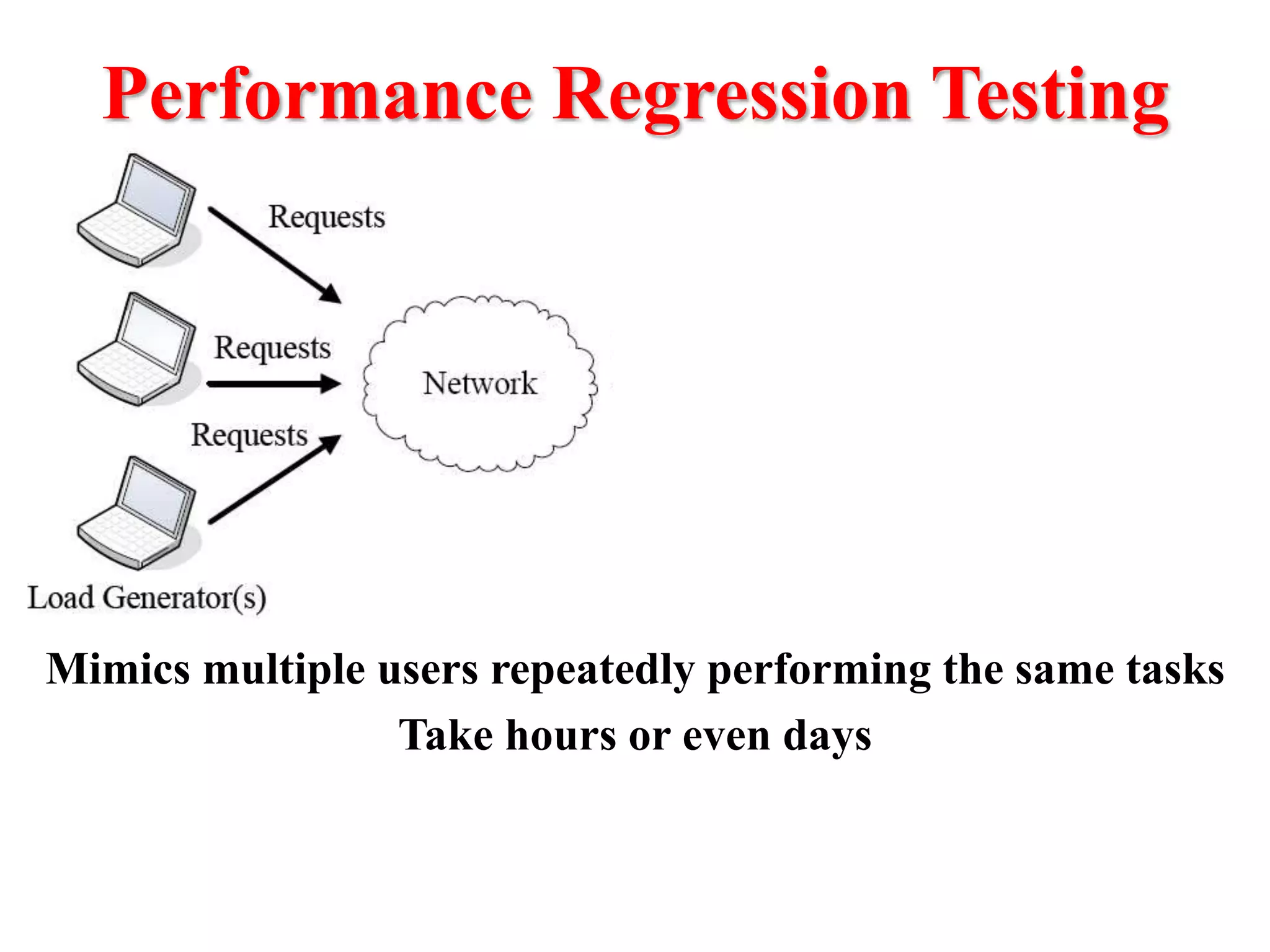
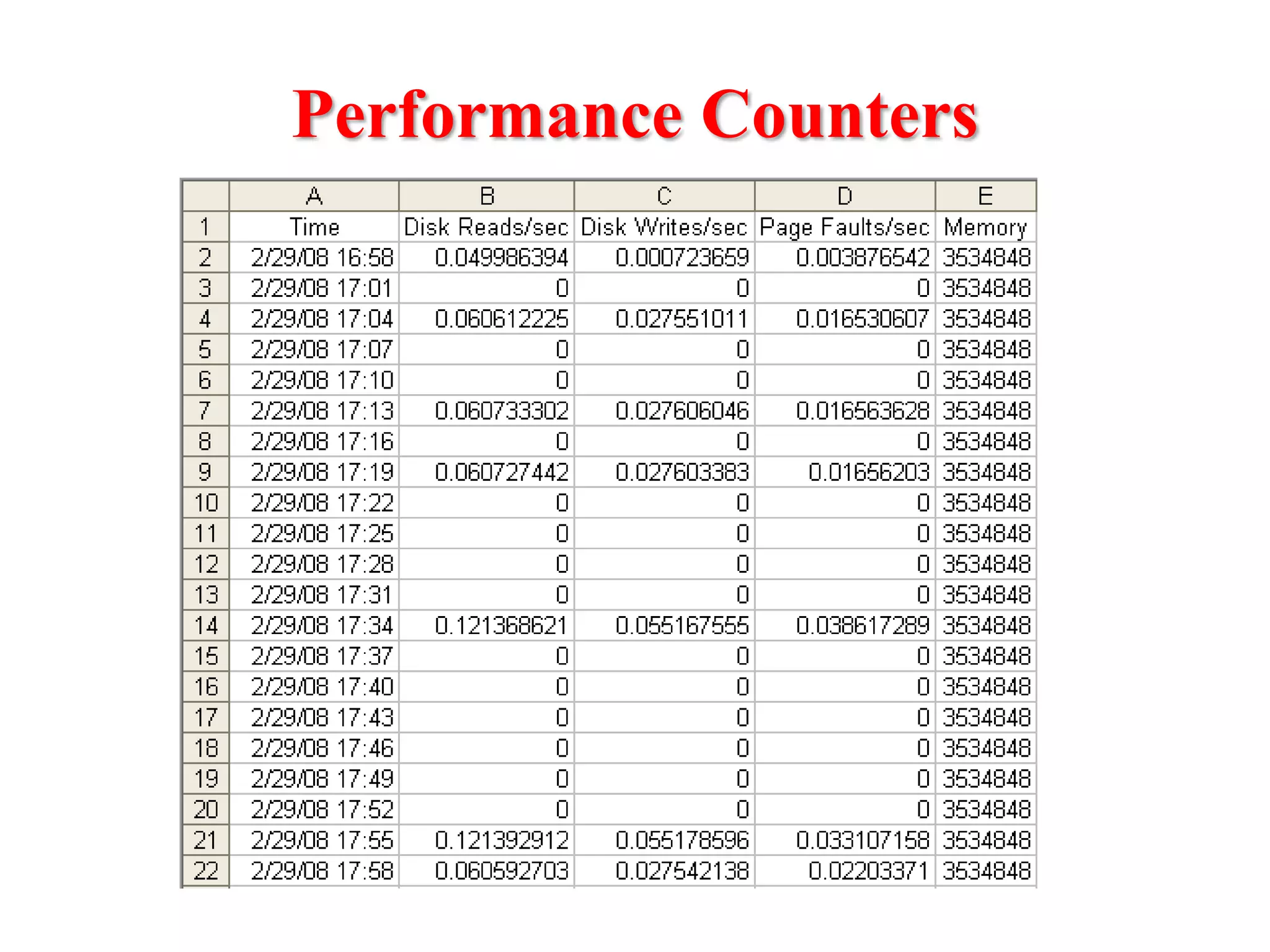
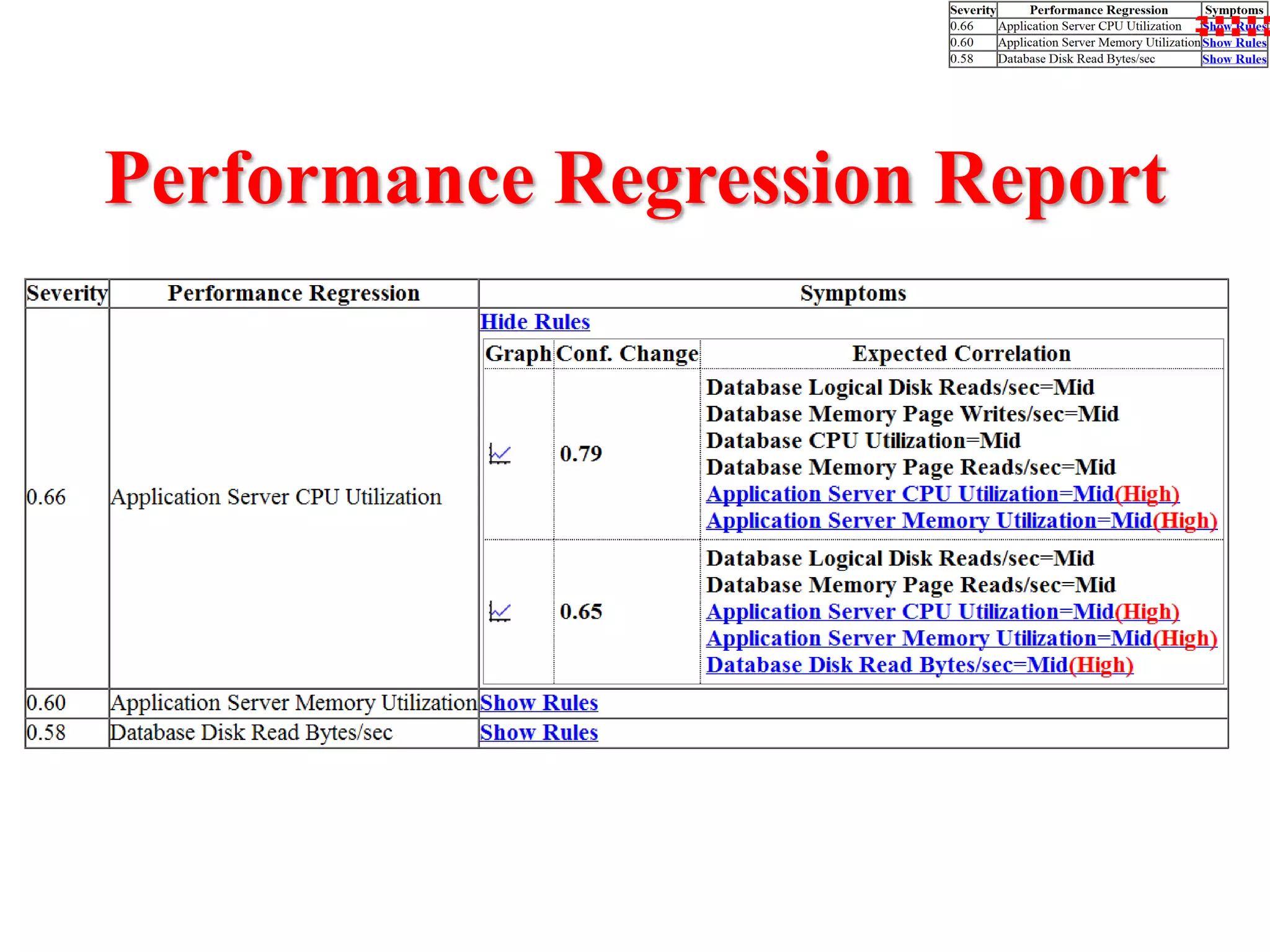
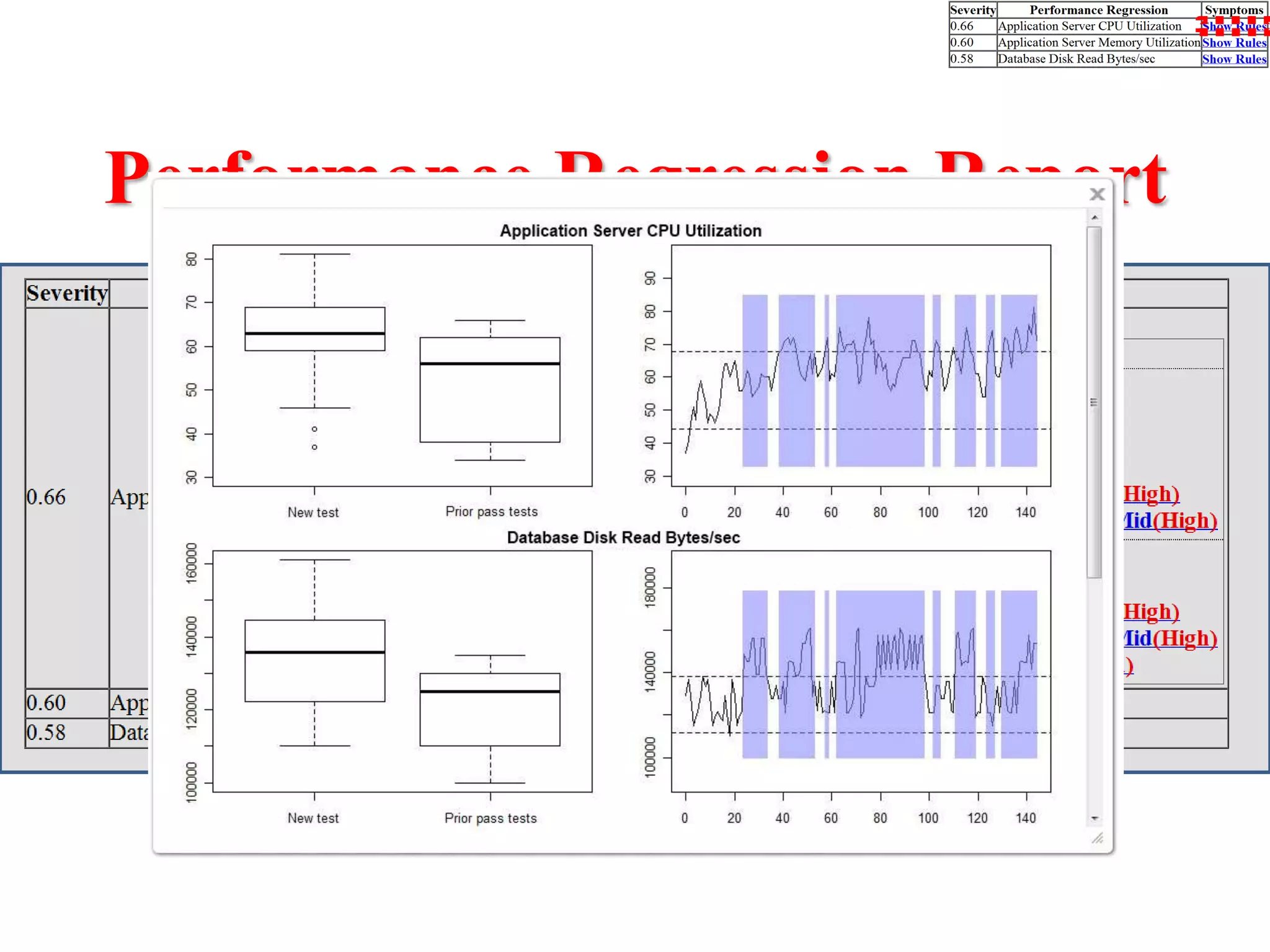
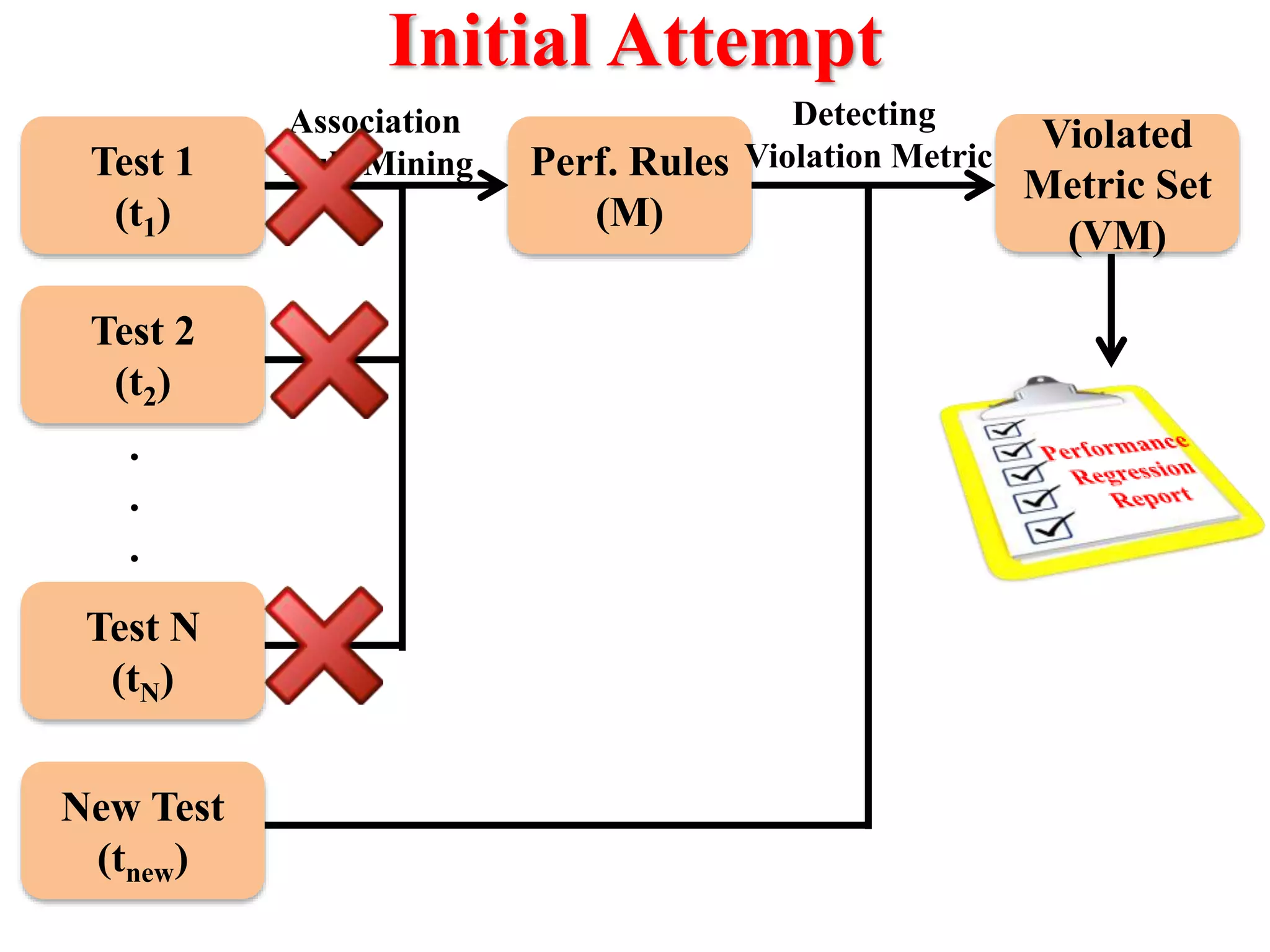
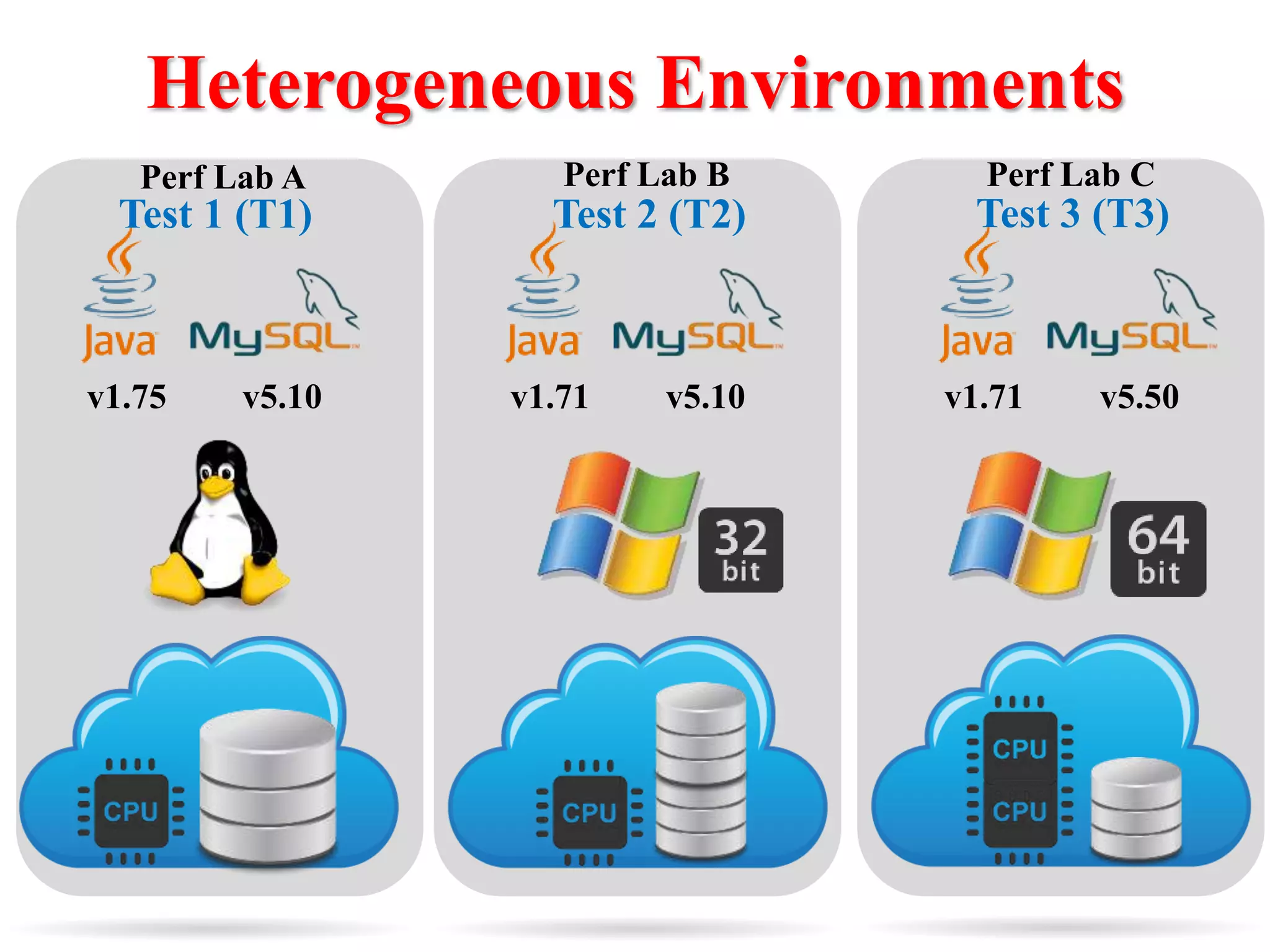
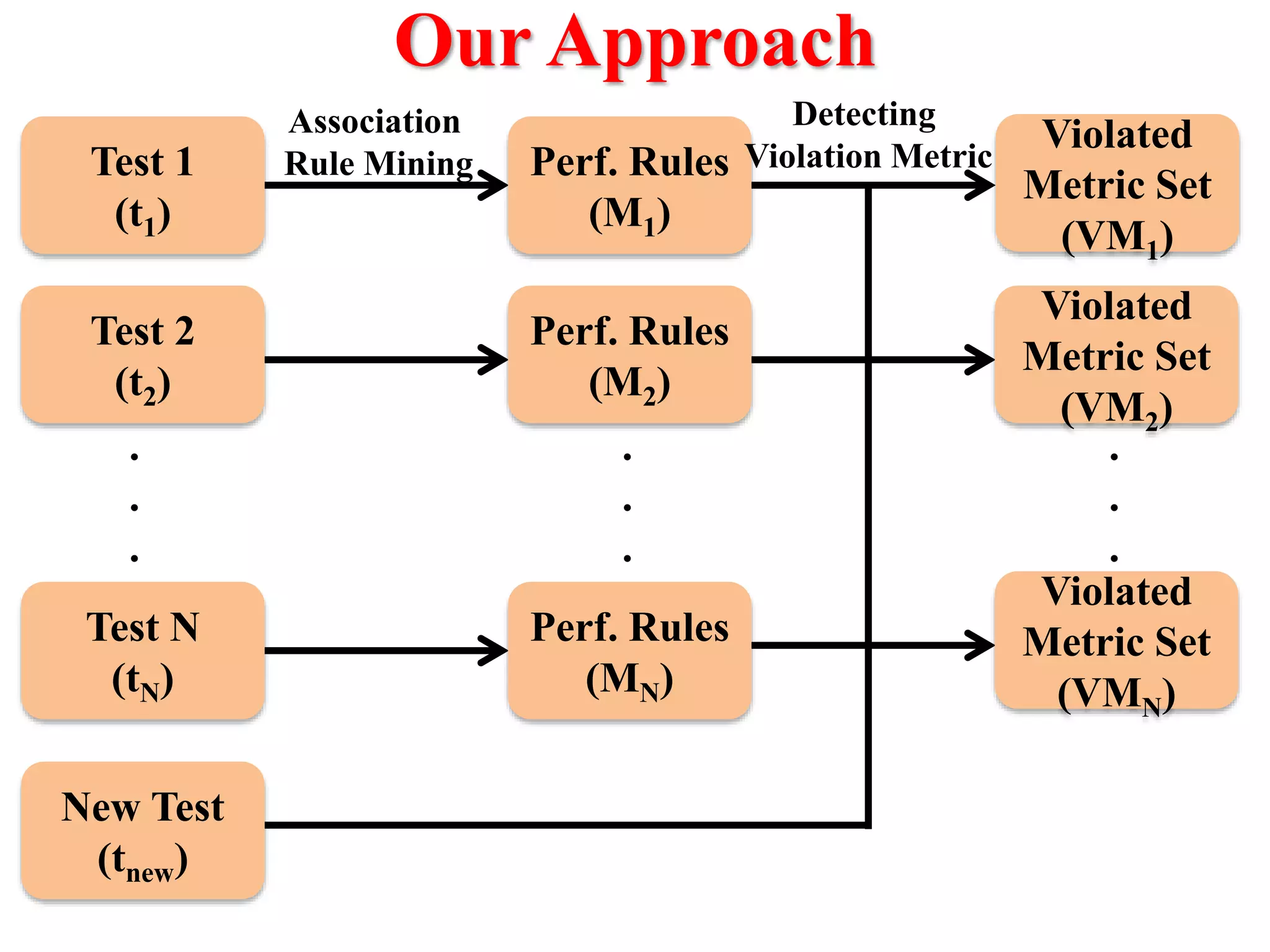
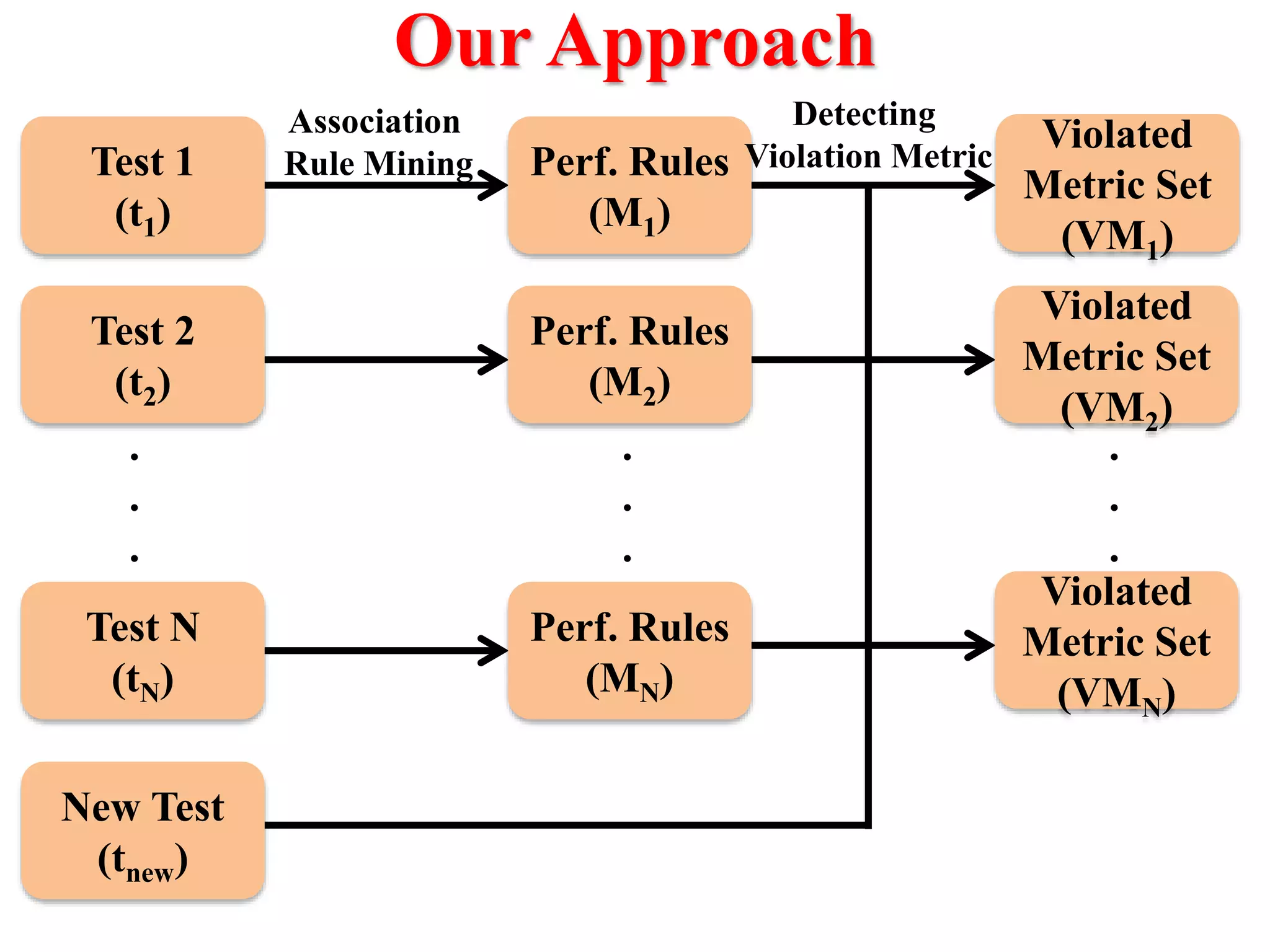
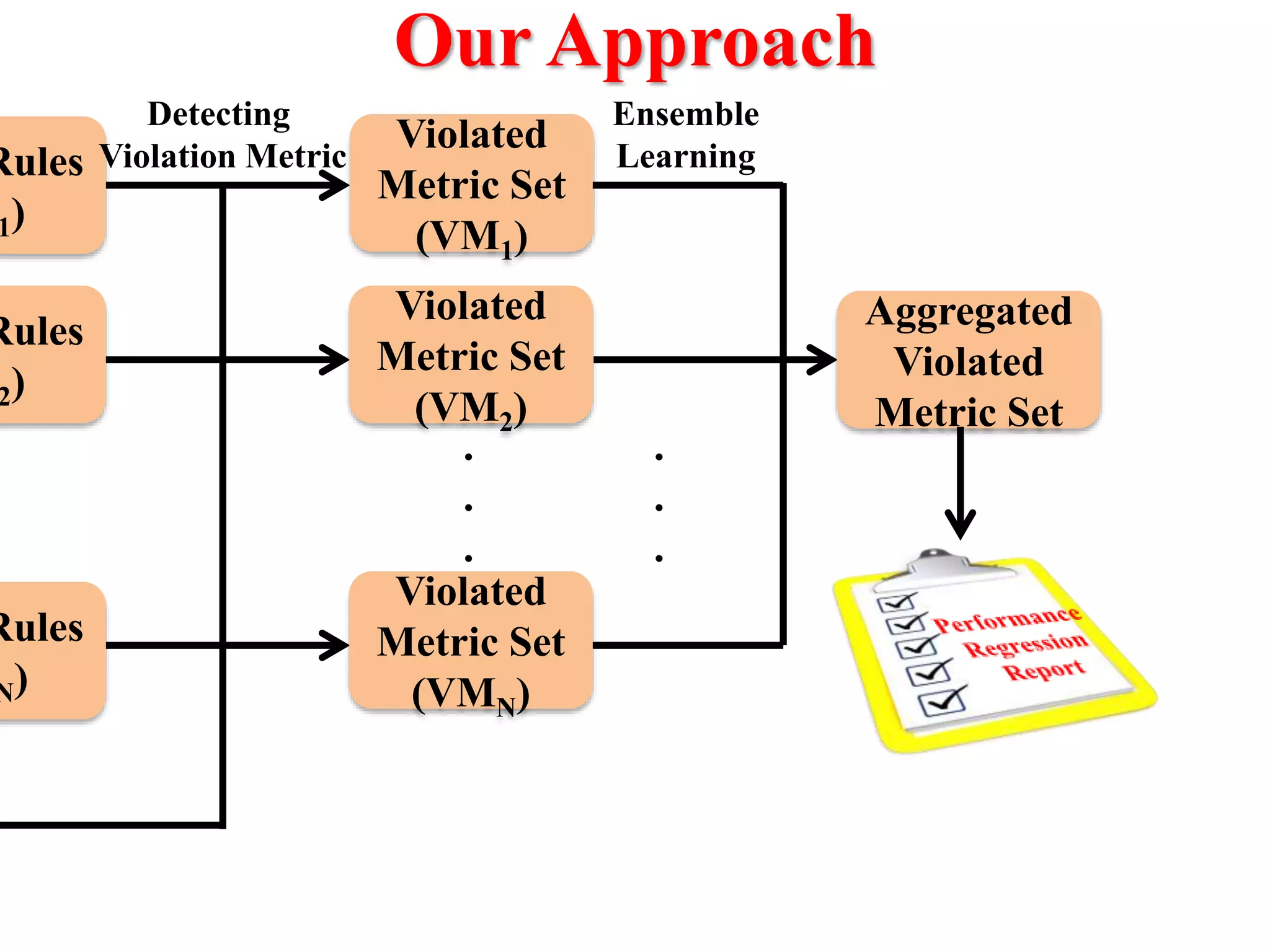
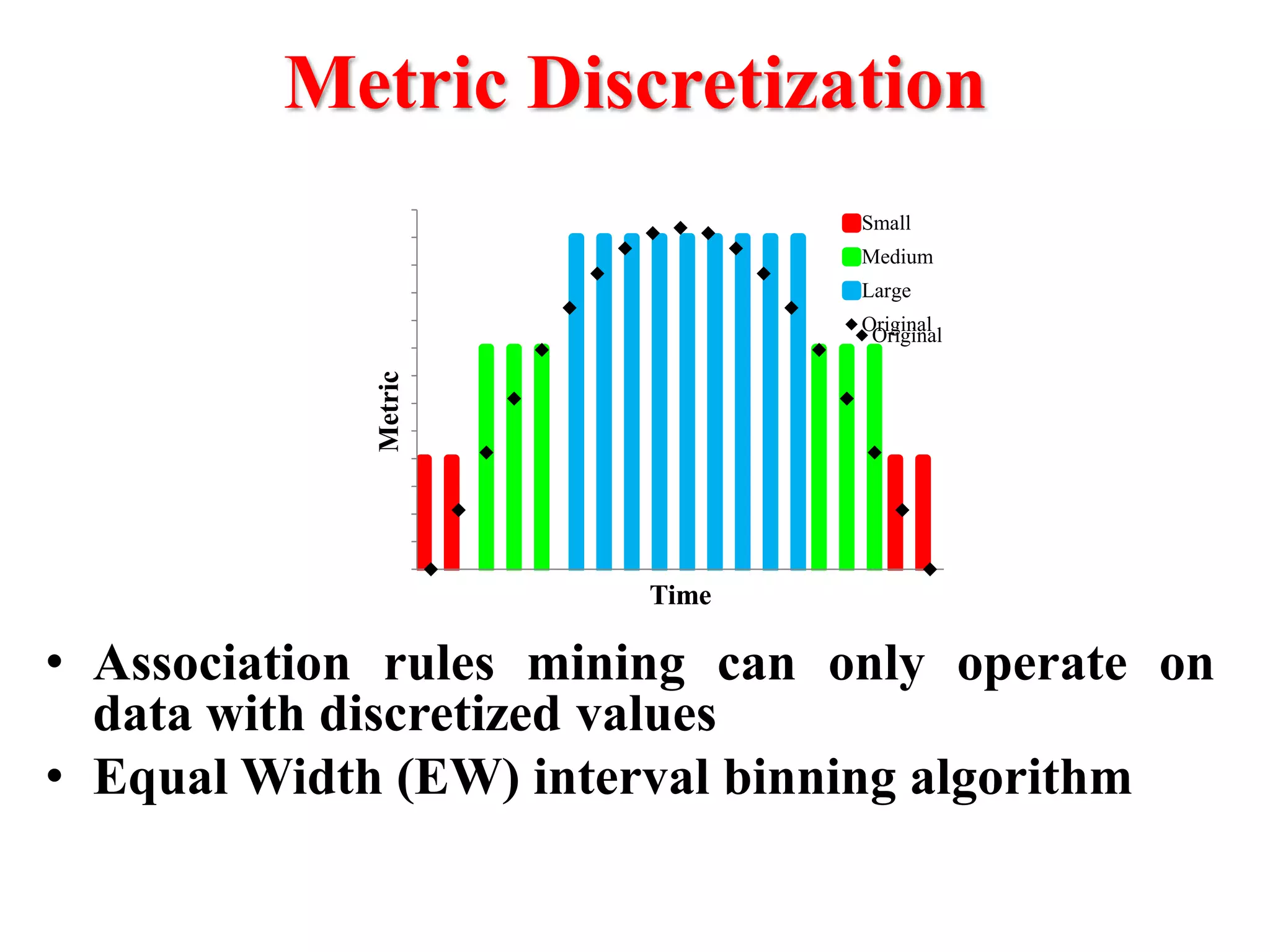
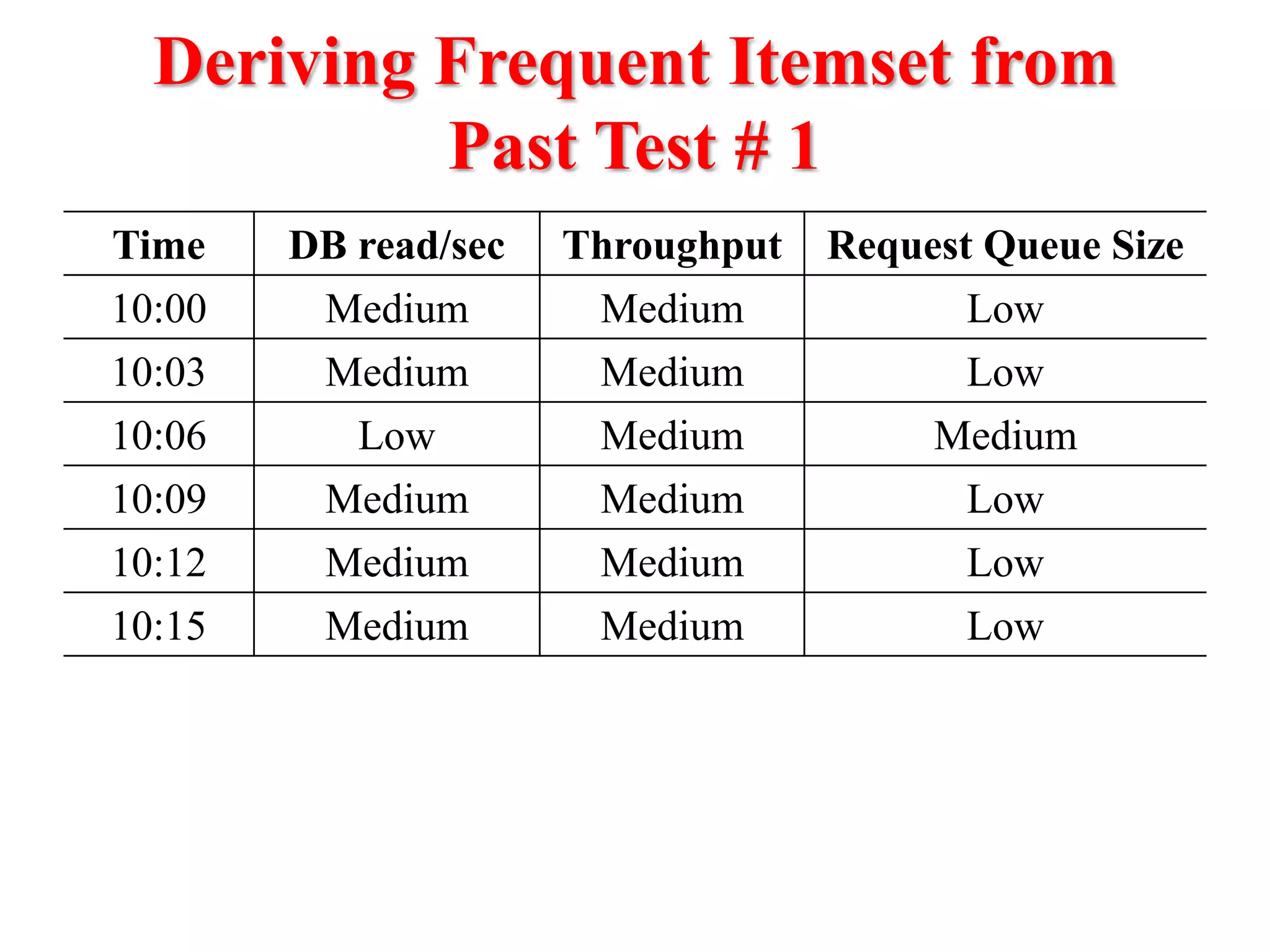
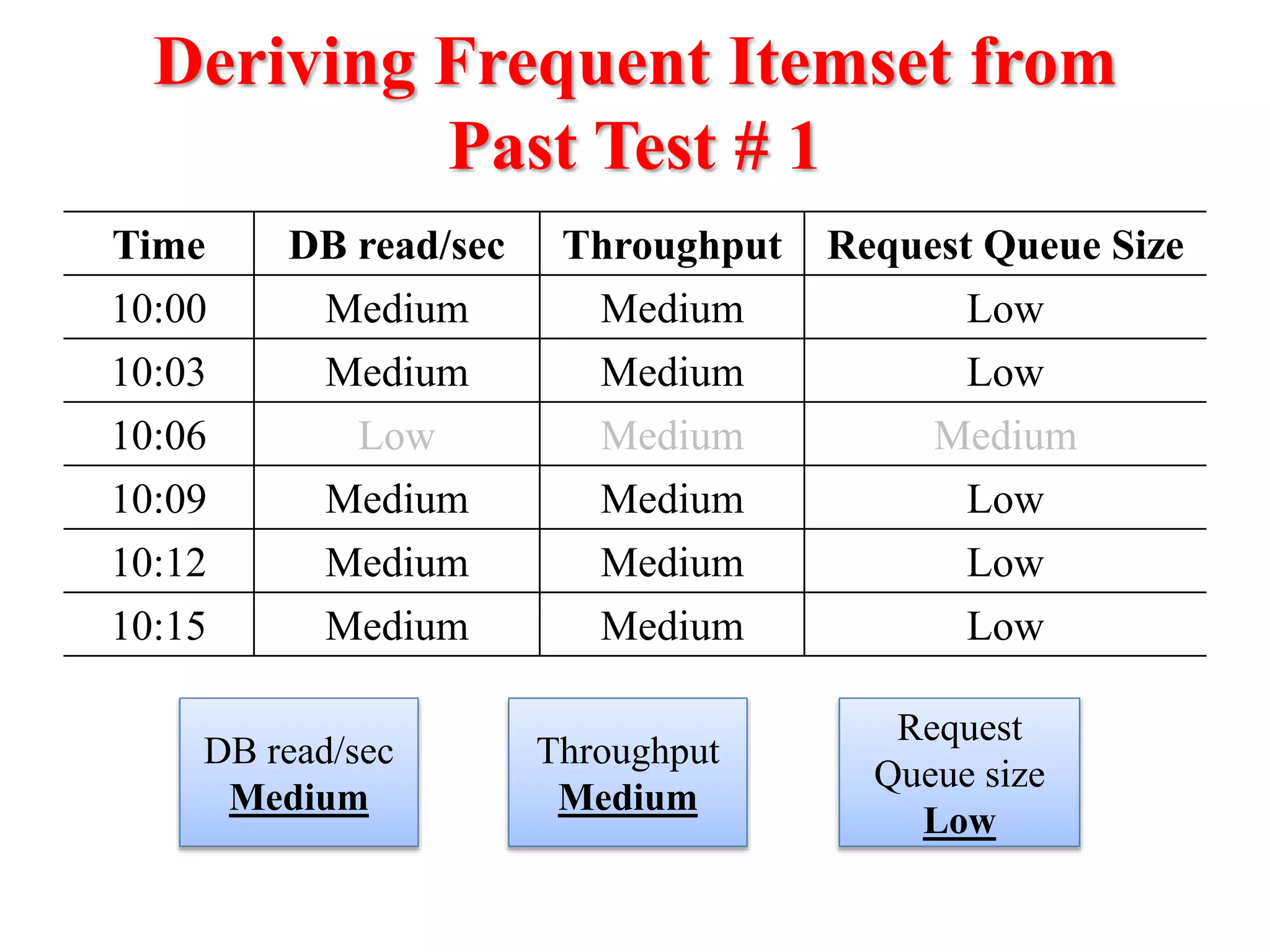
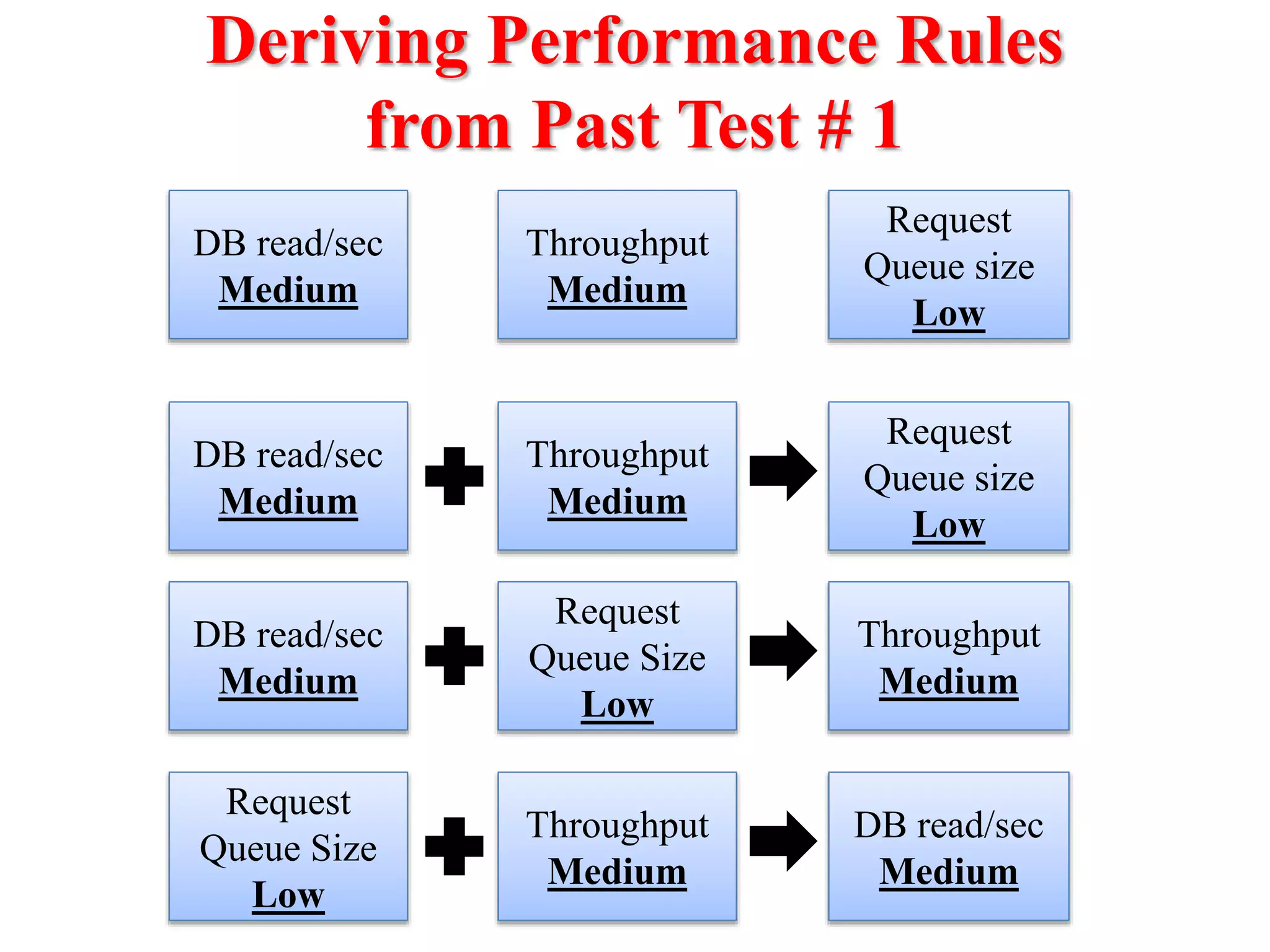
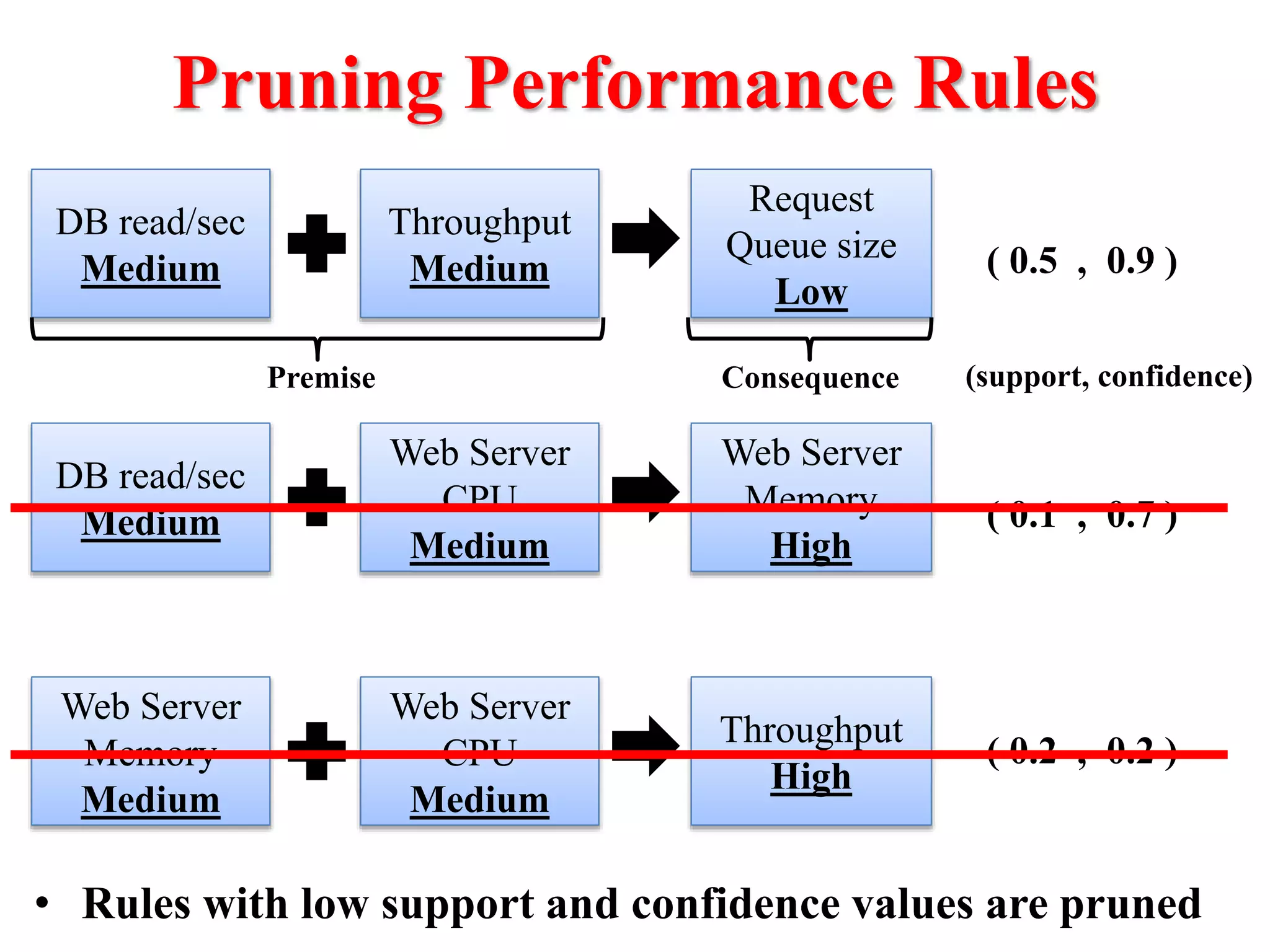
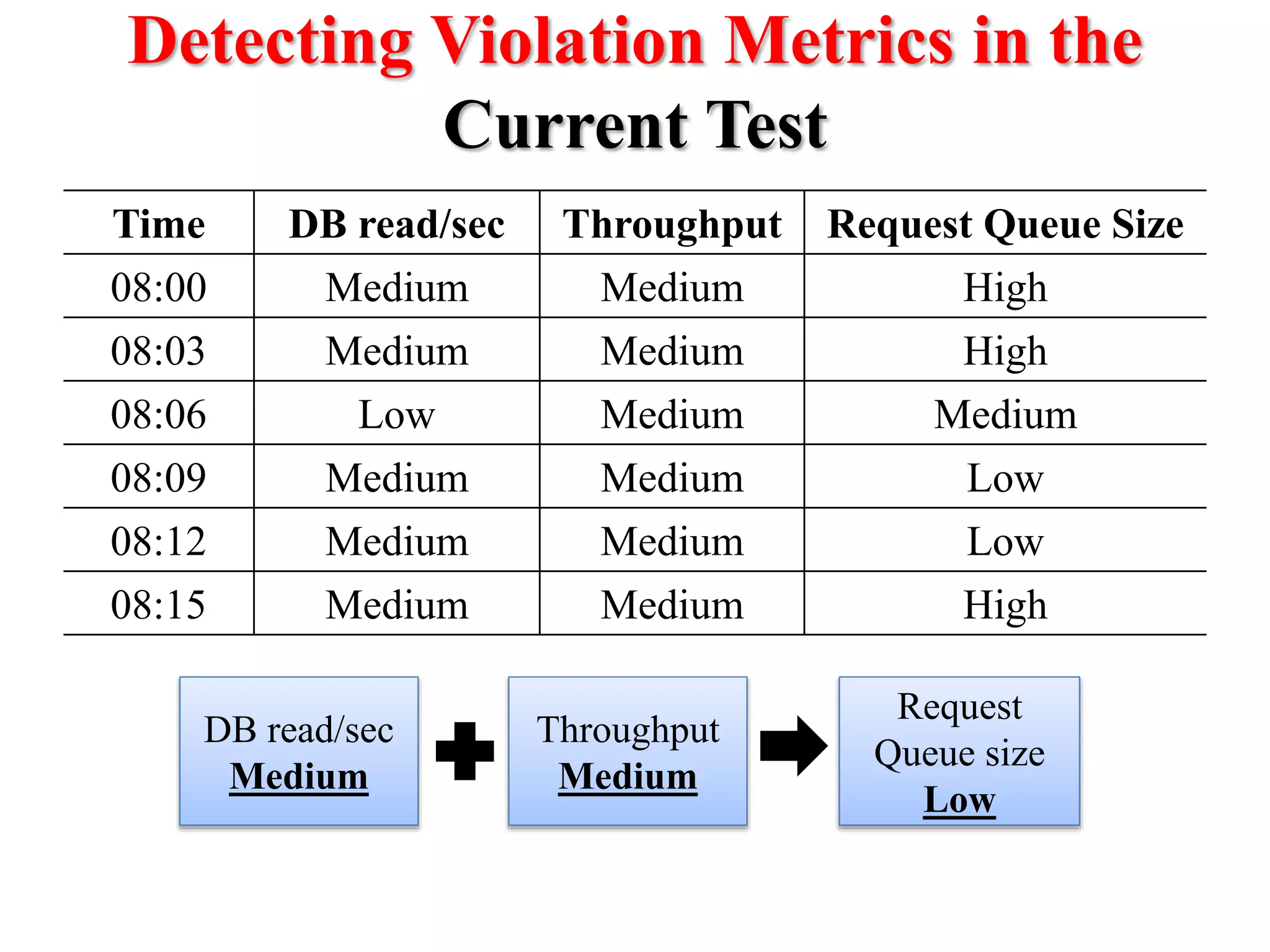
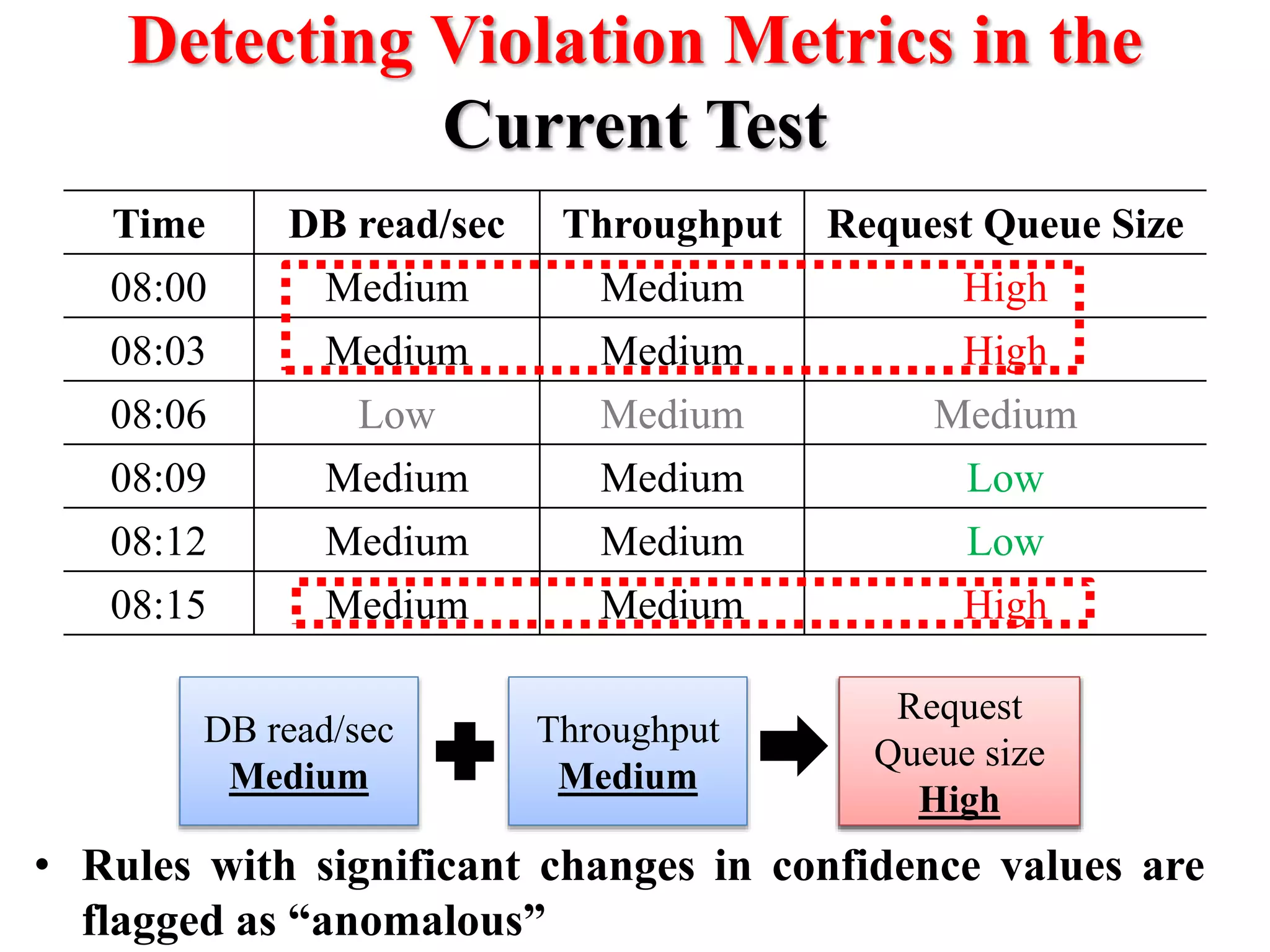
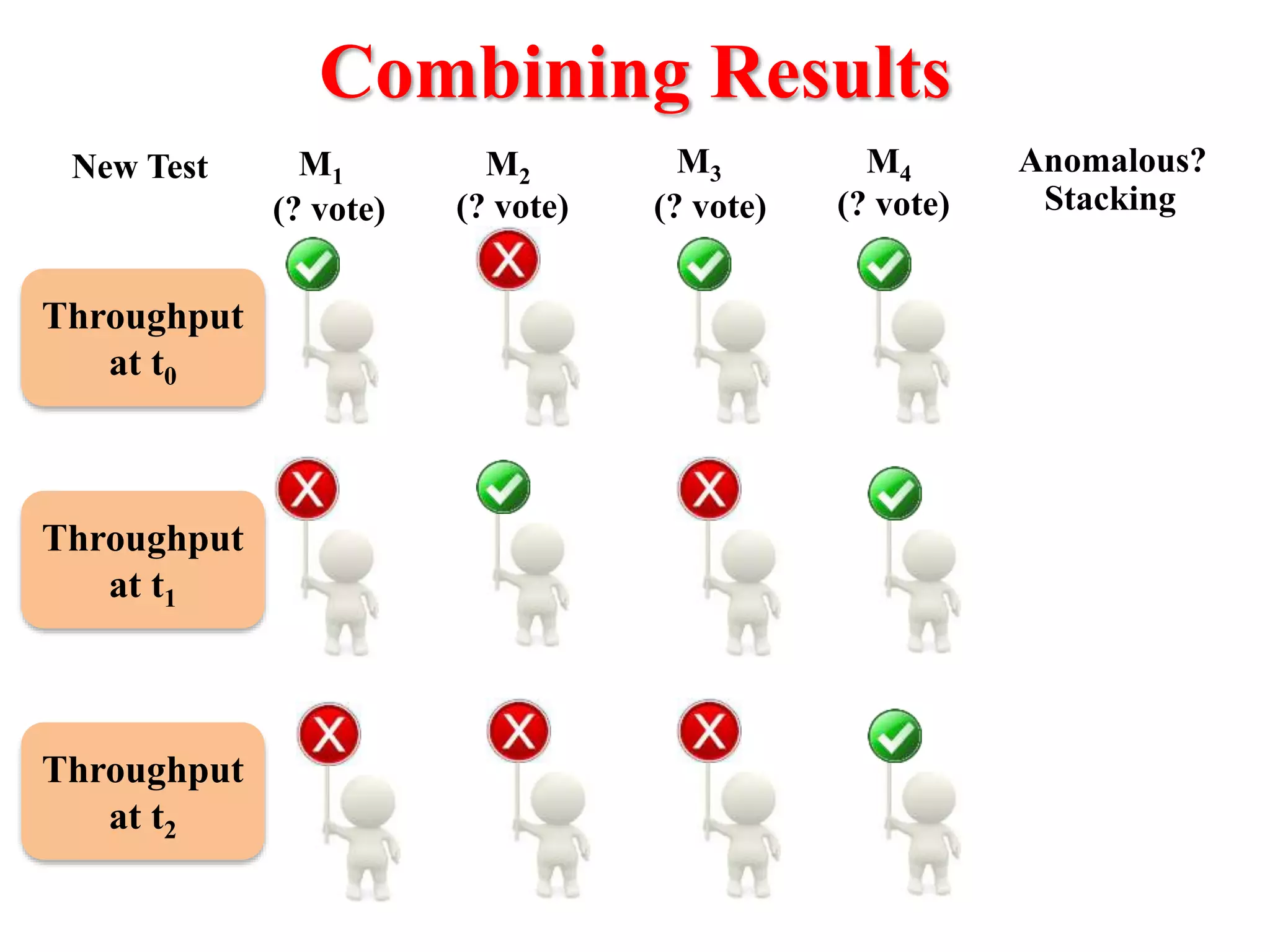
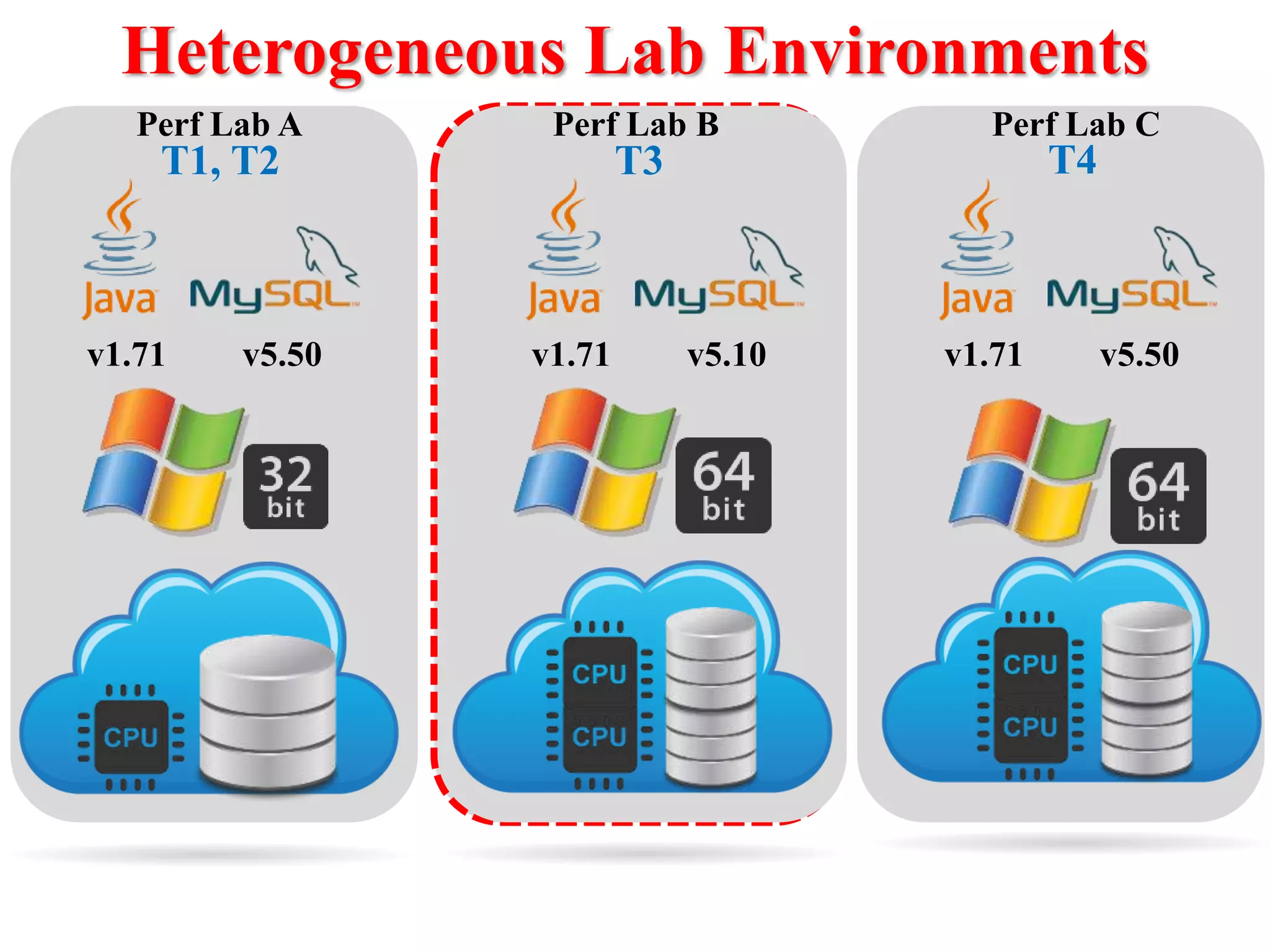
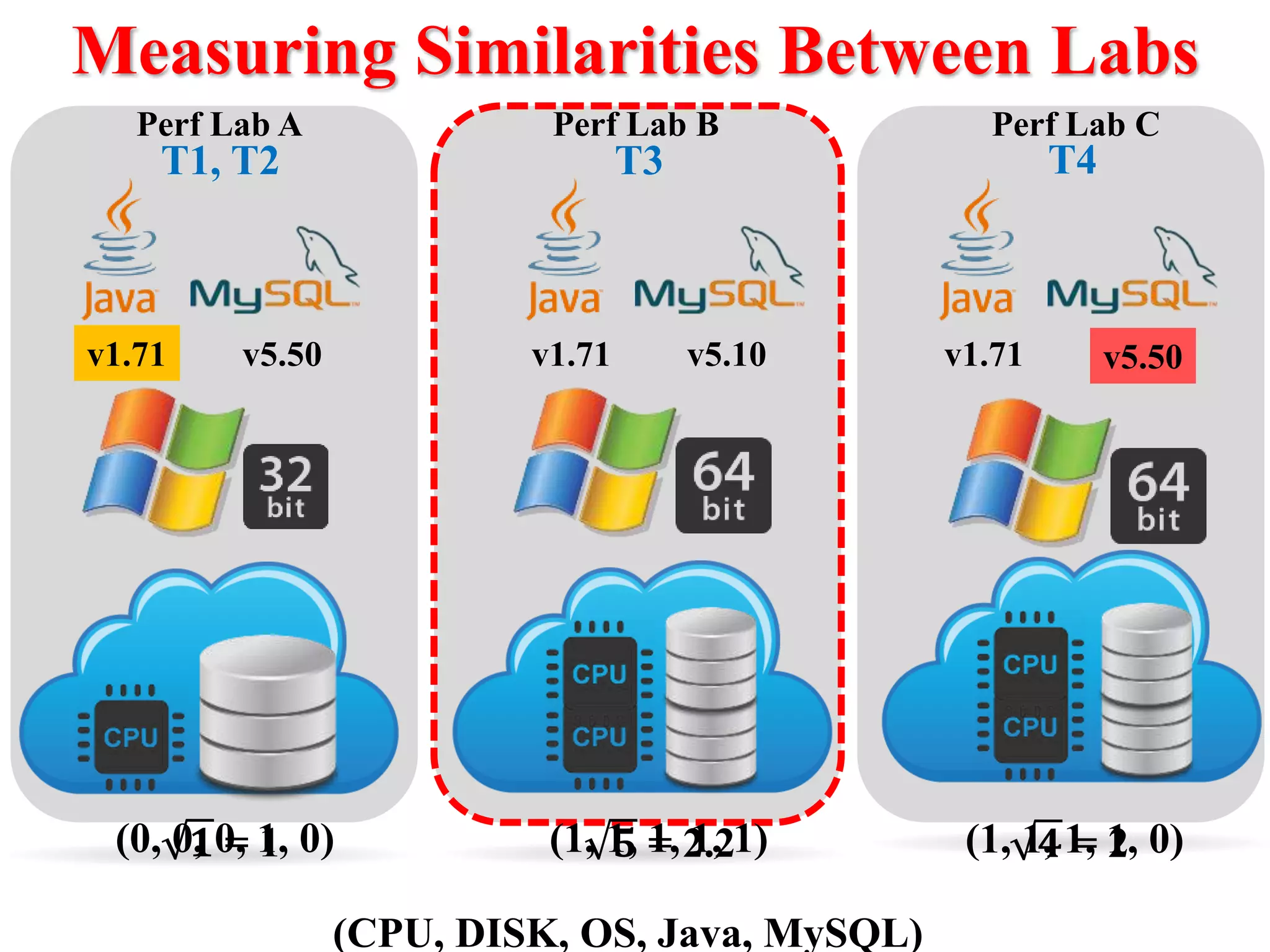
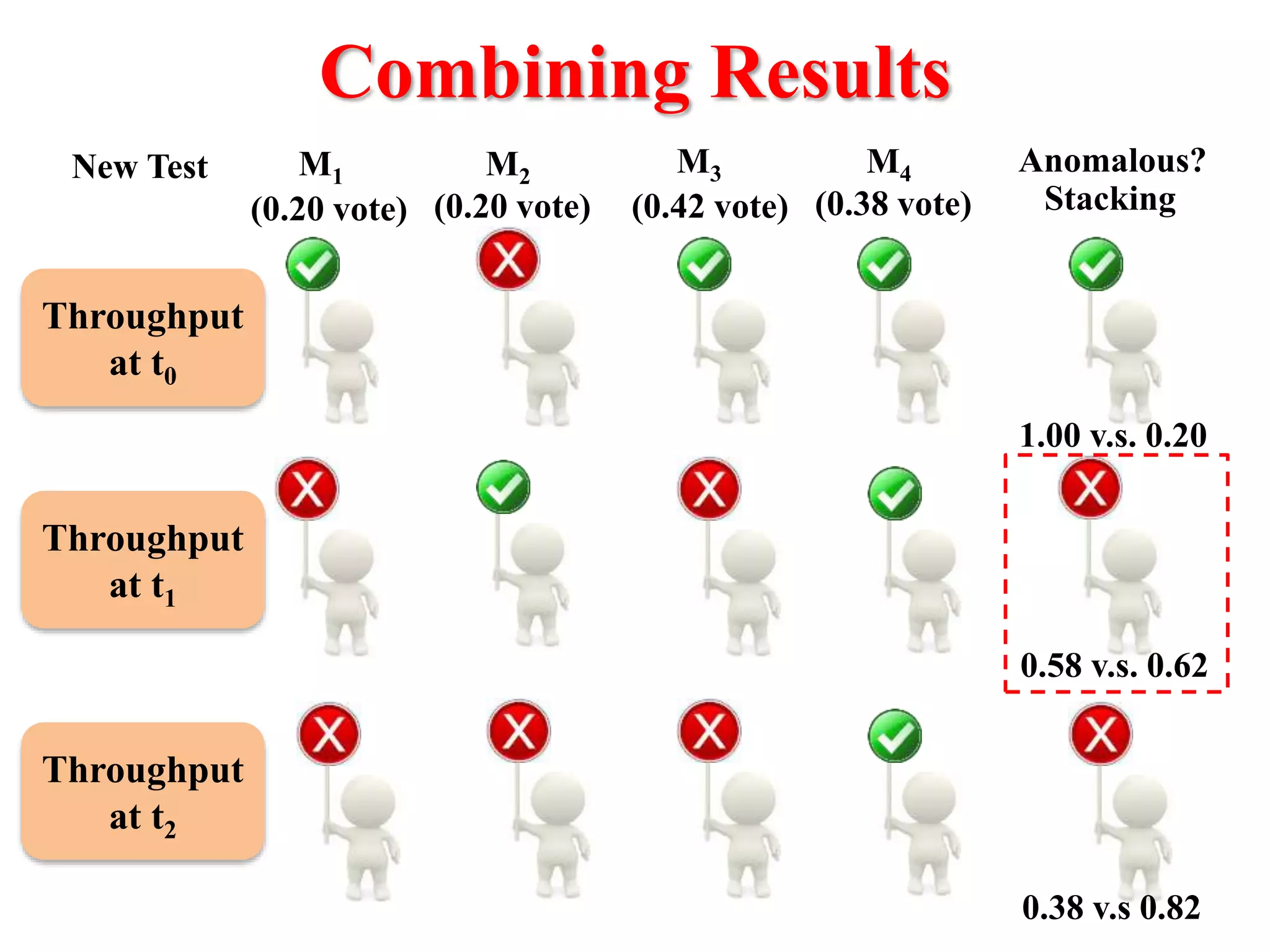
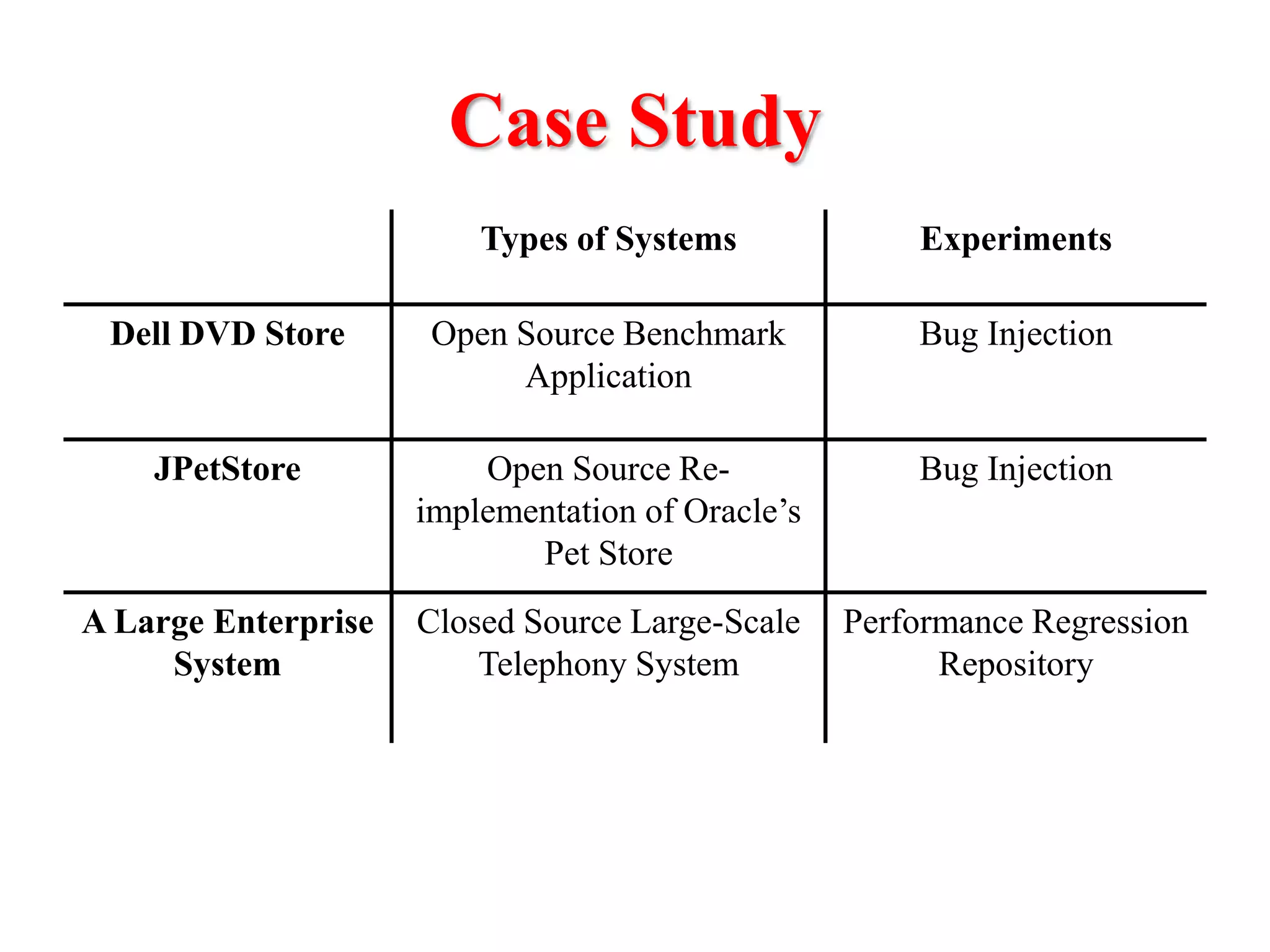
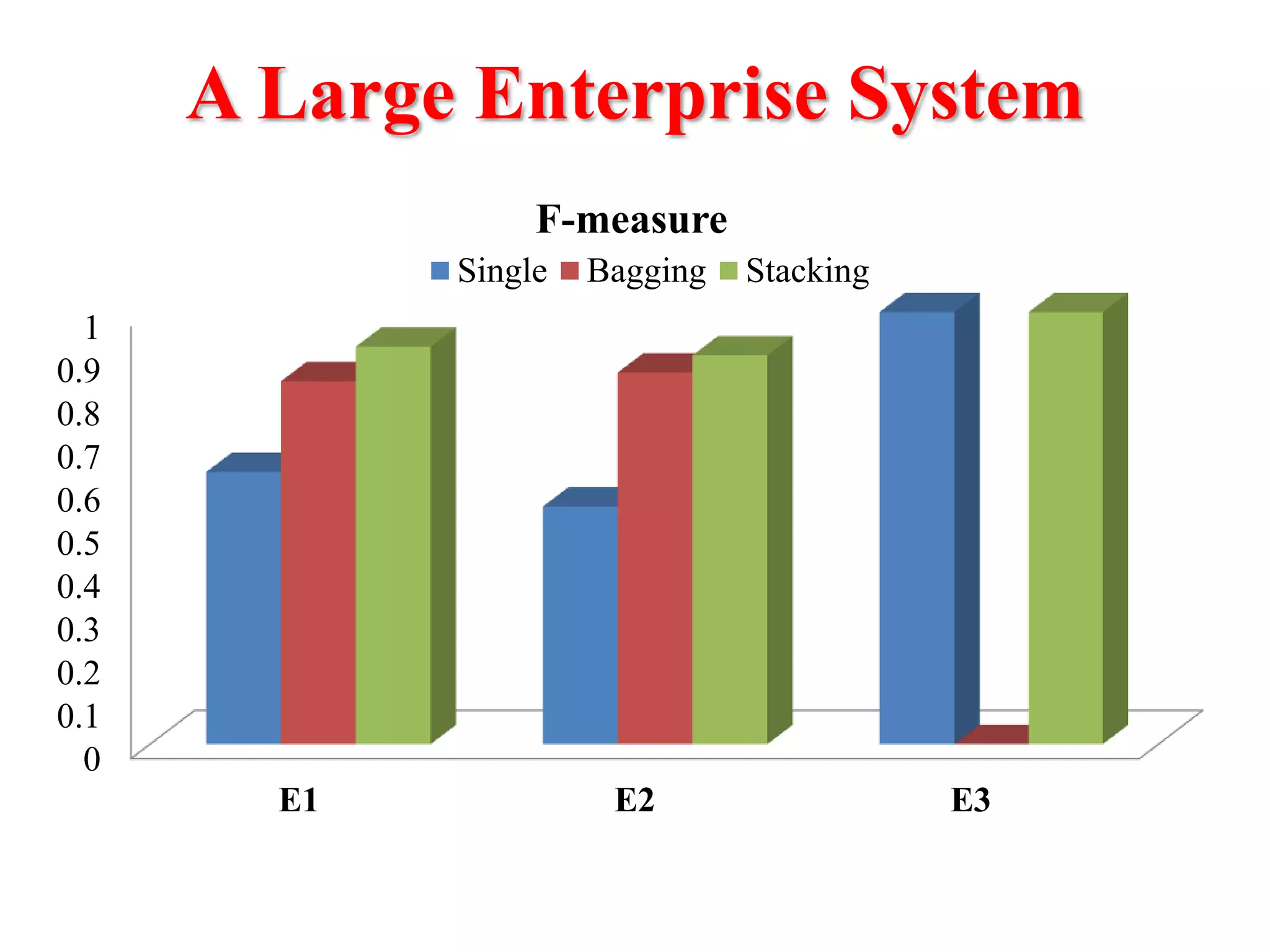
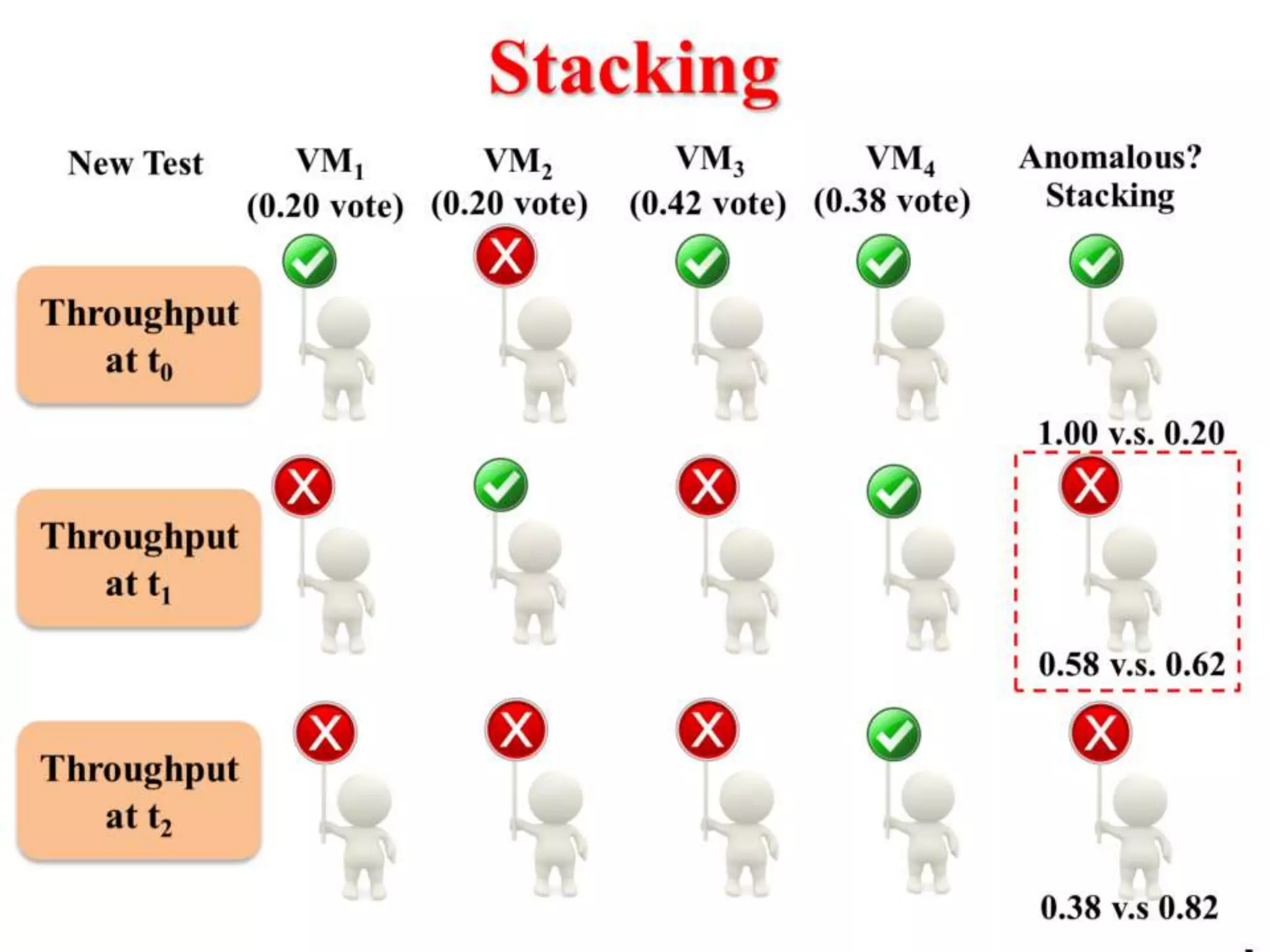
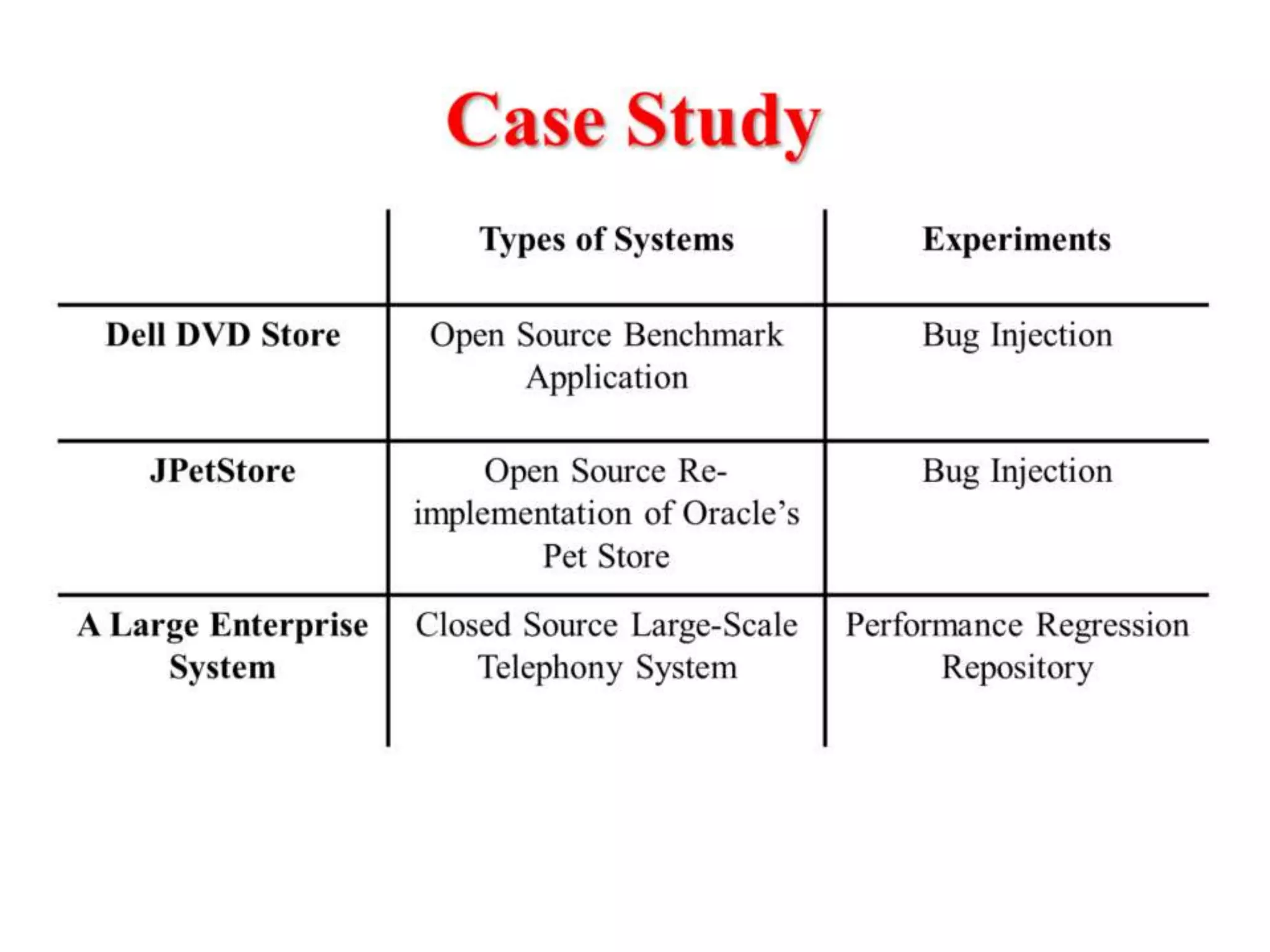
This document presents an approach for automatically detecting performance regressions in heterogeneous environments. It uses association rule mining on performance counter data from past tests to generate performance rules. These rules are then used to detect violation metrics in a new test by identifying significant changes in rule confidence values. Results are combined from multiple heterogeneous lab environments using a weighted voting method based on environment similarities. The approach is evaluated on real-world systems using F-measure and is shown to outperform single model and bagging methods for detecting performance regressions.