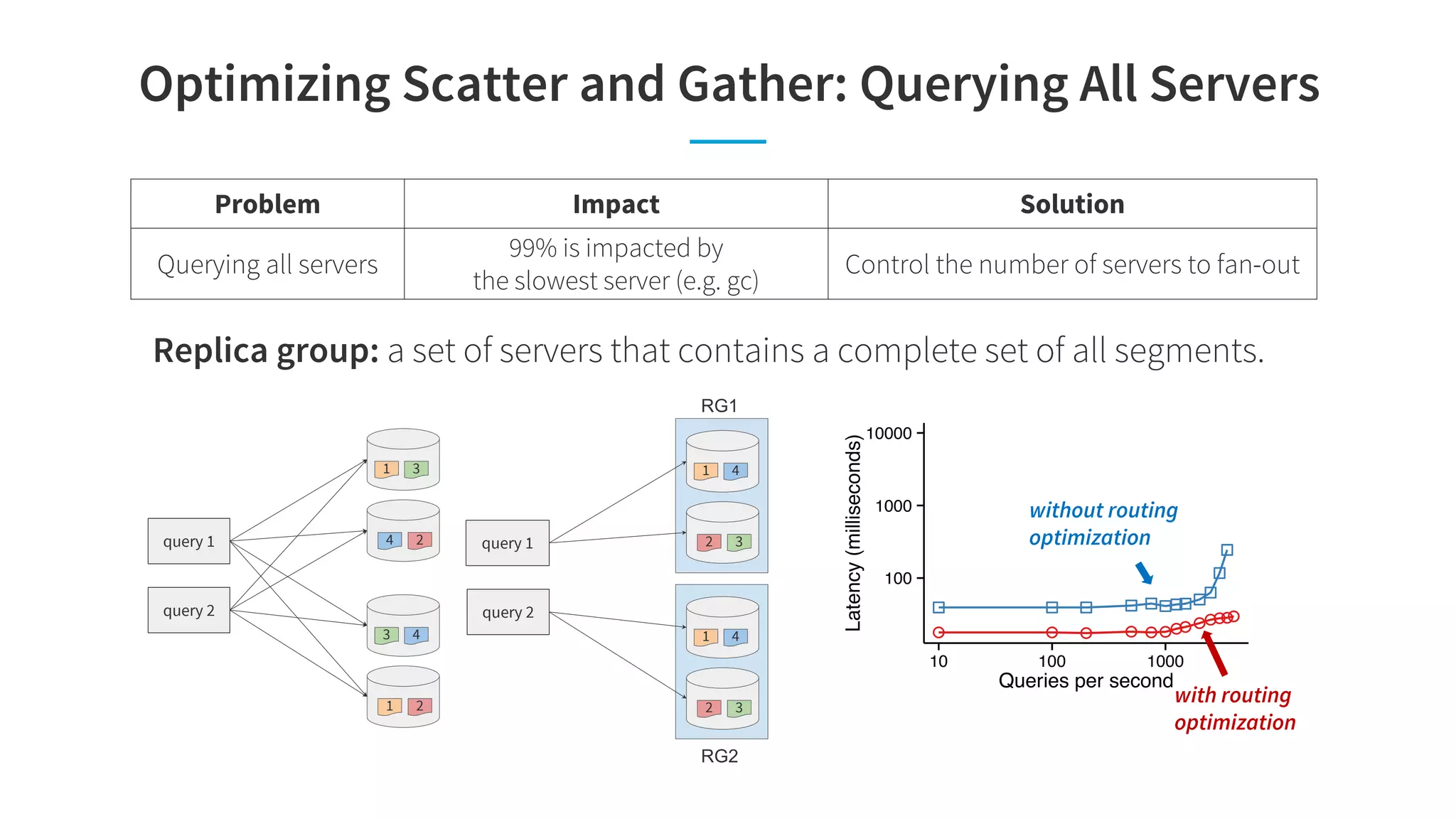
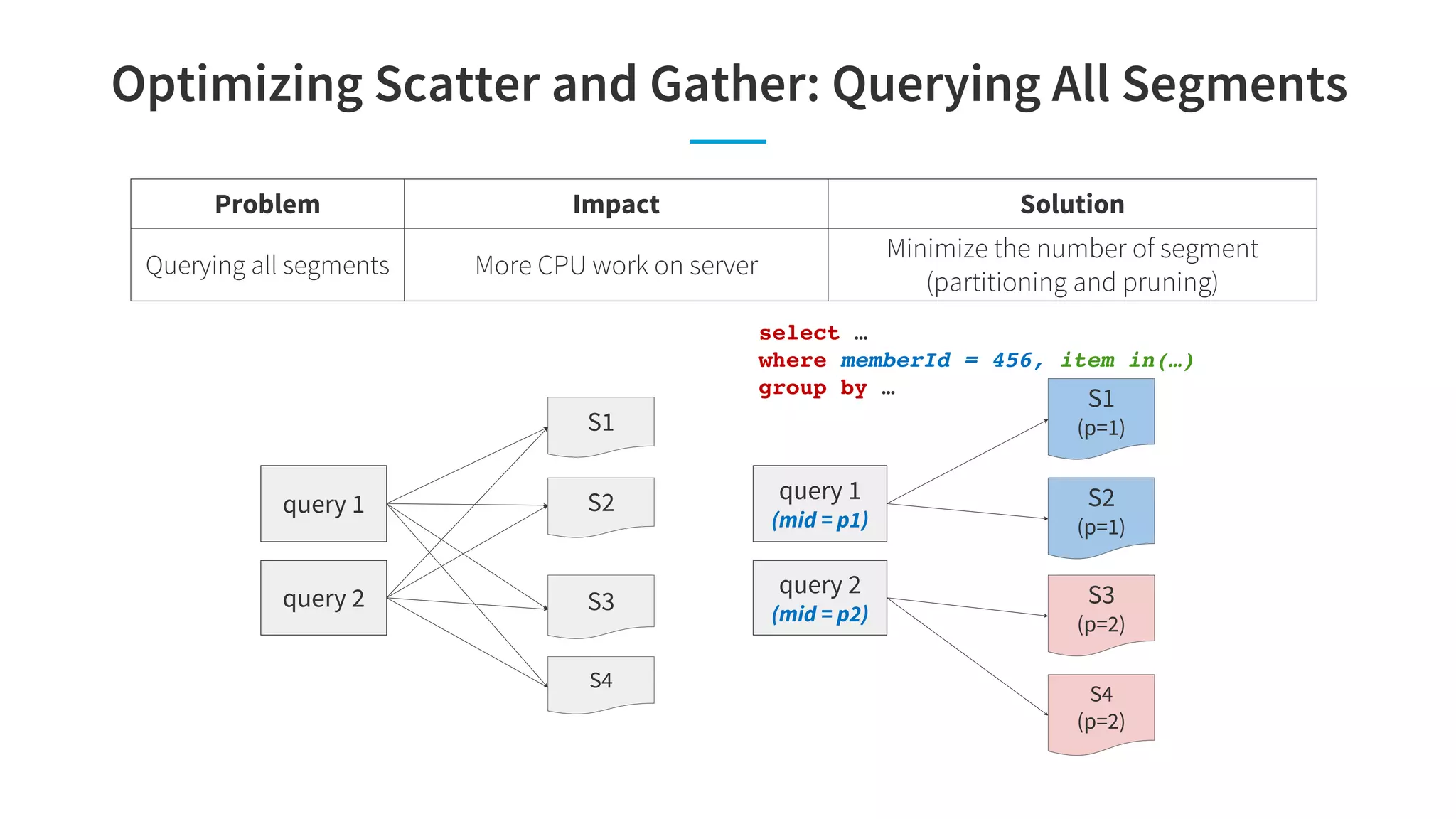
![Anomaly Detection: Challenge
for d1 in [us, ca, …]
for d2 in [key1, key2,…]
…
select sum(pageViews) from T
where country=d1, page_key=d2,
source_app=d3, device_name=d4…
group by country, time
…
Filter Aggregation Latency
select …
where country = us,…
Slow, scan 60-70% data high
select …
where country = kenya,…
Scan less than 1% low
• Latency not predictable depends on the query predicate
• Monitoring all possible combinations makes the problem worse!](https://image.slidesharecdn.com/sigmod-final-180725033925/75/Pinot-Realtime-OLAP-for-530-Million-Users-Sigmod-2018-28-2048.jpg)

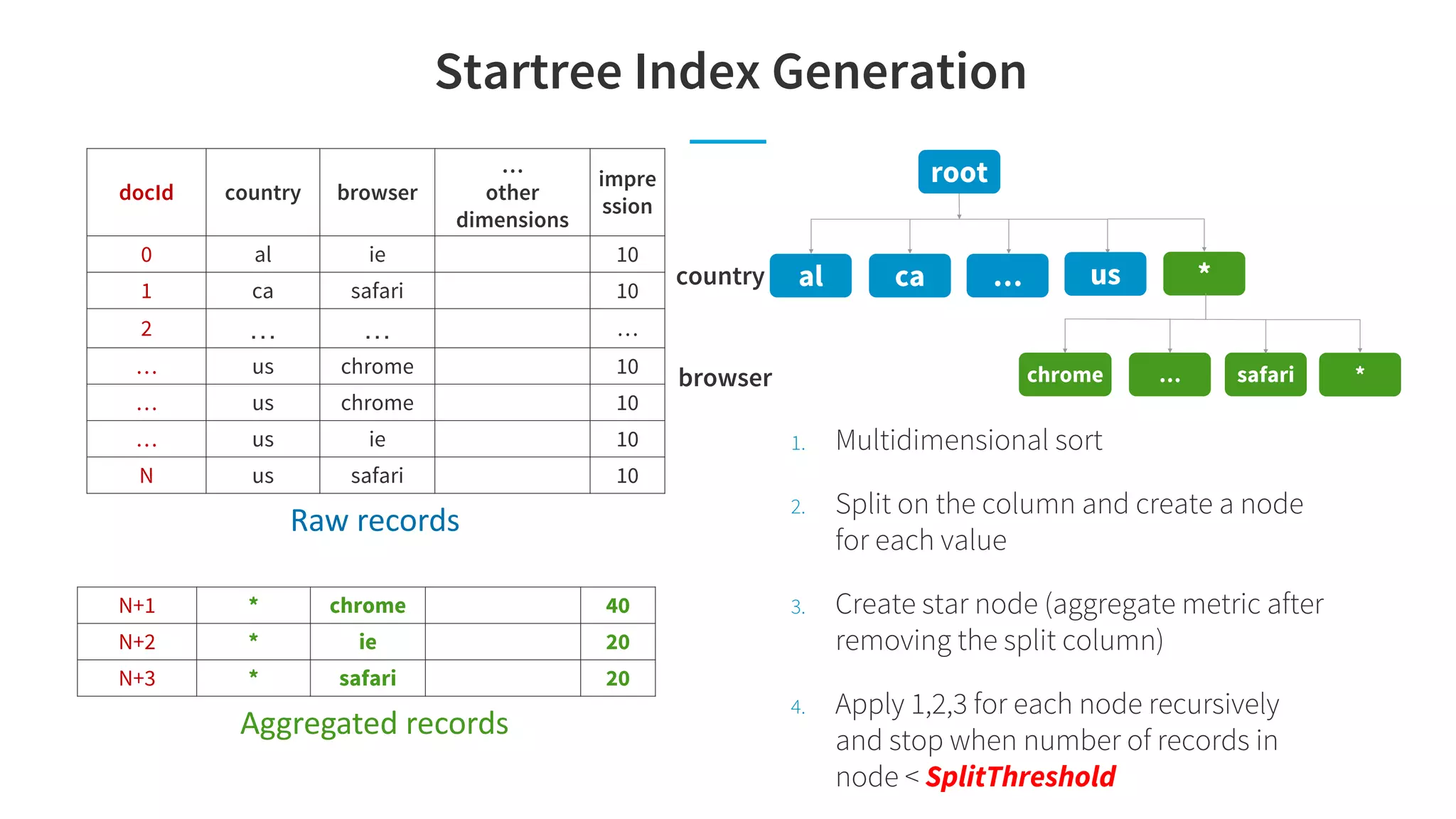
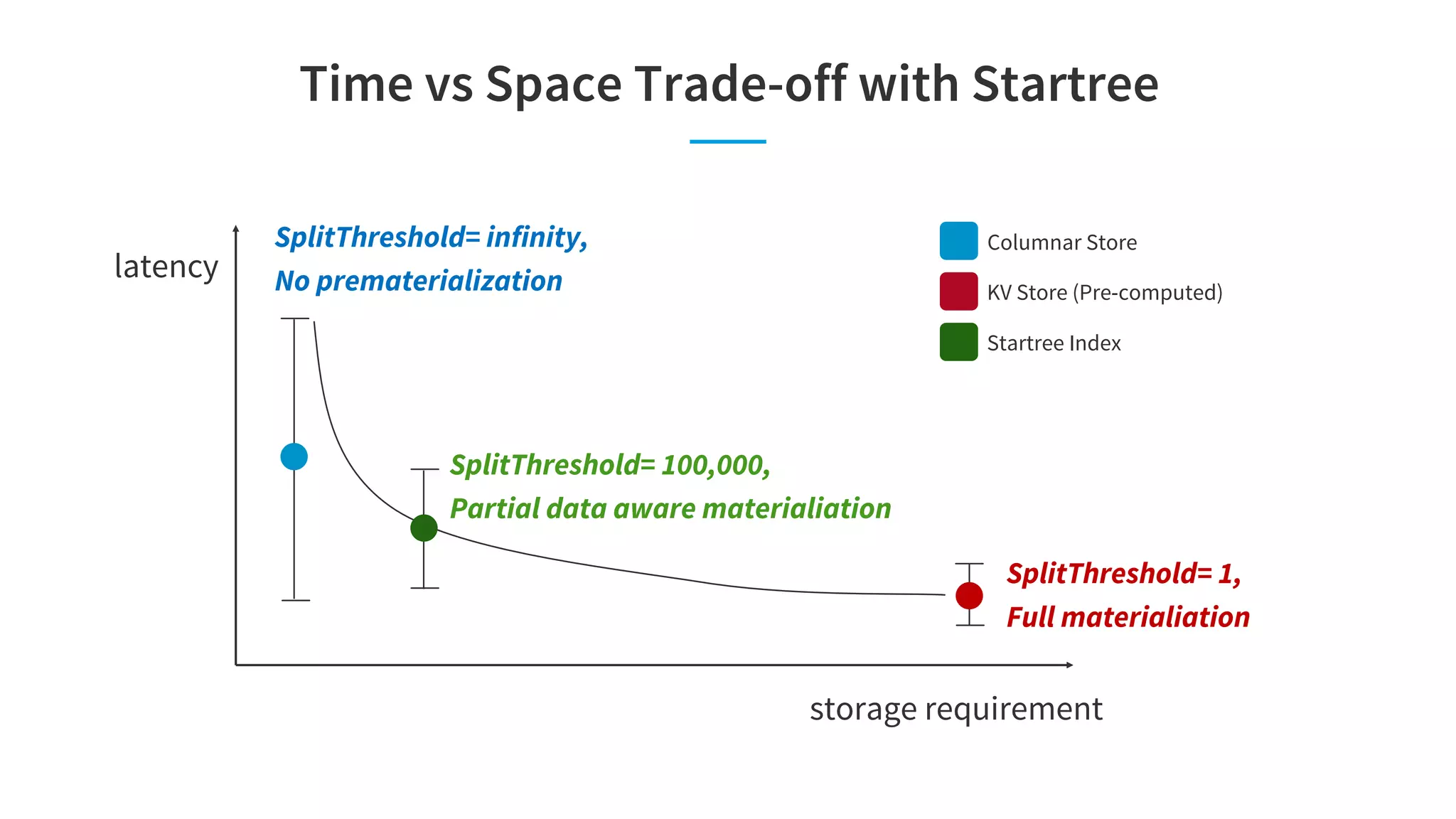






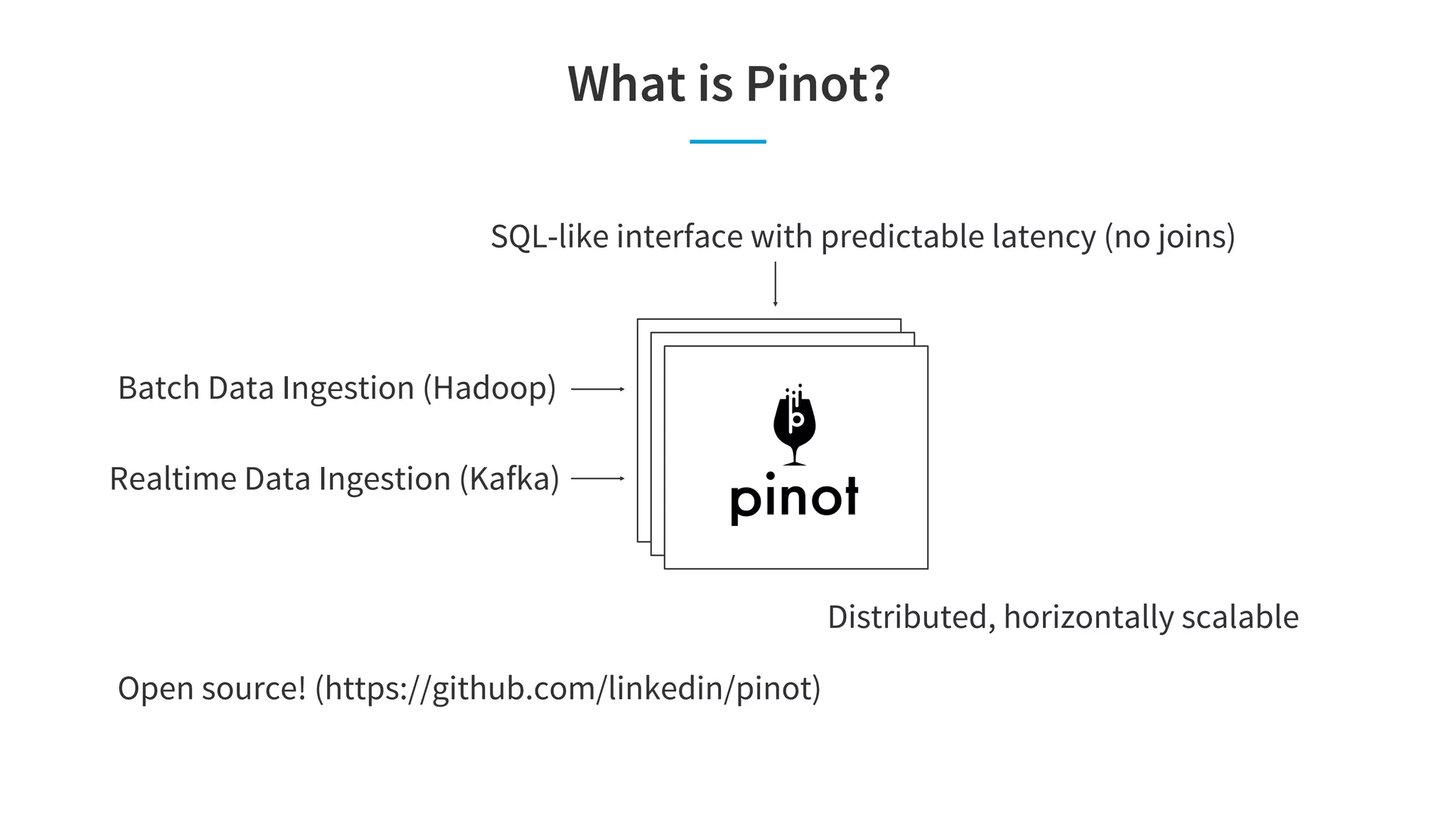
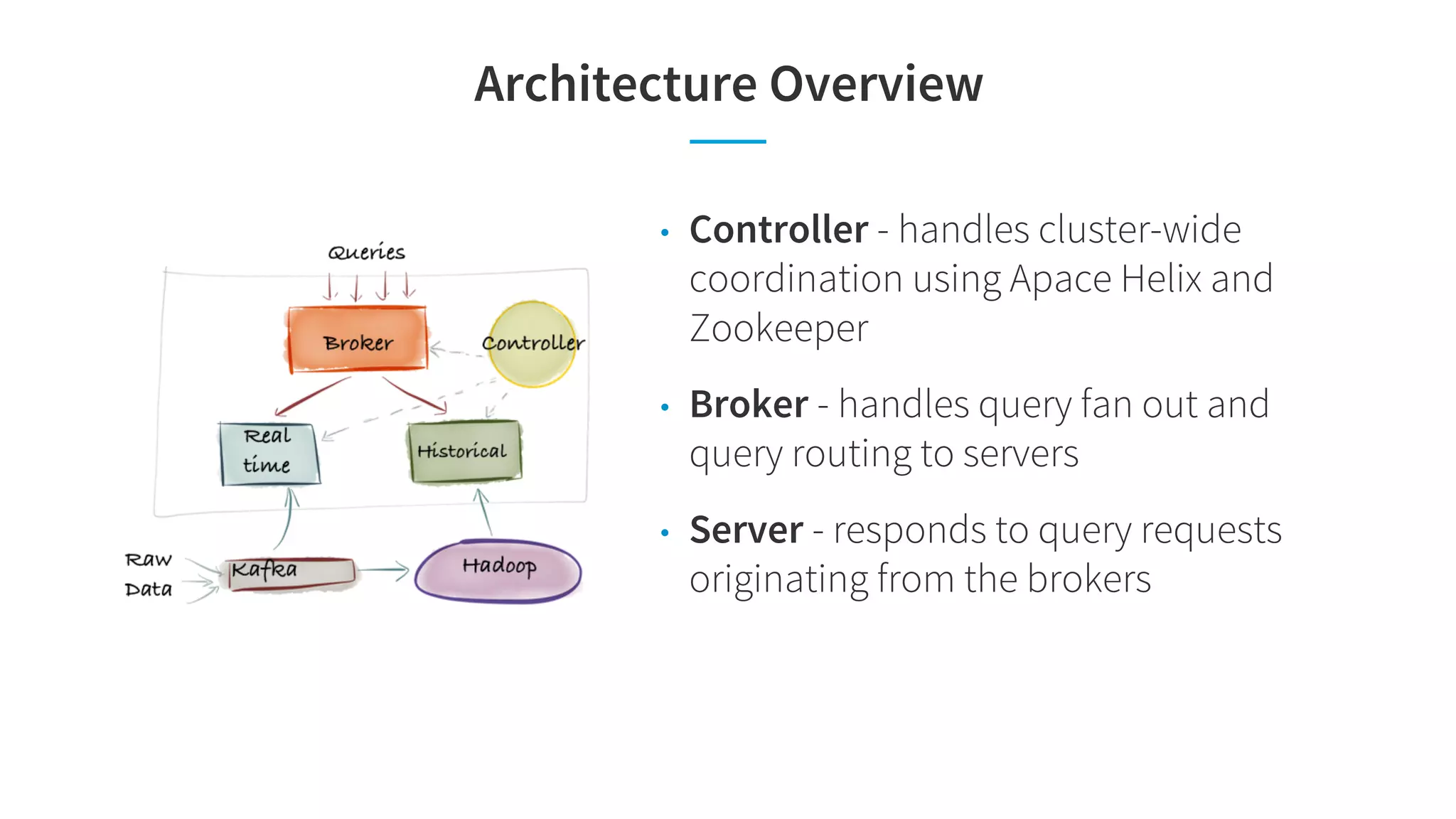
Pinot is a real-time OLAP data store that can support multiple analytics use cases like interactive dashboards, site facing queries, and anomaly detection in a single system. It achieves this through features like configurable indexes, dynamic query planning and execution, smart data partitioning and routing, and pre-materialized indexes like star-trees that optimize for latency and throughput across different workloads. The document discusses Pinot's architecture and optimizations that enable it to meet the performance requirements of these different use cases.
















































![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Vladimir Jelic - The AI-Driven Security Shift From Reactive D...](https://cdn.slidesharecdn.com/ss_thumbnails/6g5gj25mtjwayniqem1t-6-251209104645-7a5a5fc6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Imai Jen-La Plante - The New Generation: AI and the Future of...](https://cdn.slidesharecdn.com/ss_thumbnails/kxi8t2l5rggivgcenyba-1-jenlaplante-dsc-251208152532-d1e076c2-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Sara Polak - The Ancient Operating System: What Archaeology T...](https://cdn.slidesharecdn.com/ss_thumbnails/3vch2p6tttdnwhsgazoz-3-sara-polak-smart-cities-251208152532-64404202-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Aleksandra Dragicevic - AI-Boosted Research in Healthcare: Fr...](https://cdn.slidesharecdn.com/ss_thumbnails/iqwngszurf2r7pi1lnnj-4-aleksandra-dragicevic-ad-dsc-europe-conference-20-251208151905-37c3238a-thumbnail.jpg?width=640&height=640&fit=bounds)


