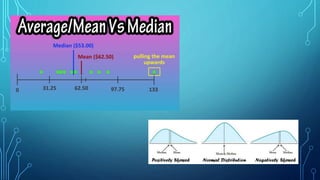
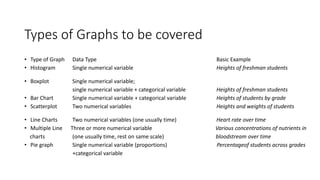
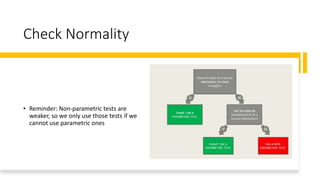
This document provides an overview of analyzing data using SPSS. It discusses exploring the data through descriptive statistics and graphs. Key steps include formulating hypotheses, checking for normality, selecting the appropriate statistical test, and interpreting the results by reporting test statistics, p-values, and whether the null hypothesis is rejected or not. Different types of variables, data, and common statistical tests are defined.