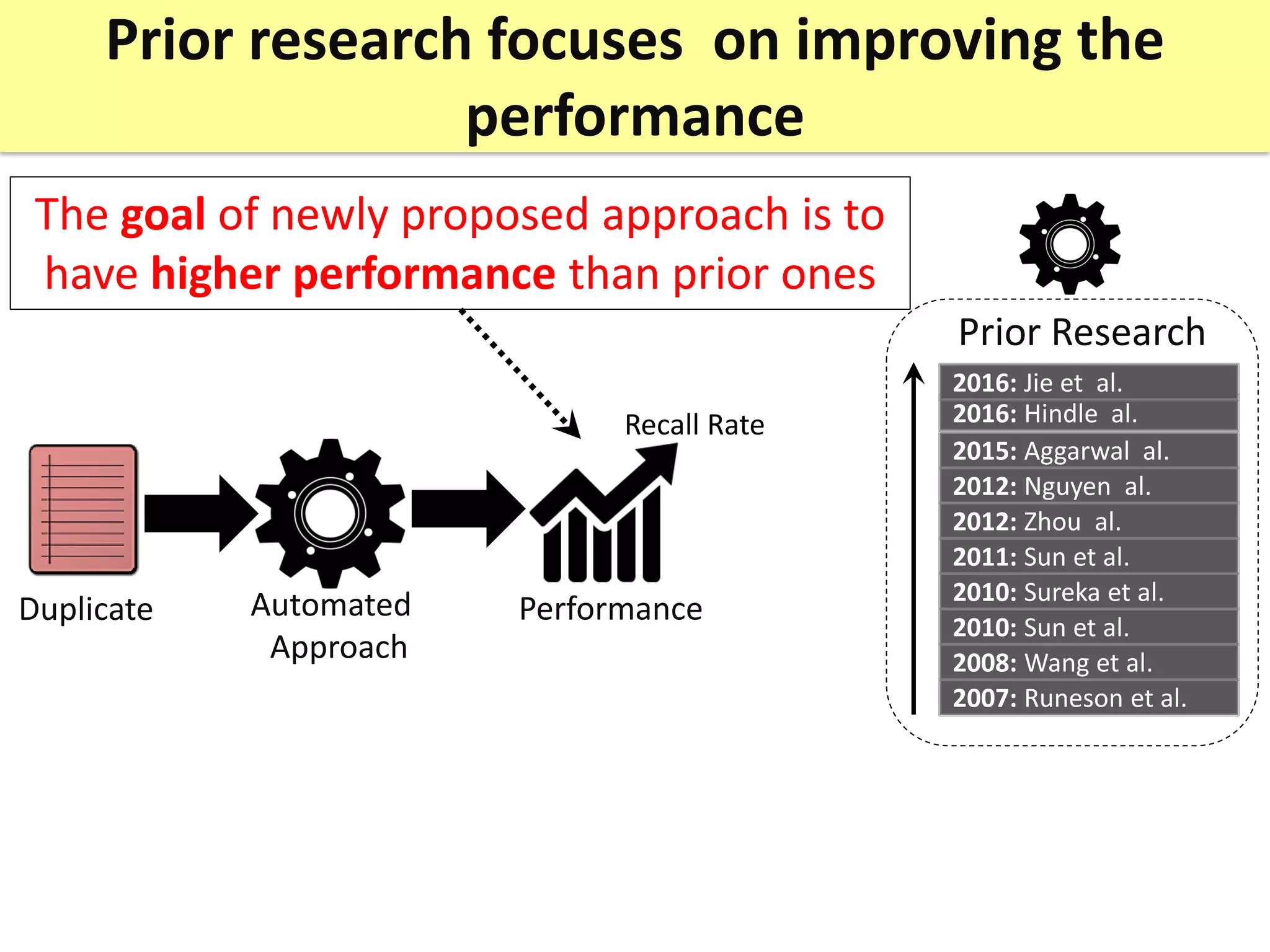
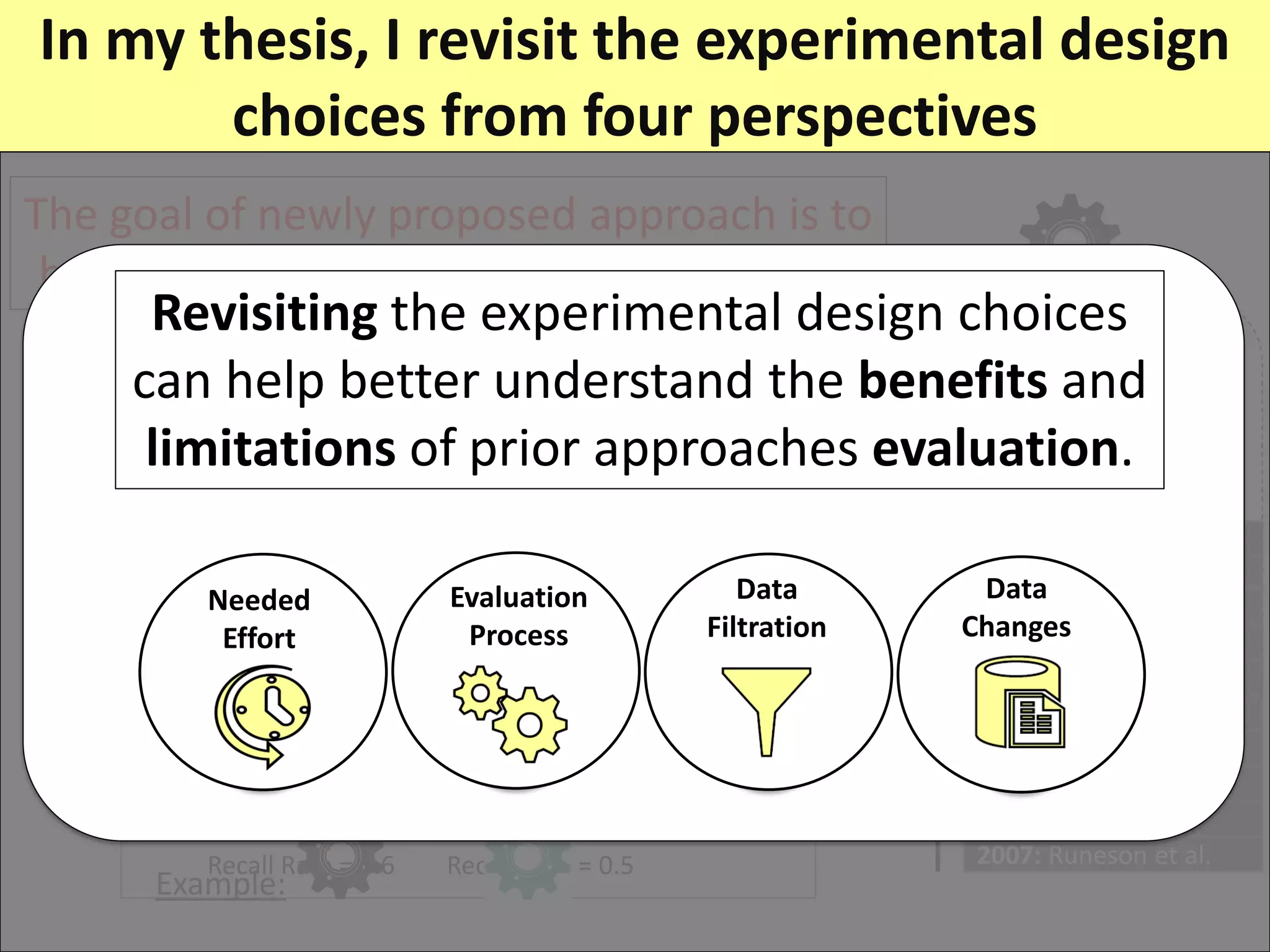
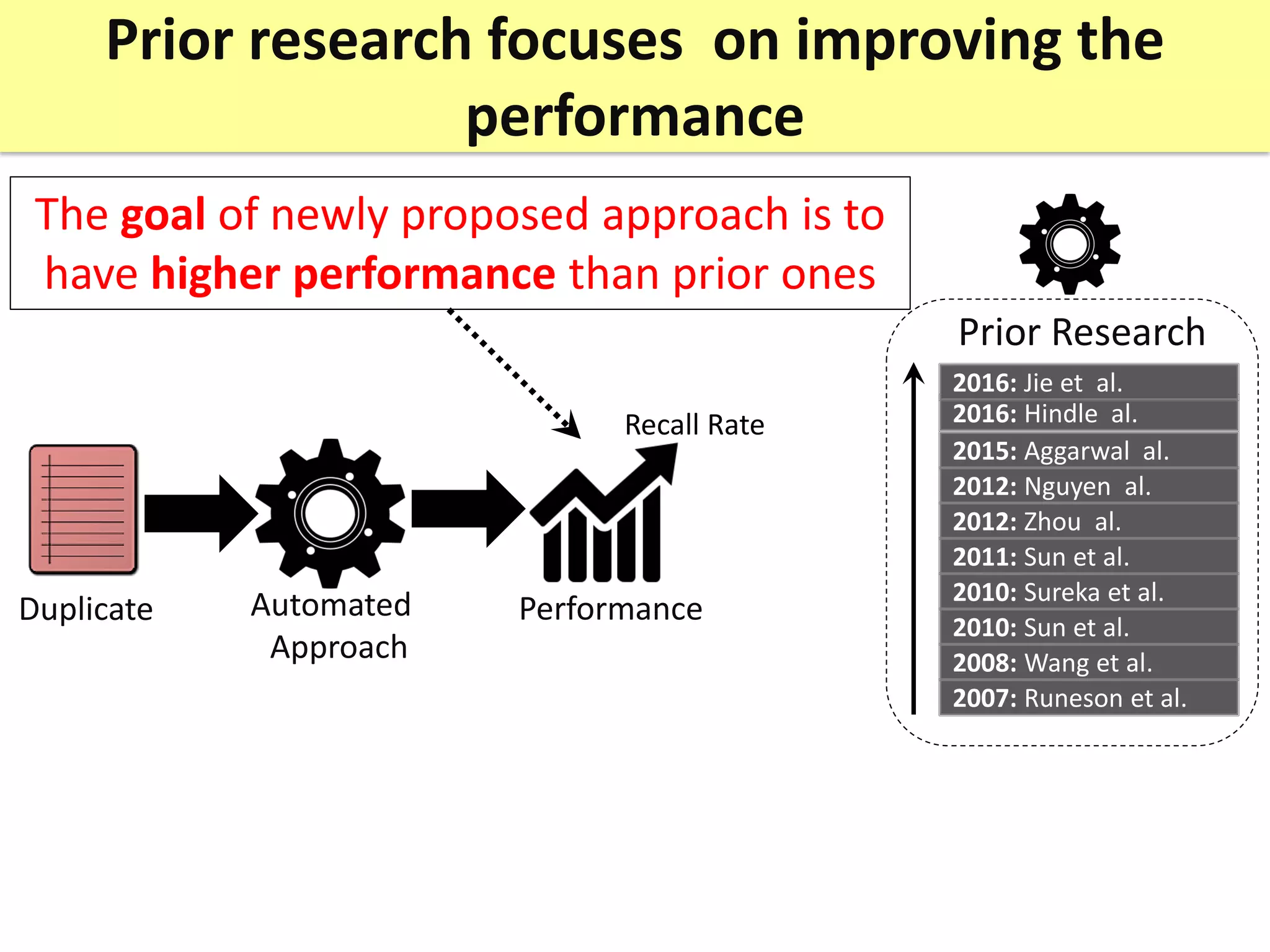
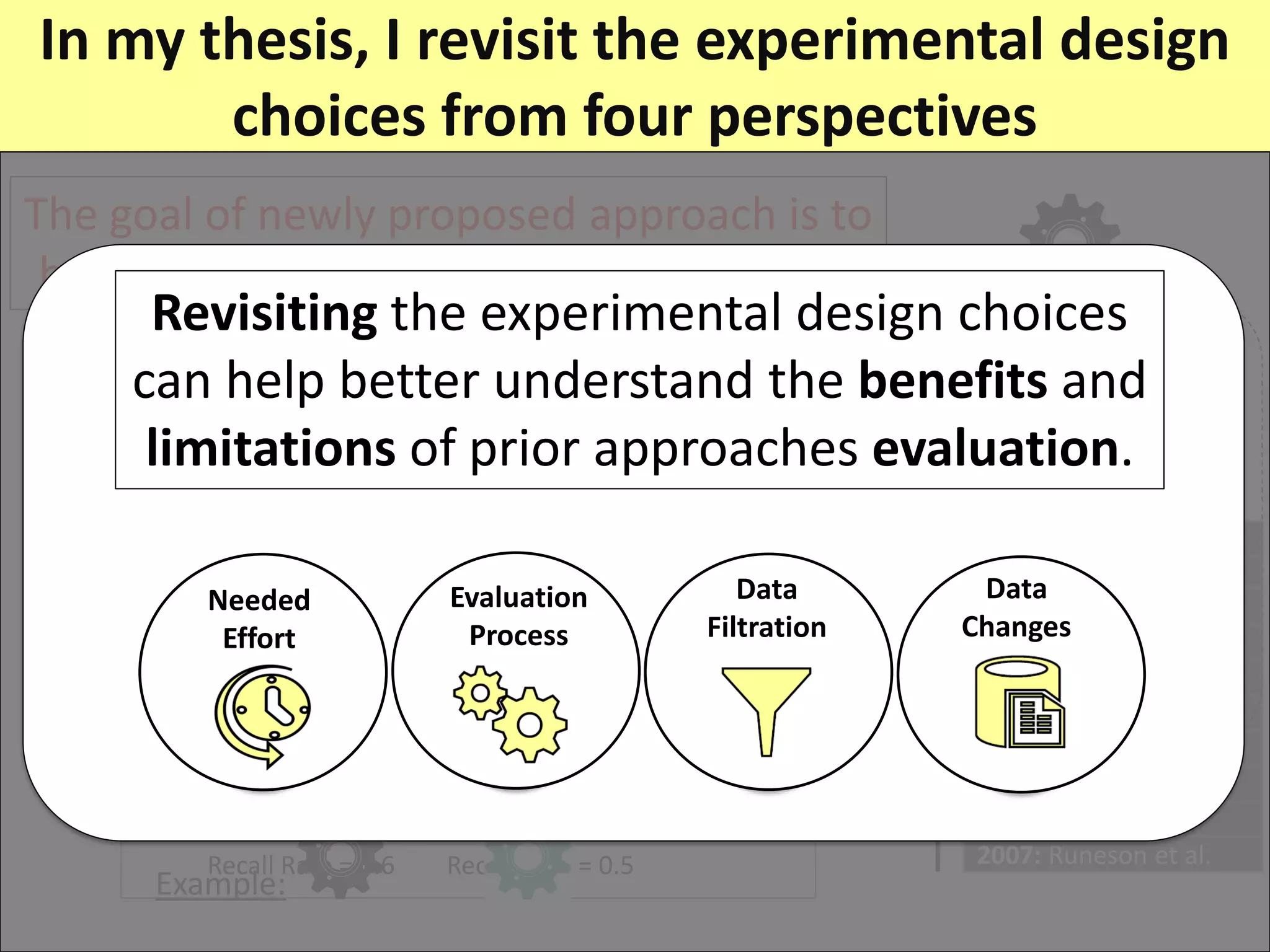
Prior research on automated duplicate issue report retrieval focused on improving performance metrics like recall rate. The author revisits experimental design choices from four perspectives: needed effort, data changes, data filtration, and evaluation process.
The thesis contributions are: 1) Showing the importance of considering needed effort in performance measurement. 2) Proposing a "realistic evaluation" approach and analyzing prior findings with it. 3) Developing a genetic algorithm to filter old issue reports and improve performance. 4) Highlighting the impact of "just-in-time" features on evaluation. The findings help better understand benefits and limitations of prior work in this area.



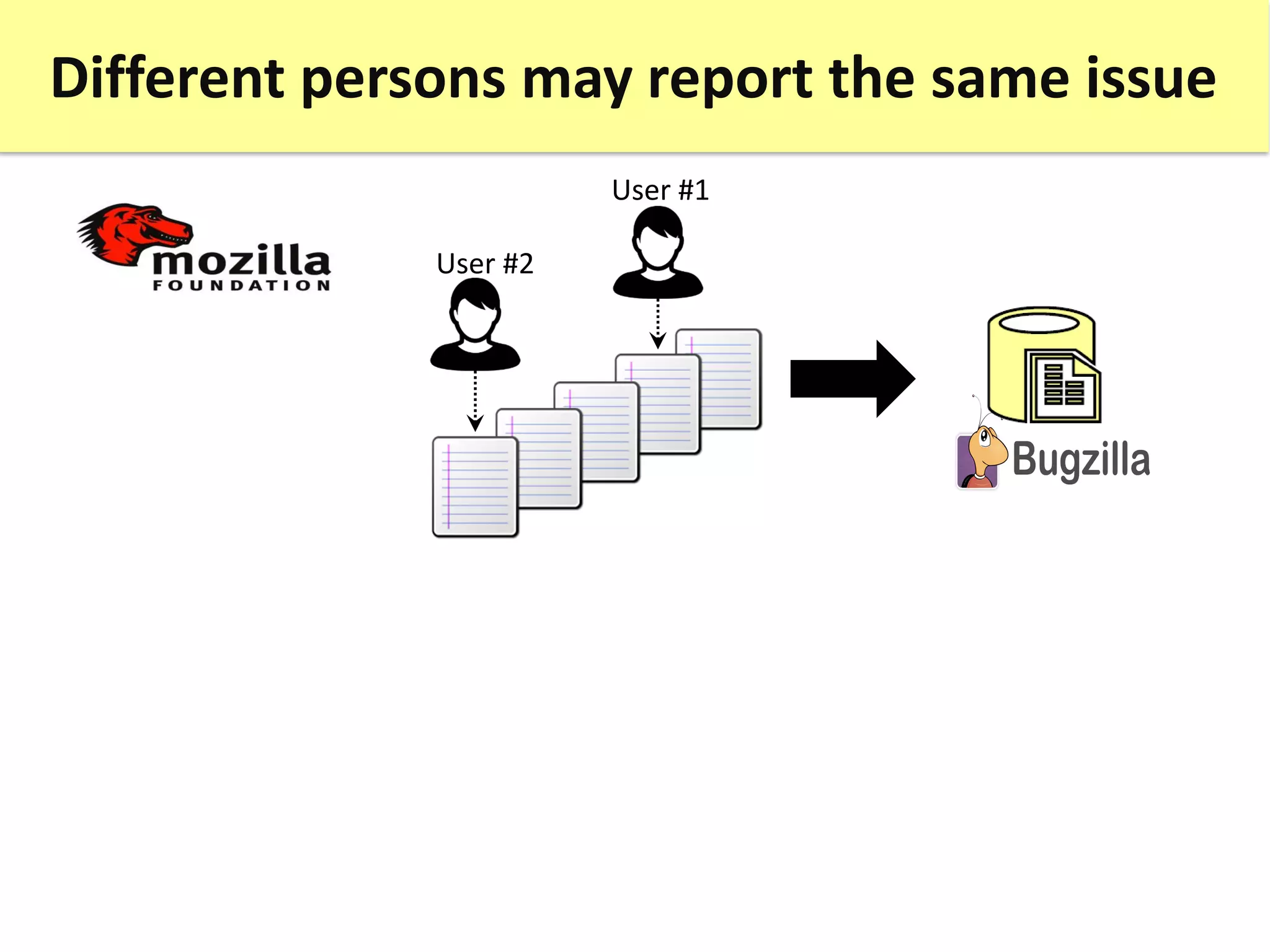
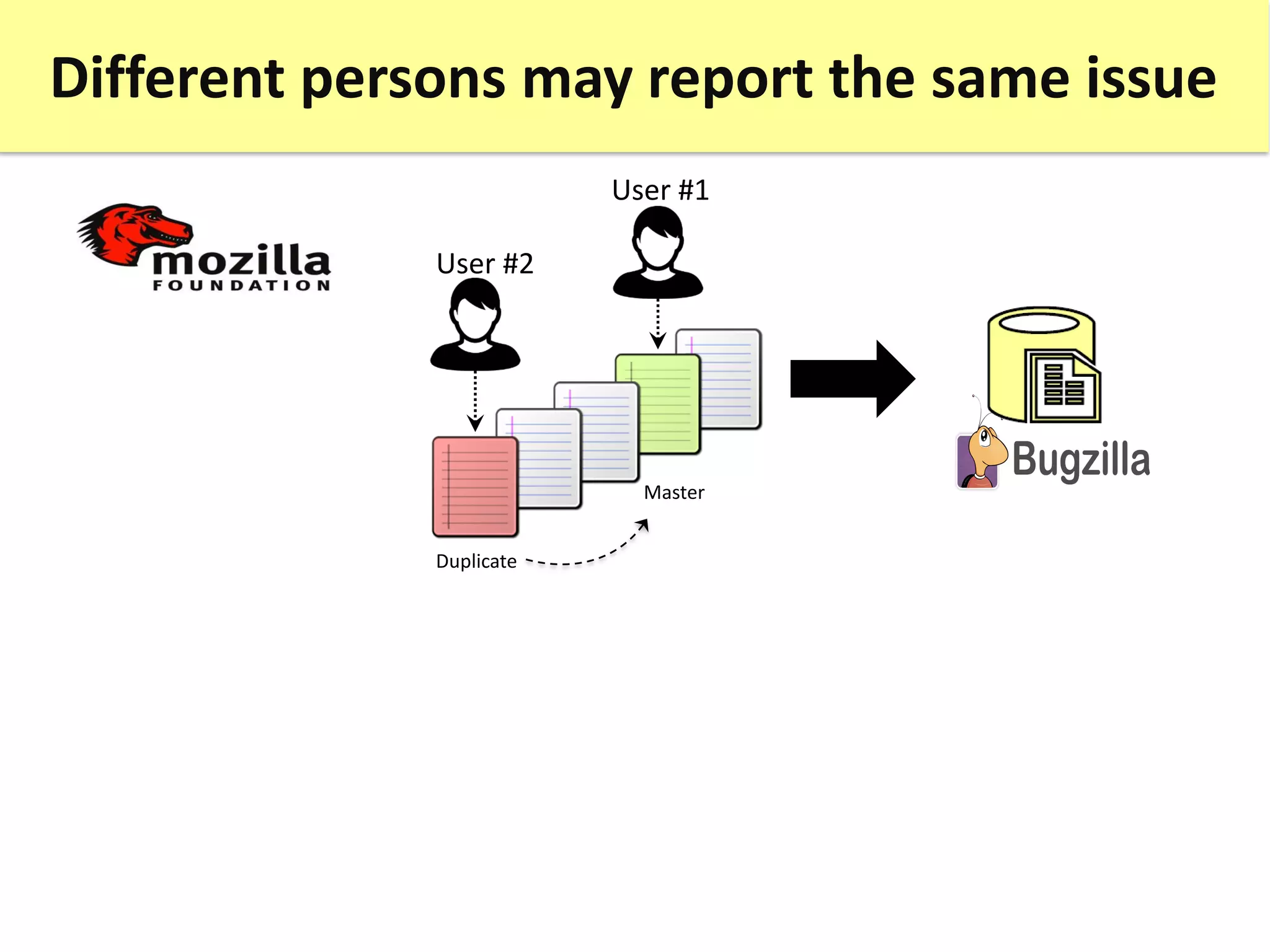
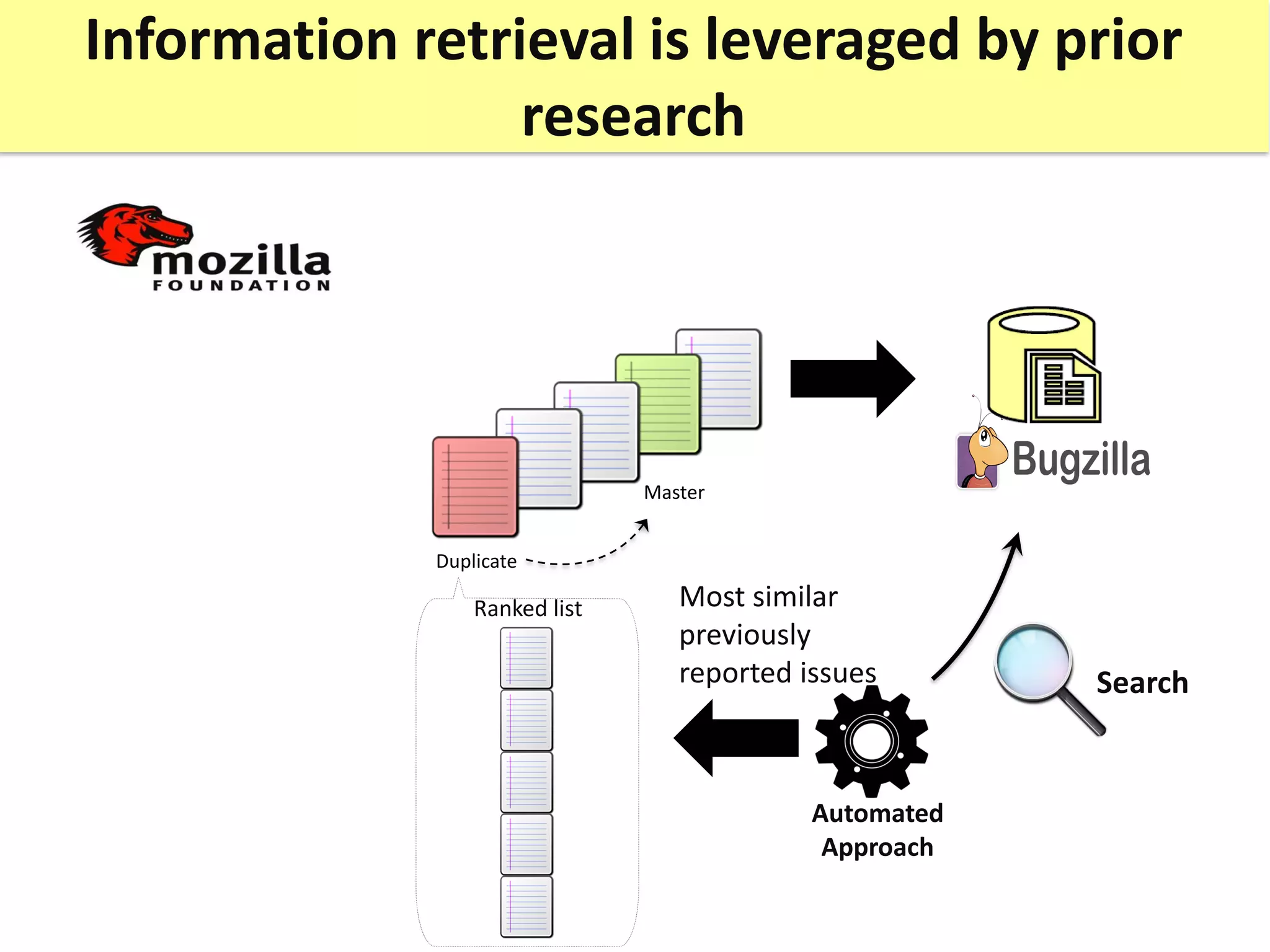
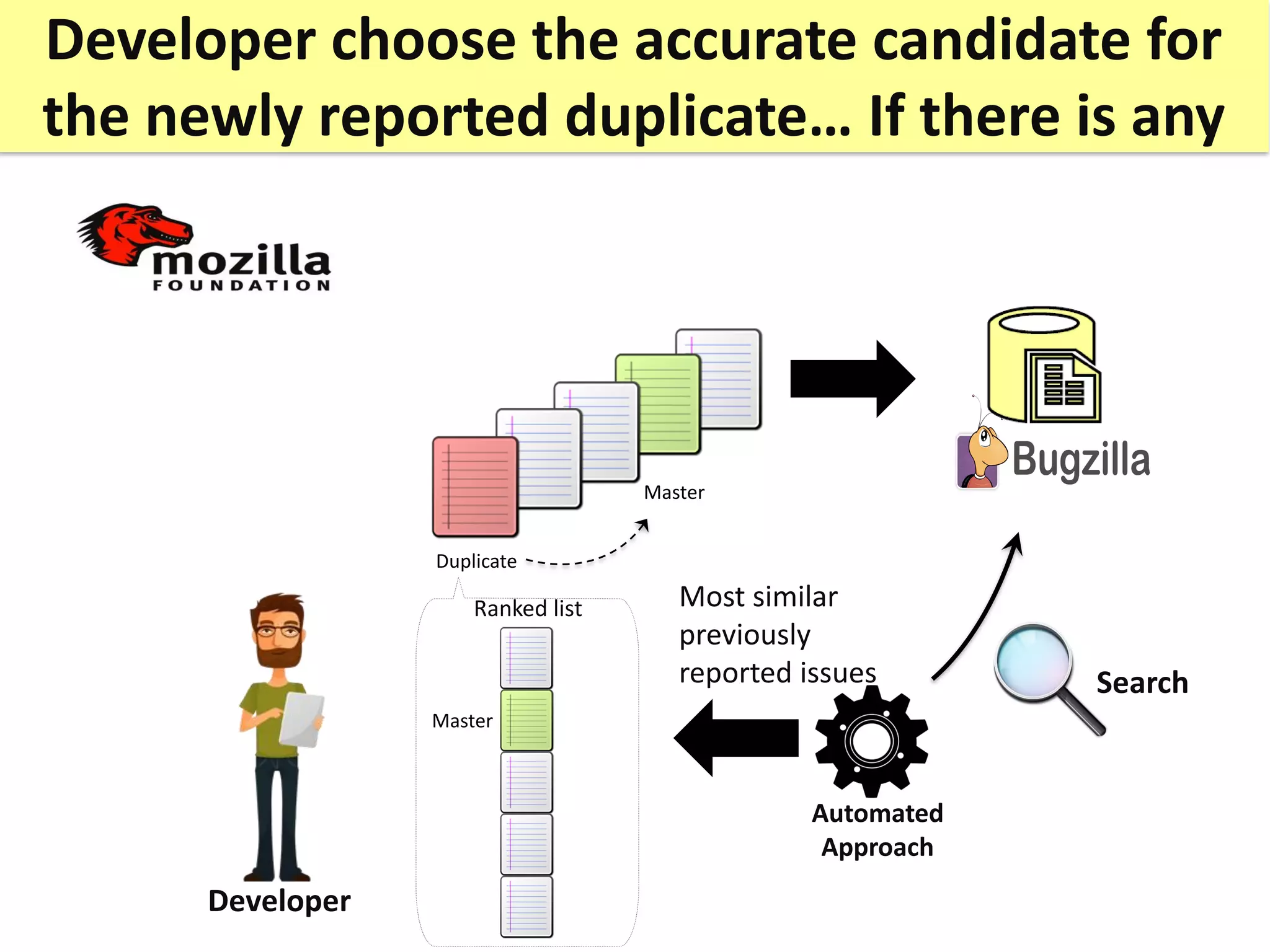
![The identification of duplicate issue reports is
an annoying and timewasting task
User #2
User #1
Duplicate
20-30%
Duplicates! Master
Bettenburg et al. Duplicate bug reports considered harmful… really? [ICSM 2008:]](https://image.slidesharecdn.com/mohamedsamirakhaphddefense-180828152040/75/Revisiting-the-Experimental-Design-Choices-for-Approaches-for-the-Automated-Retrieval-of-Duplicate-Issue-Reports-8-2048.jpg)

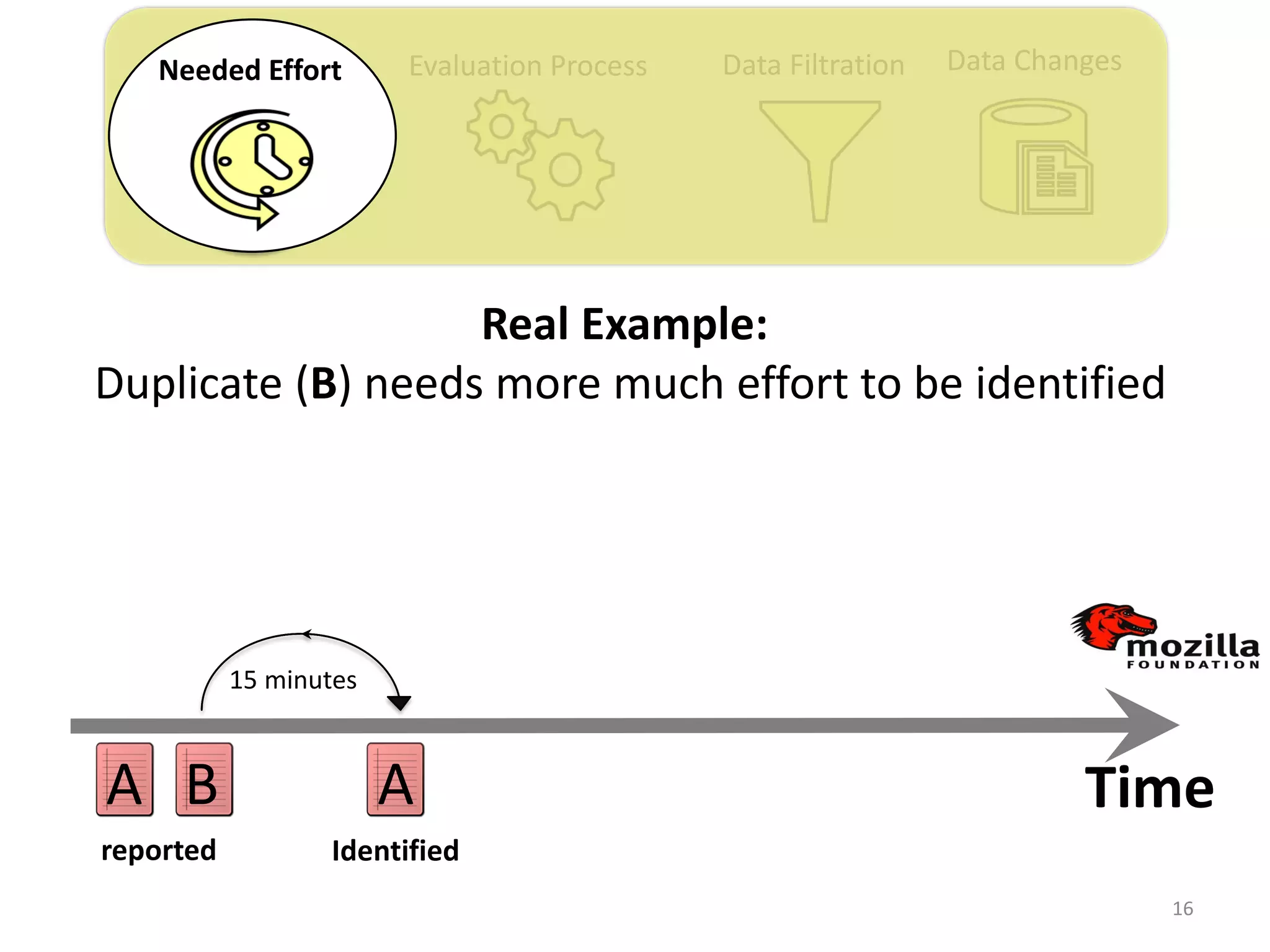
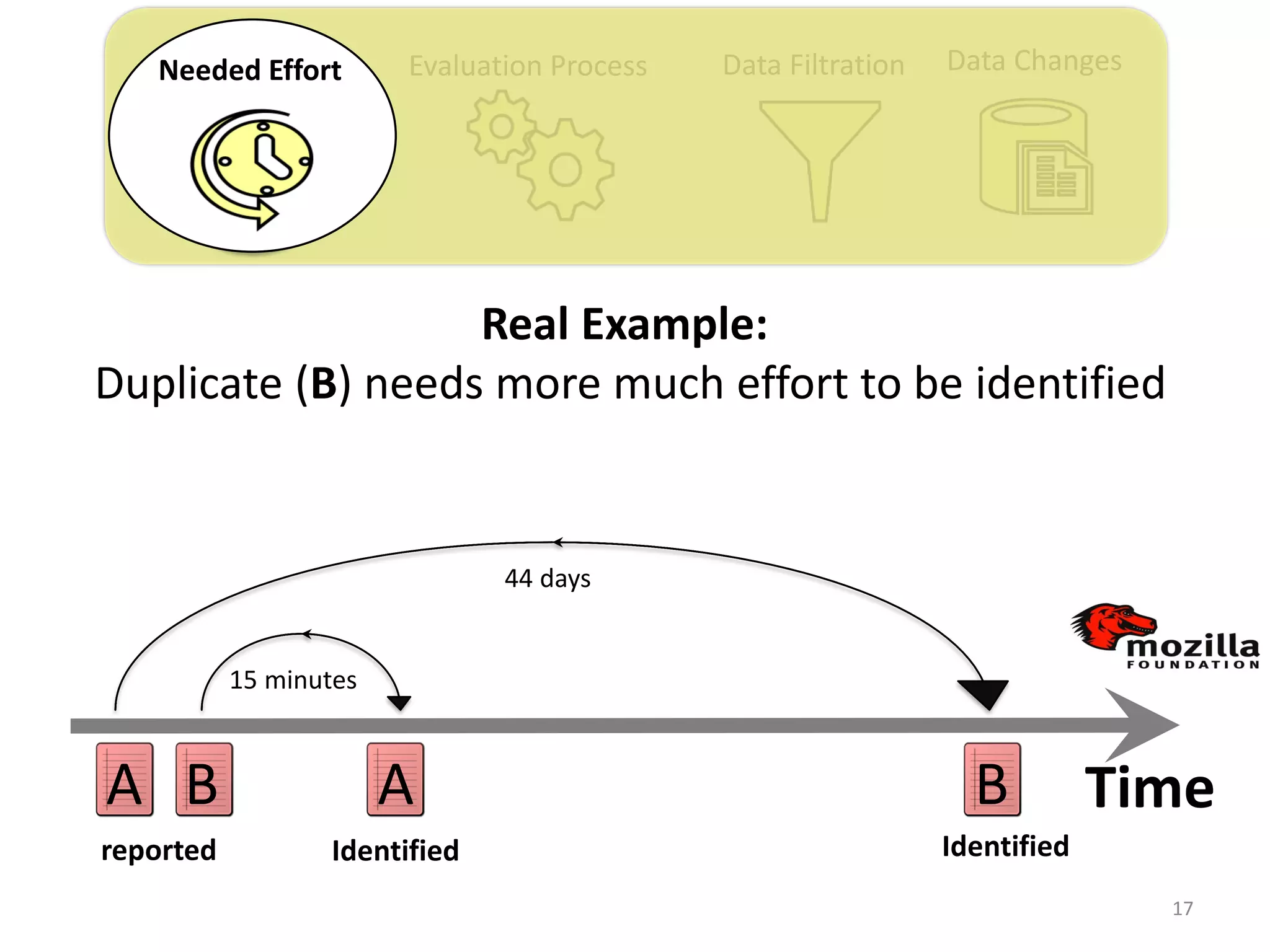

![Evaluation Process Data Filtration Data ChangesNeeded Effort
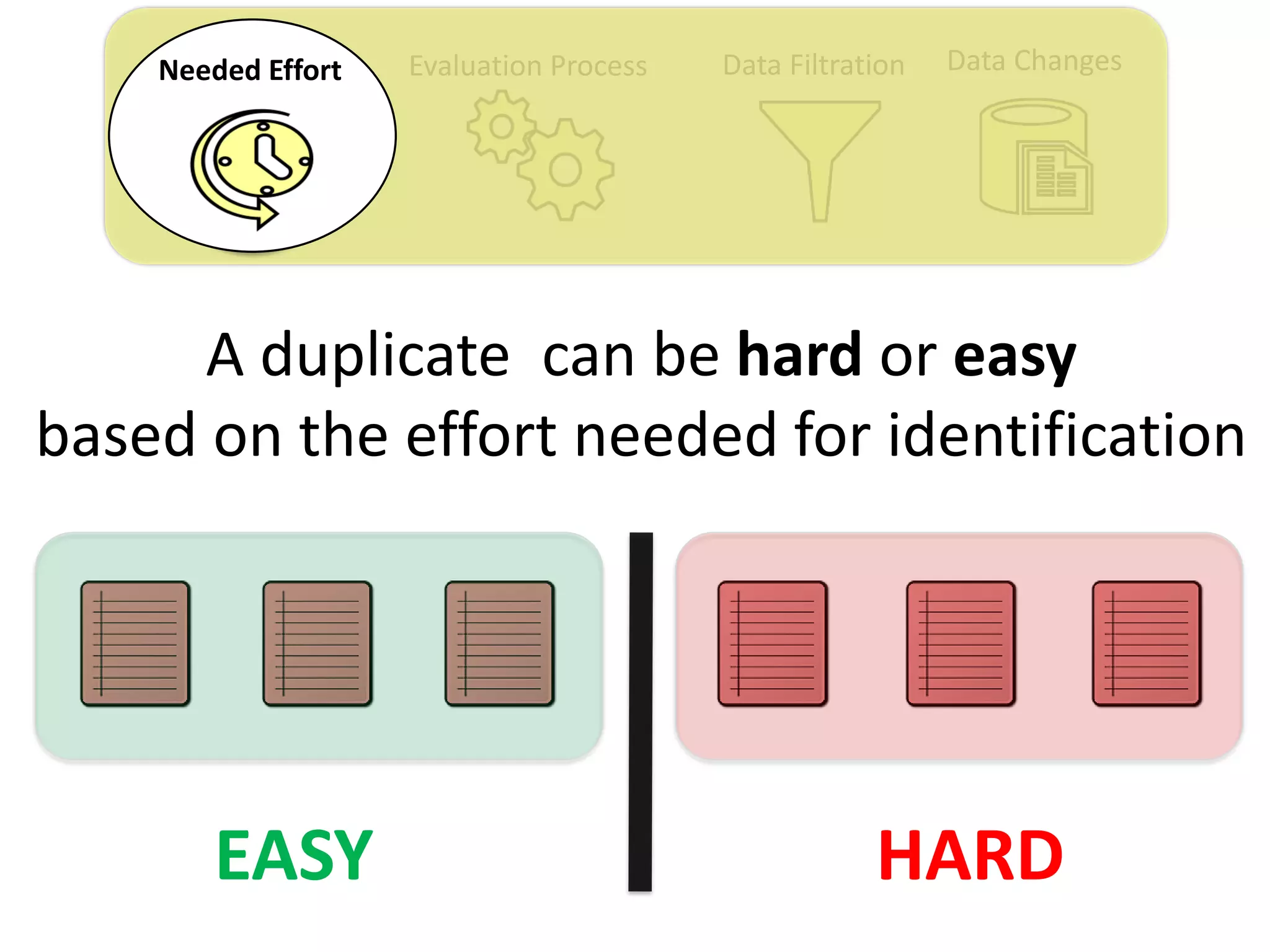
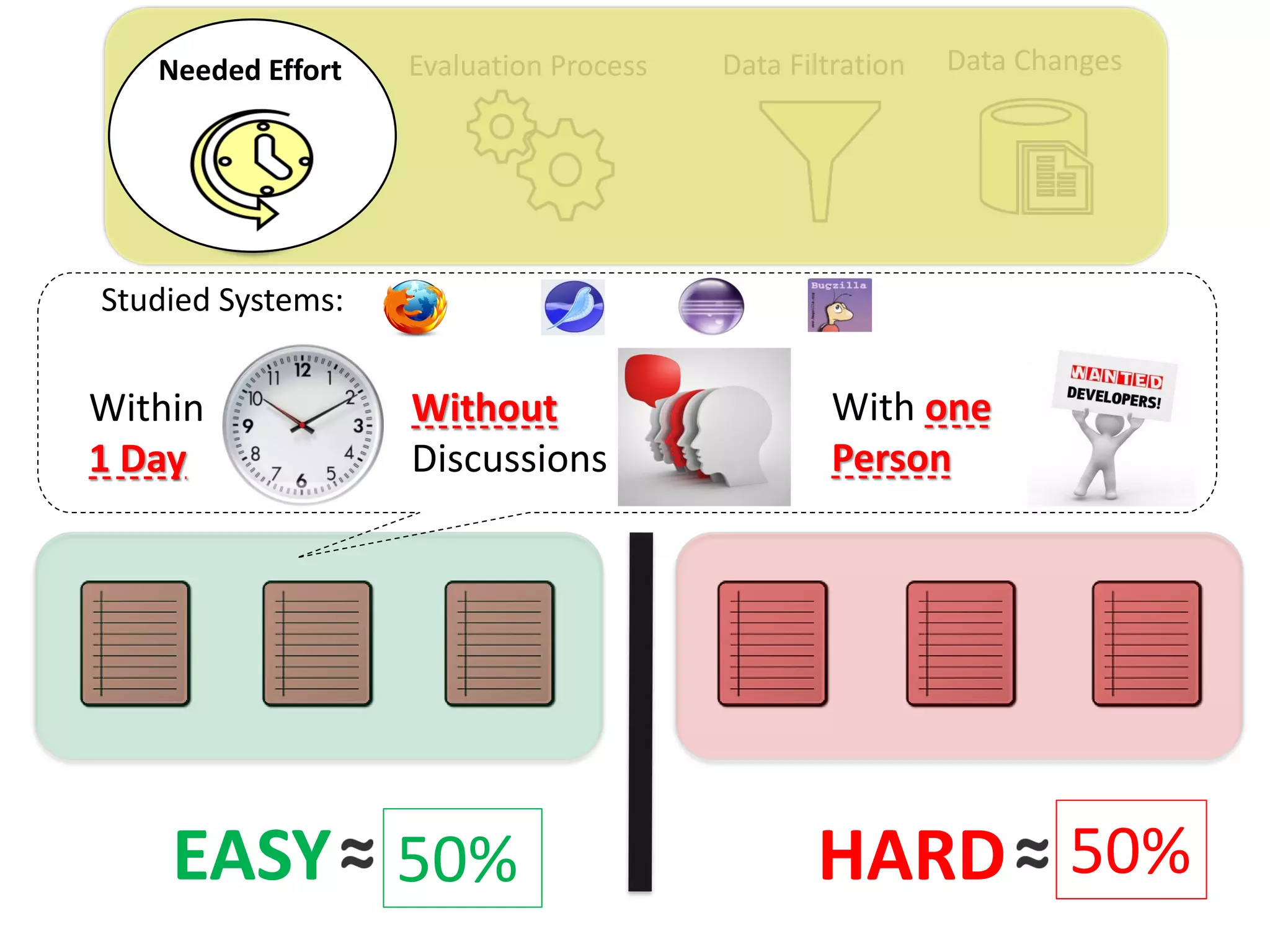
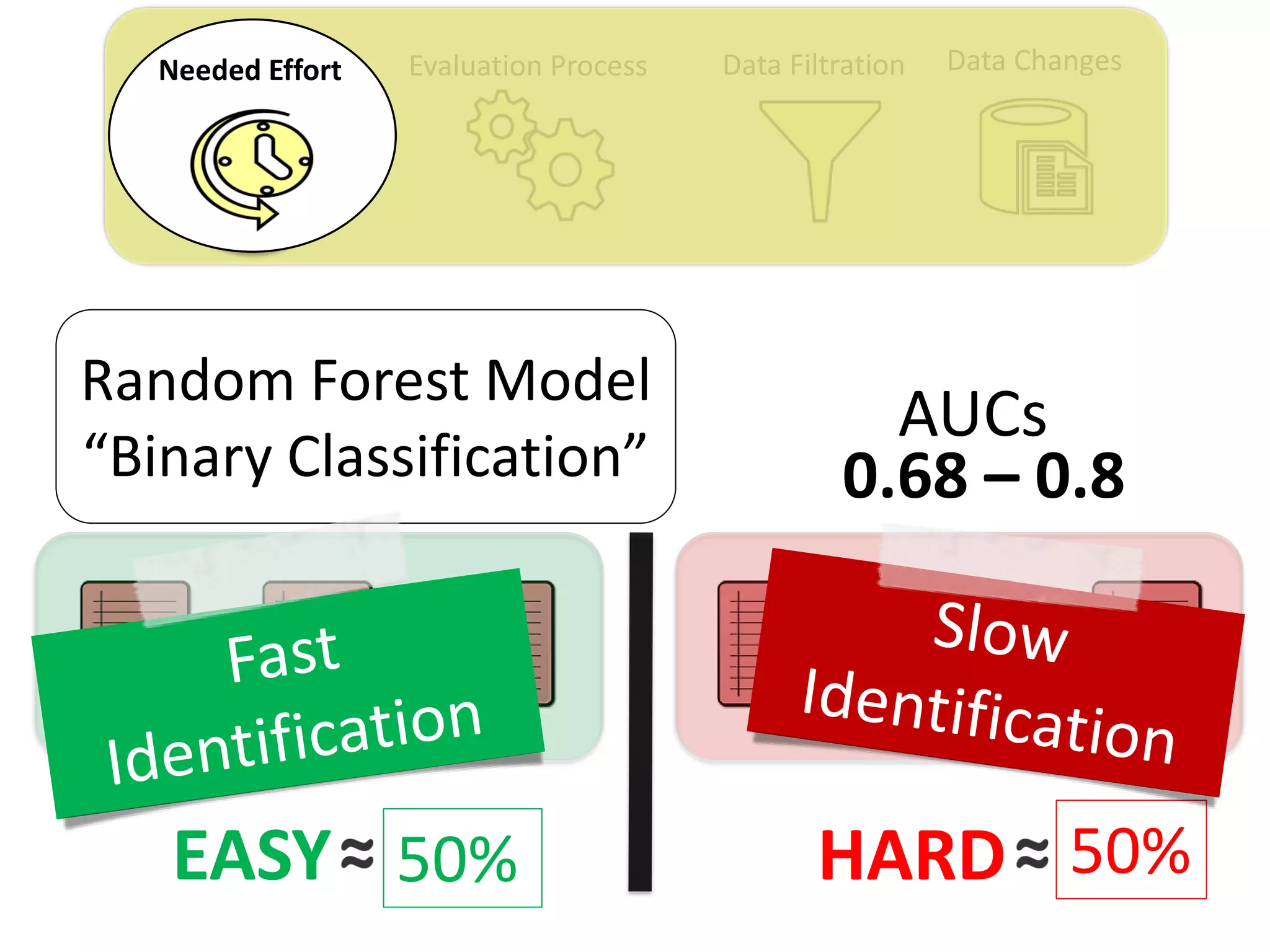
Thesis Contribution #1:
Show the importance of considering the needed
effort for retrieving duplicate reports in the
performance measurement of automated duplicate
retrieval approaches
[Published in EMSE 2015]](https://image.slidesharecdn.com/mohamedsamirakhaphddefense-180828152040/75/Revisiting-the-Experimental-Design-Choices-for-Approaches-for-the-Automated-Retrieval-of-Duplicate-Issue-Reports-22-2048.jpg)


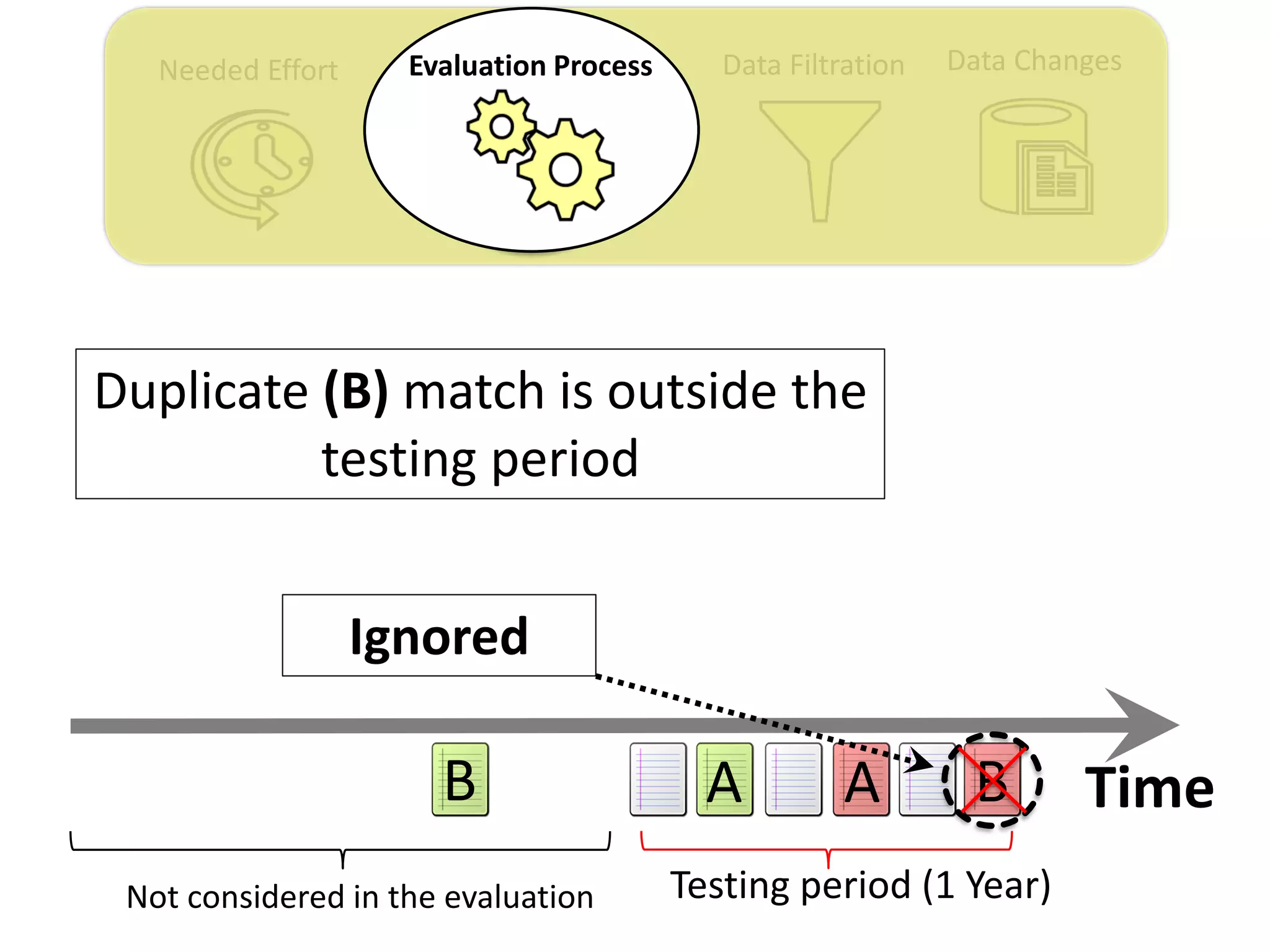
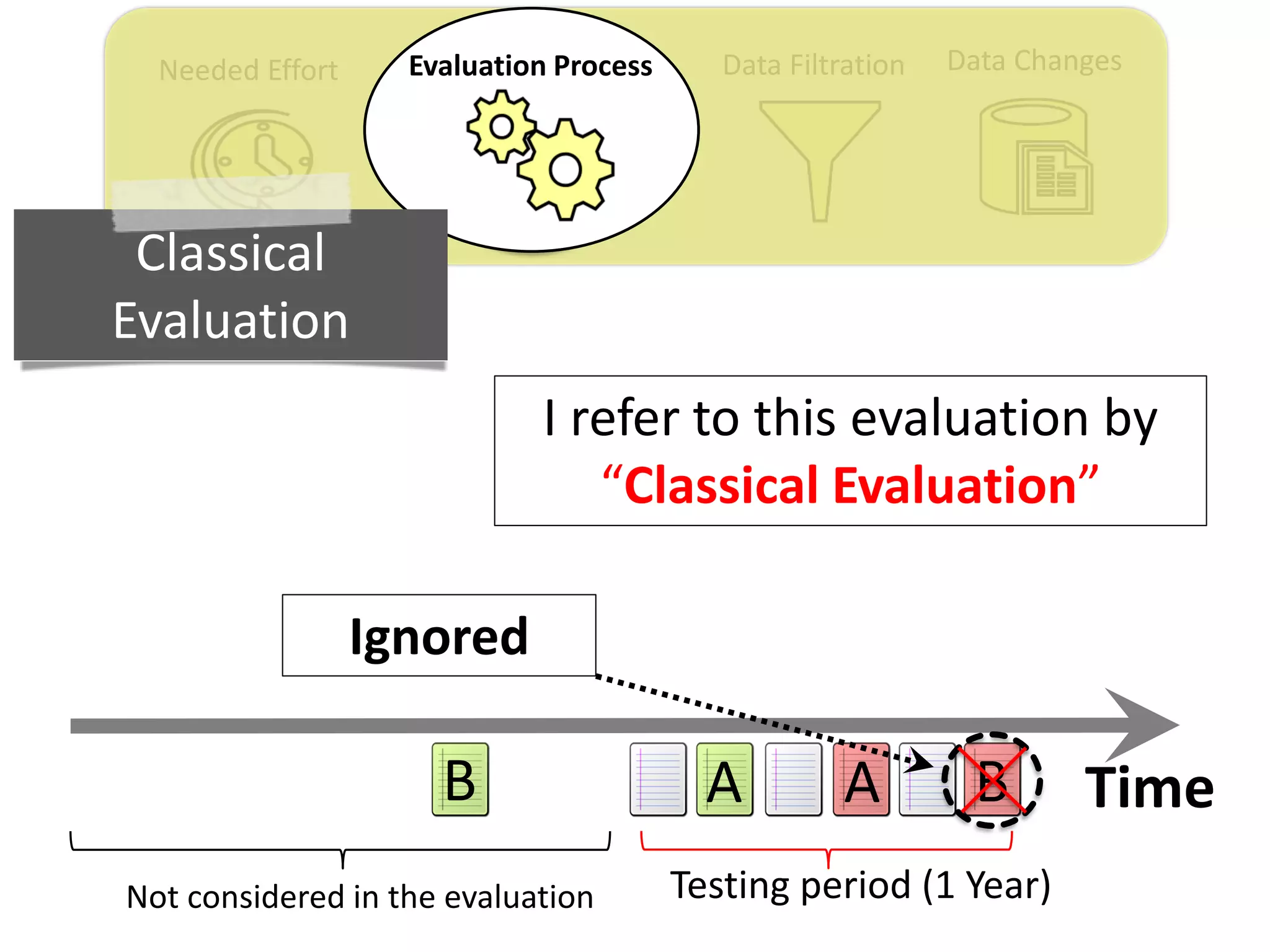
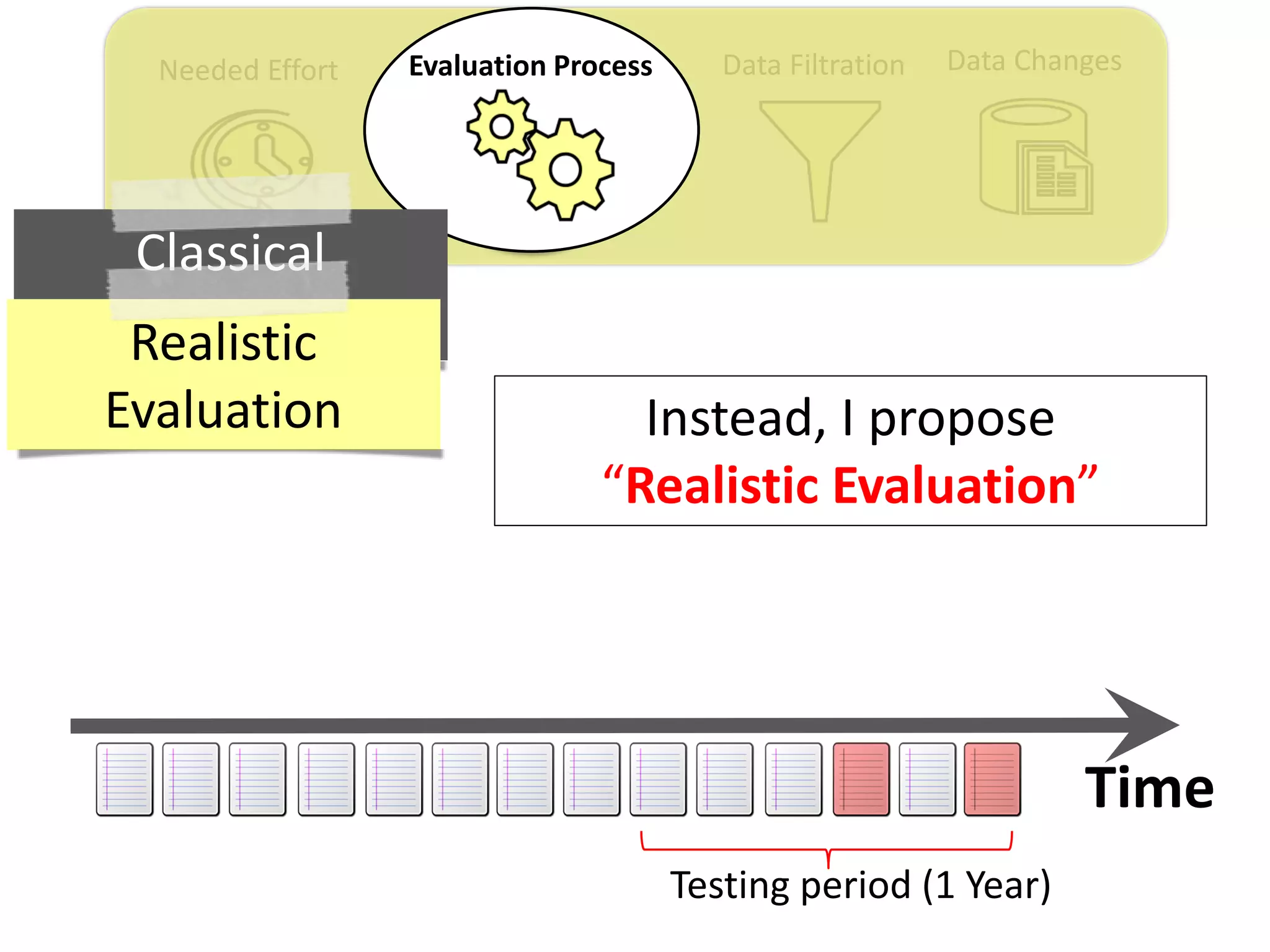
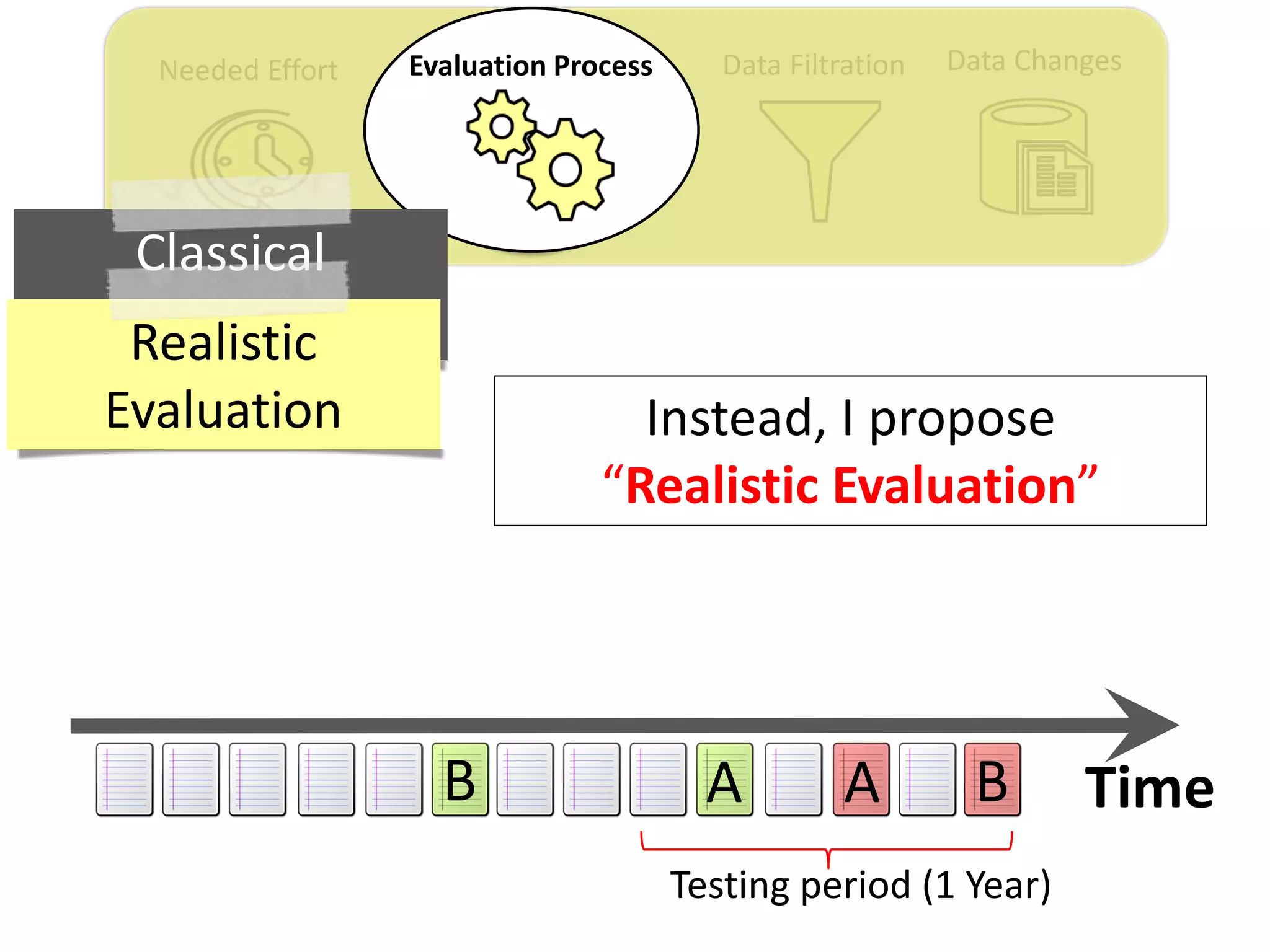
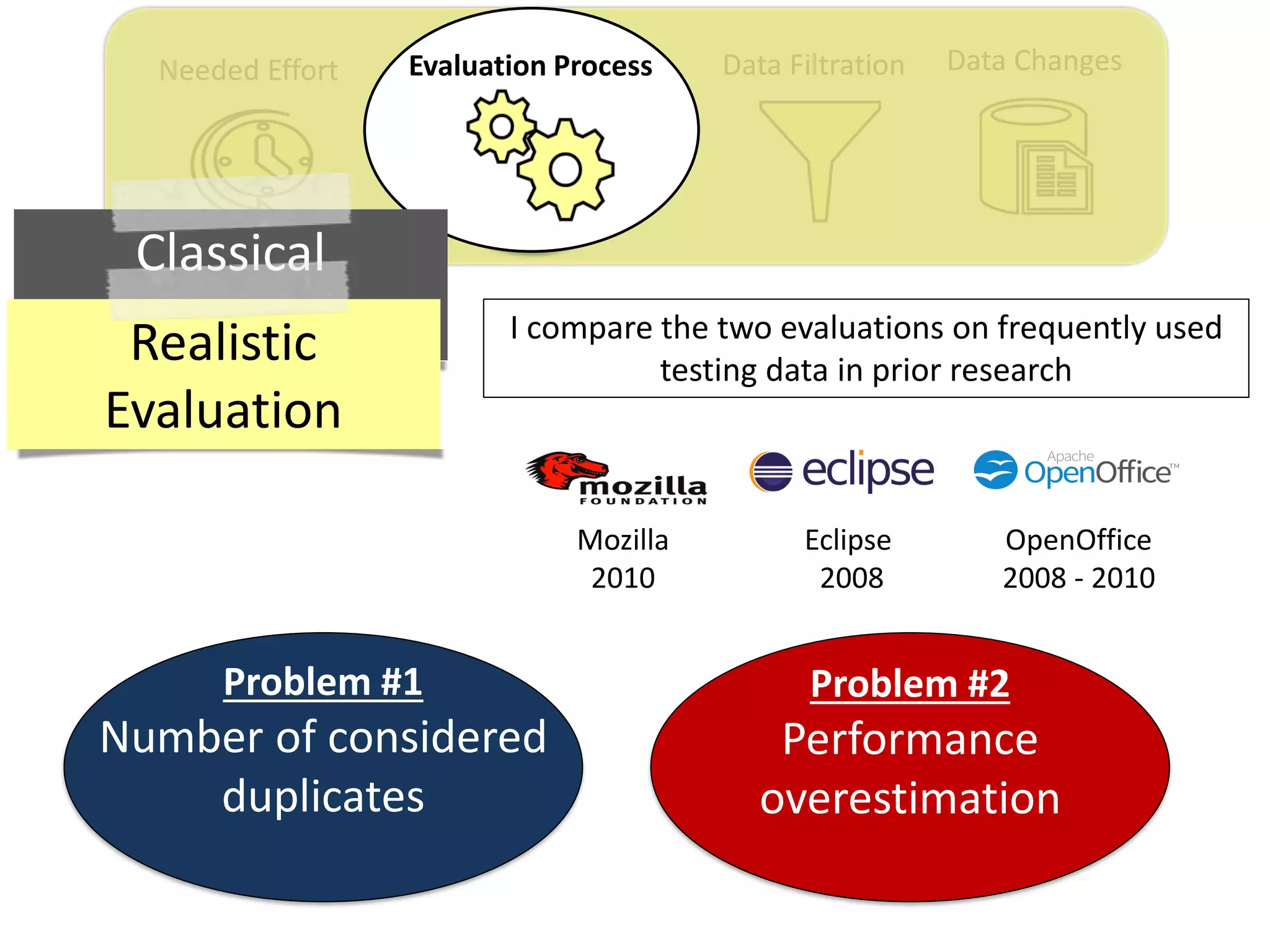
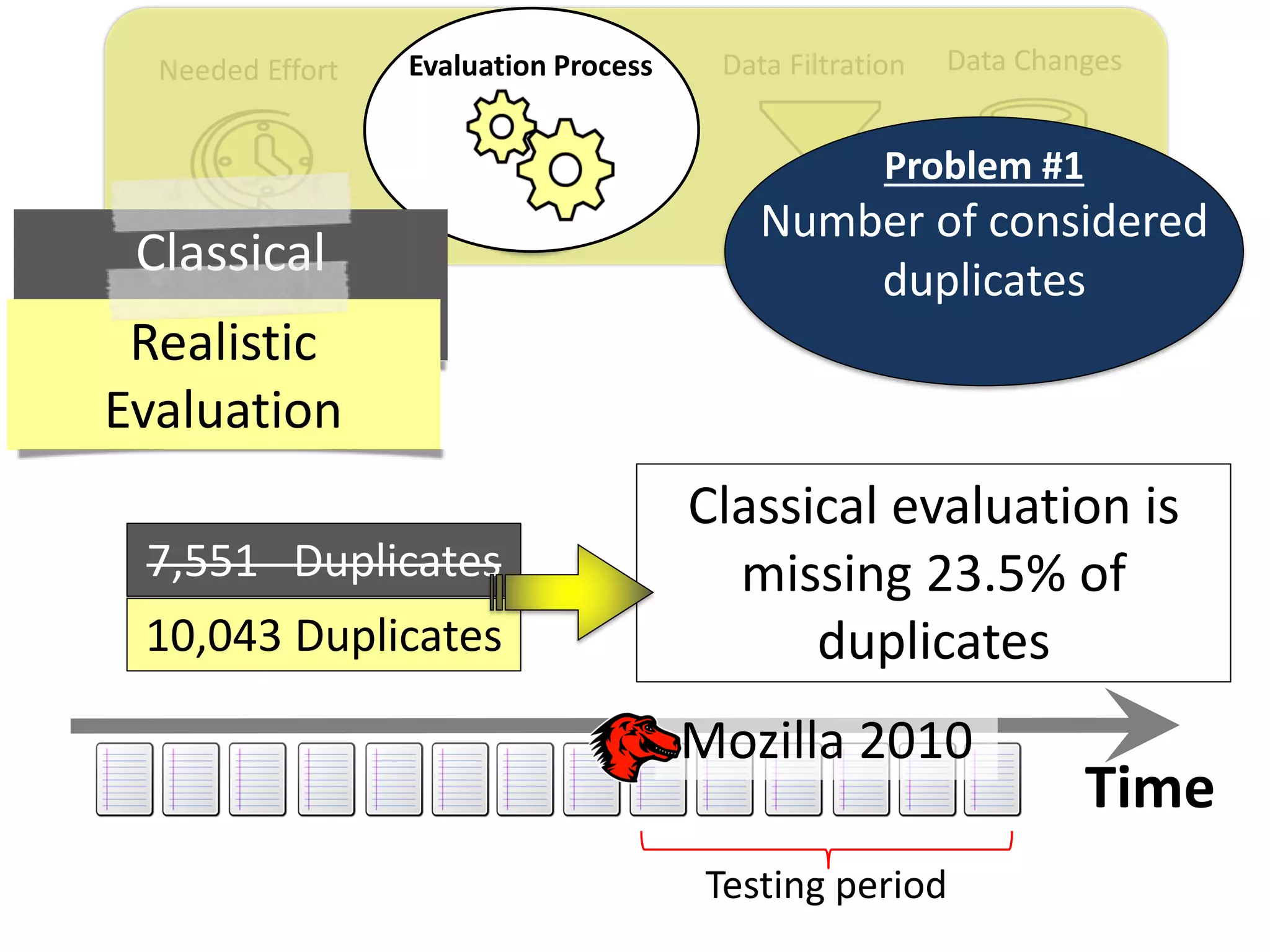
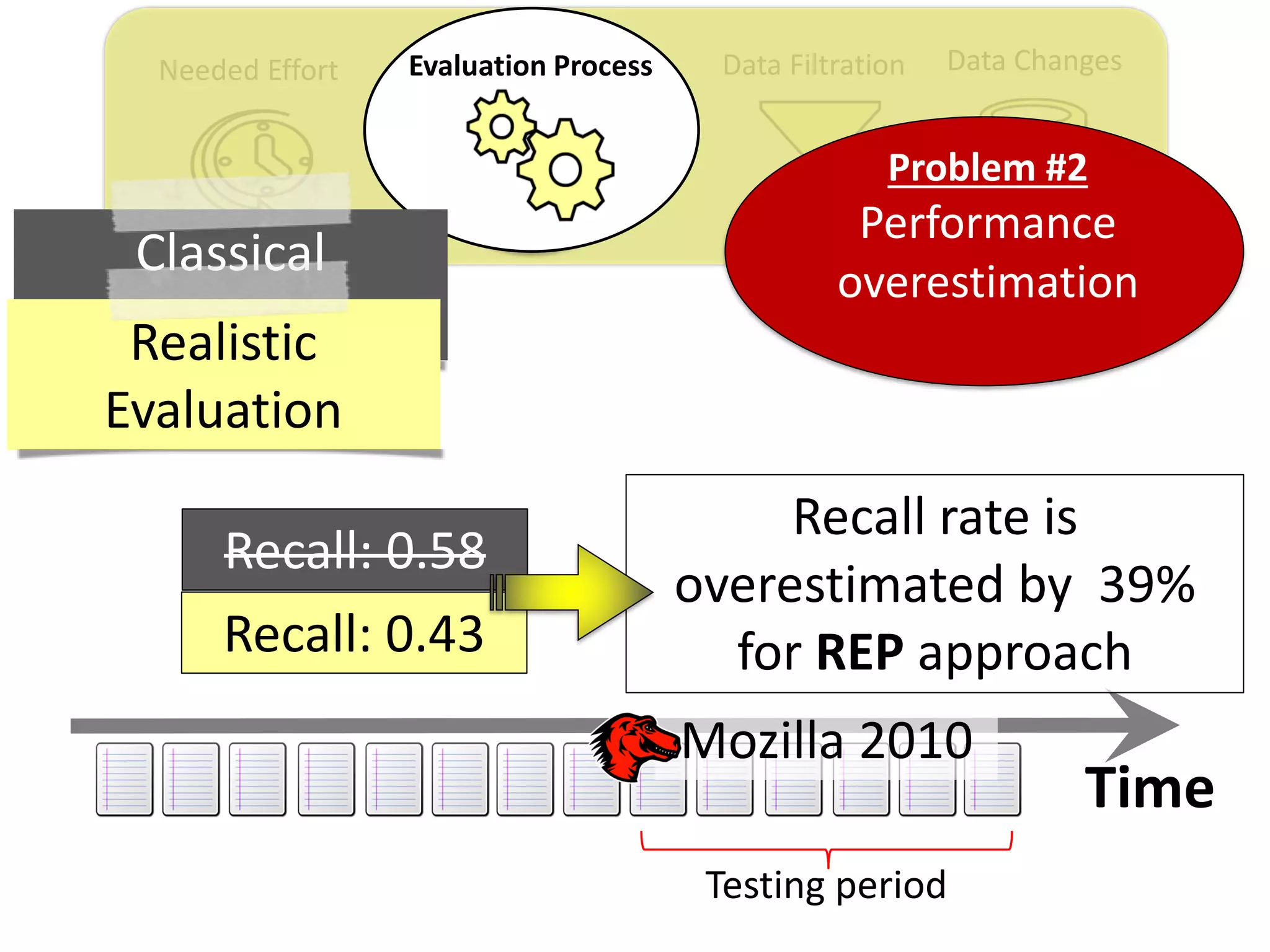
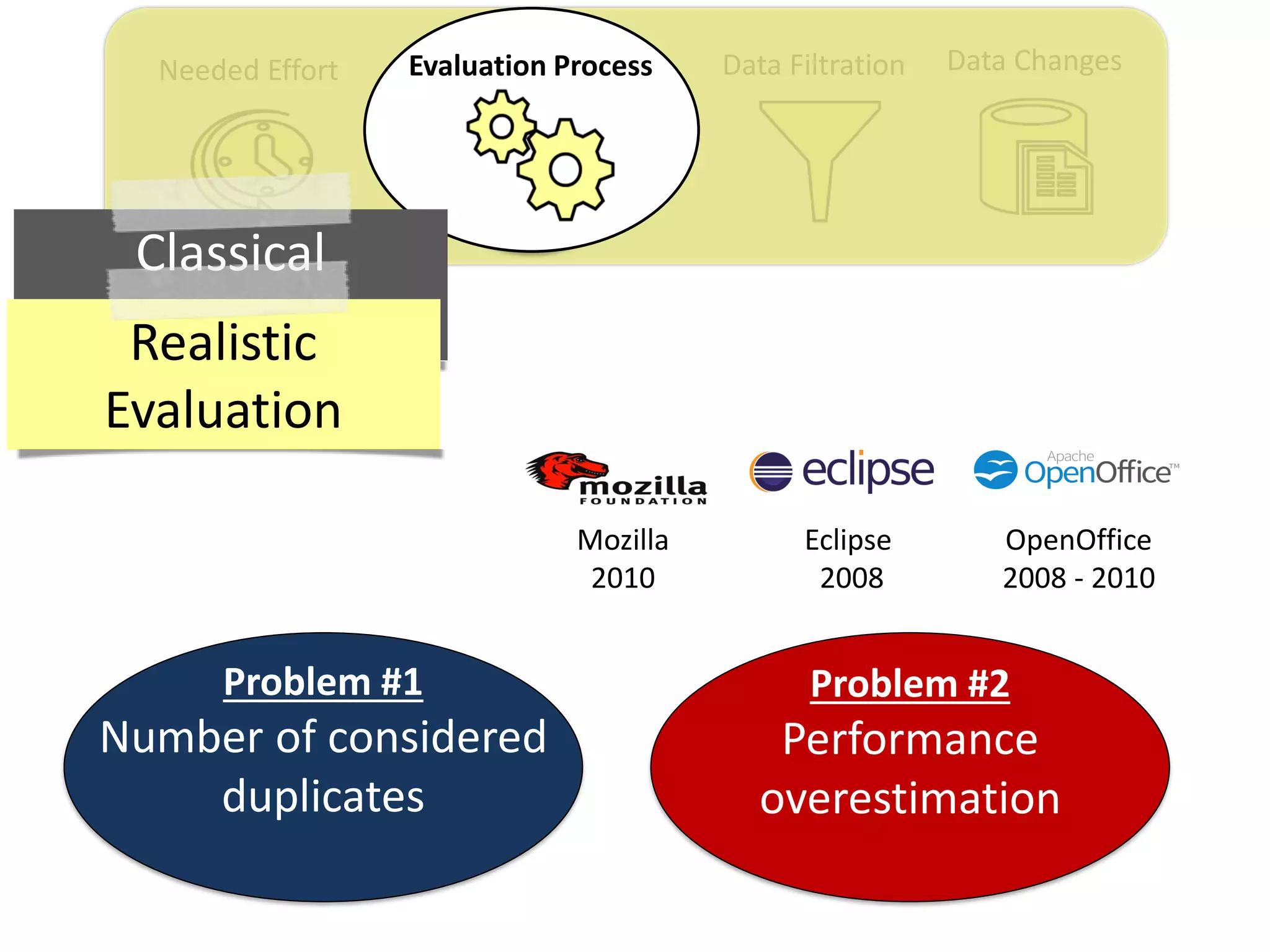
![Data ChangesData FiltrationNeeded Effort Evaluation Process
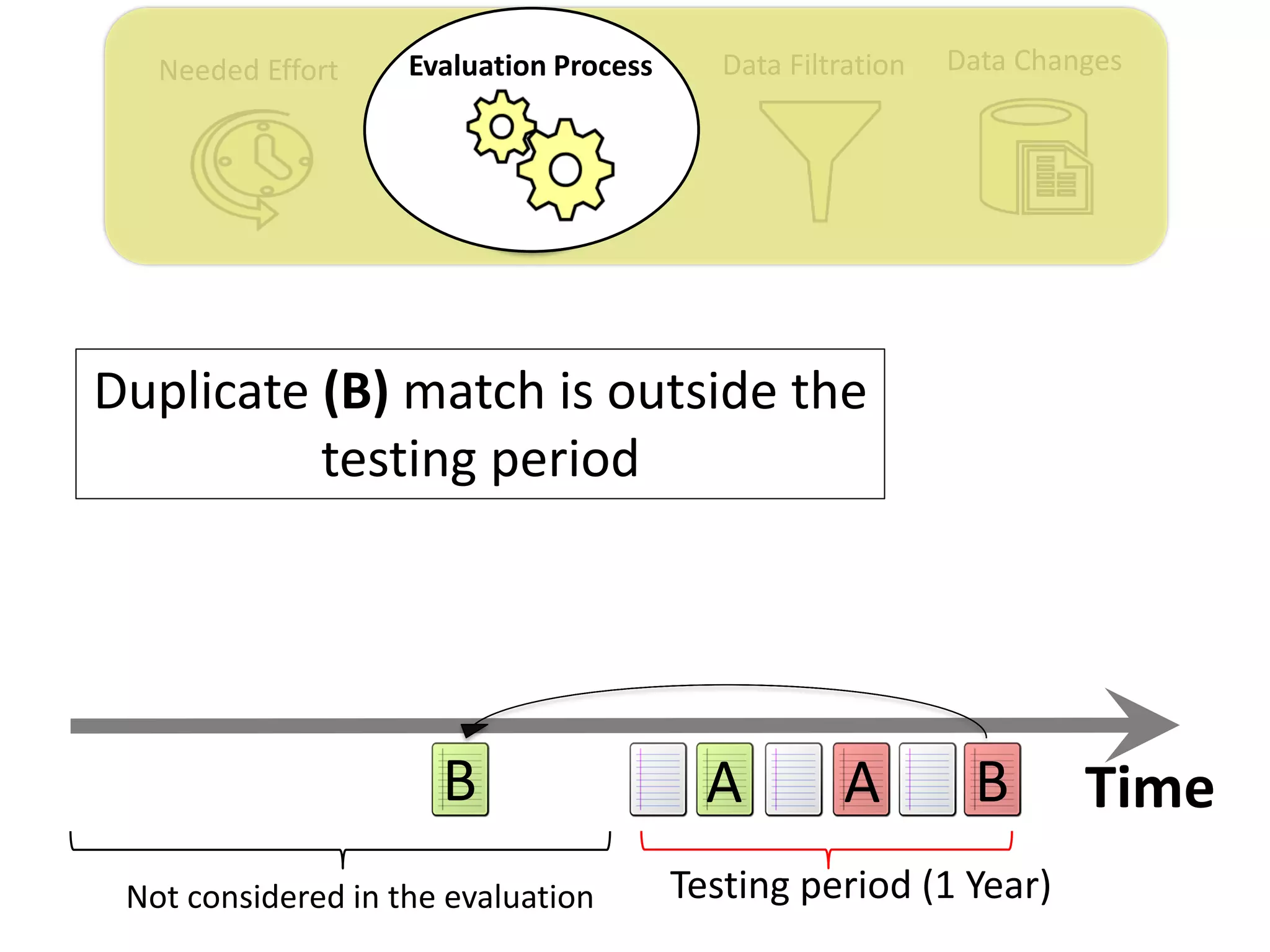
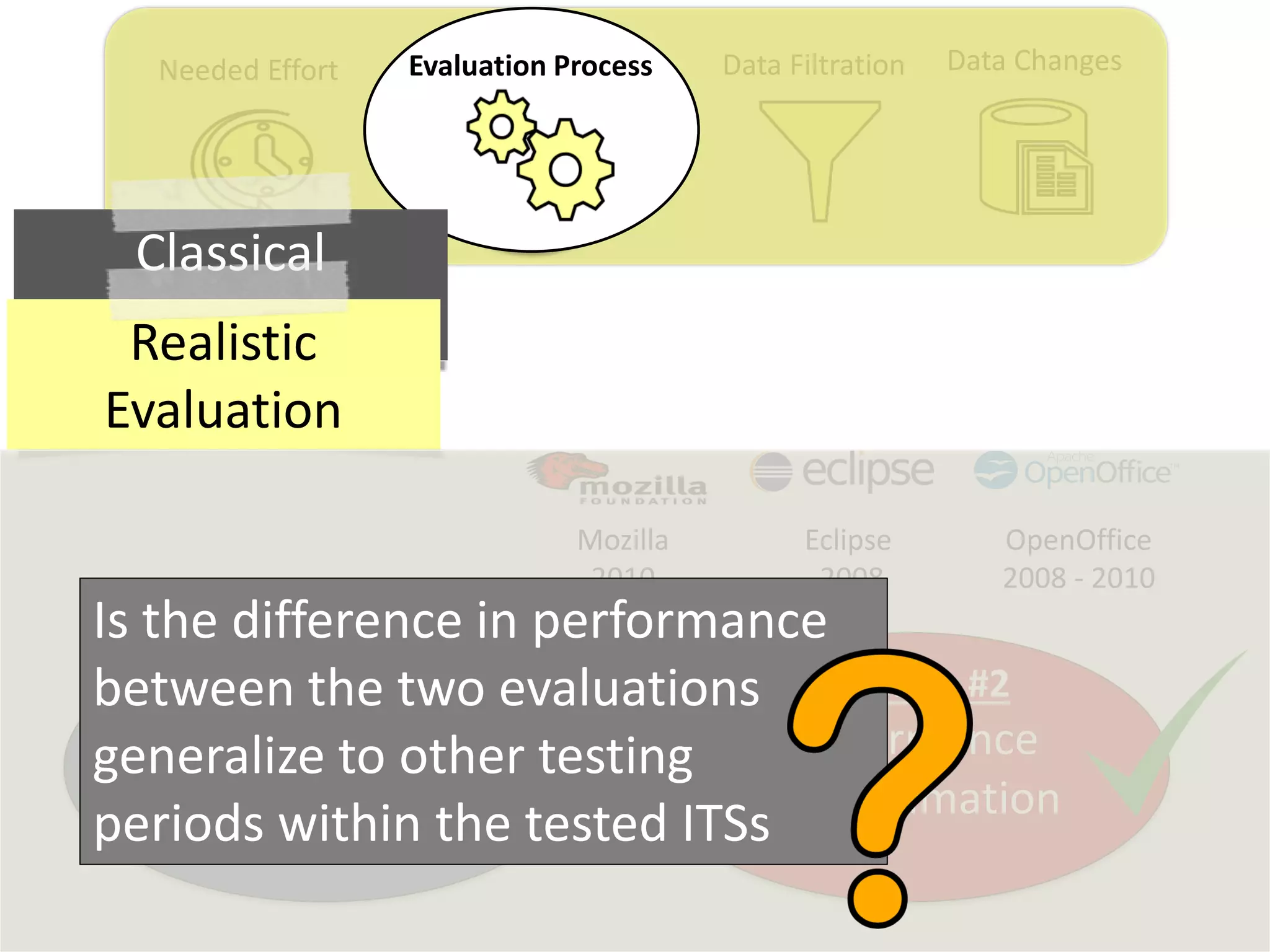
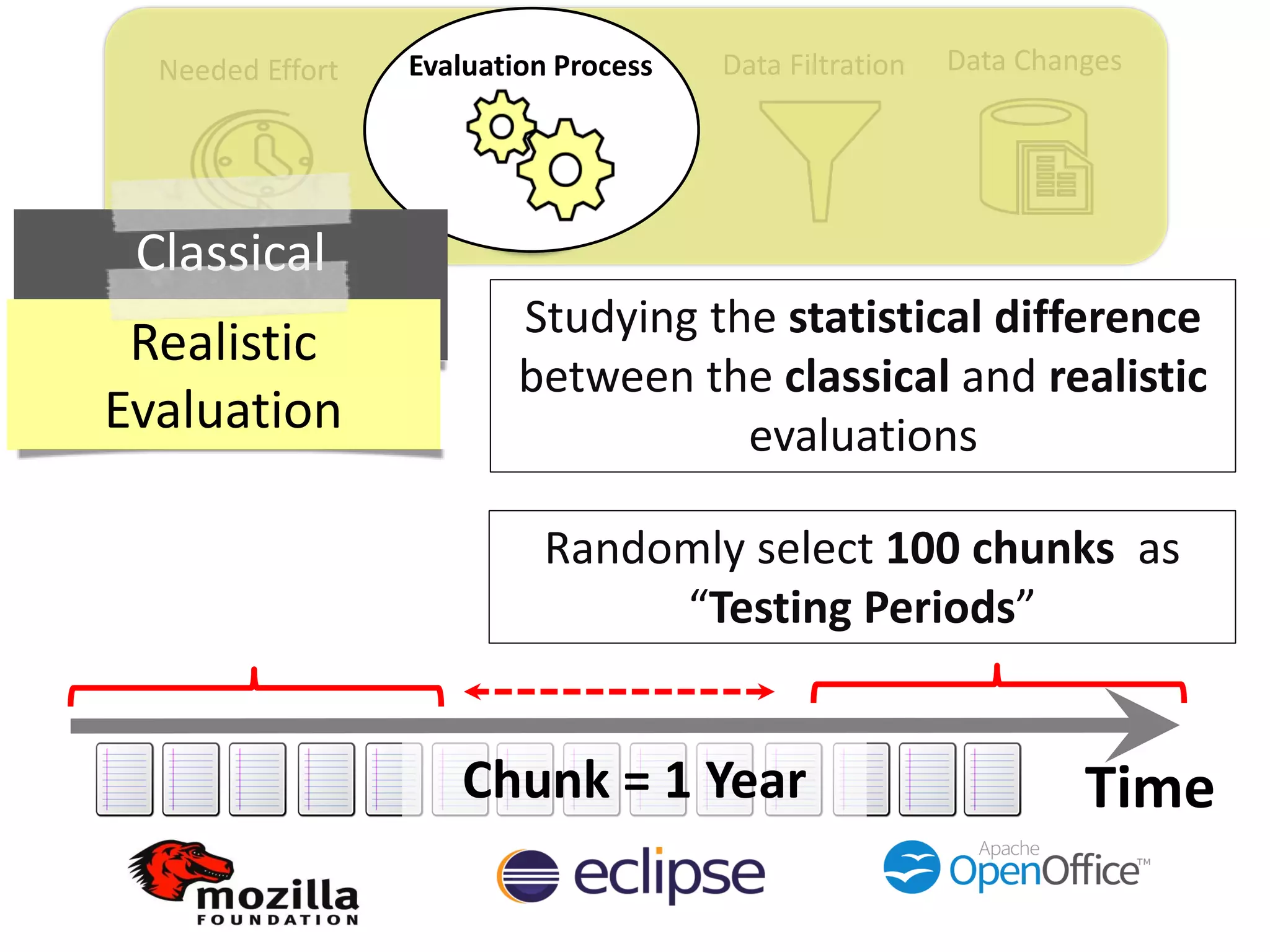
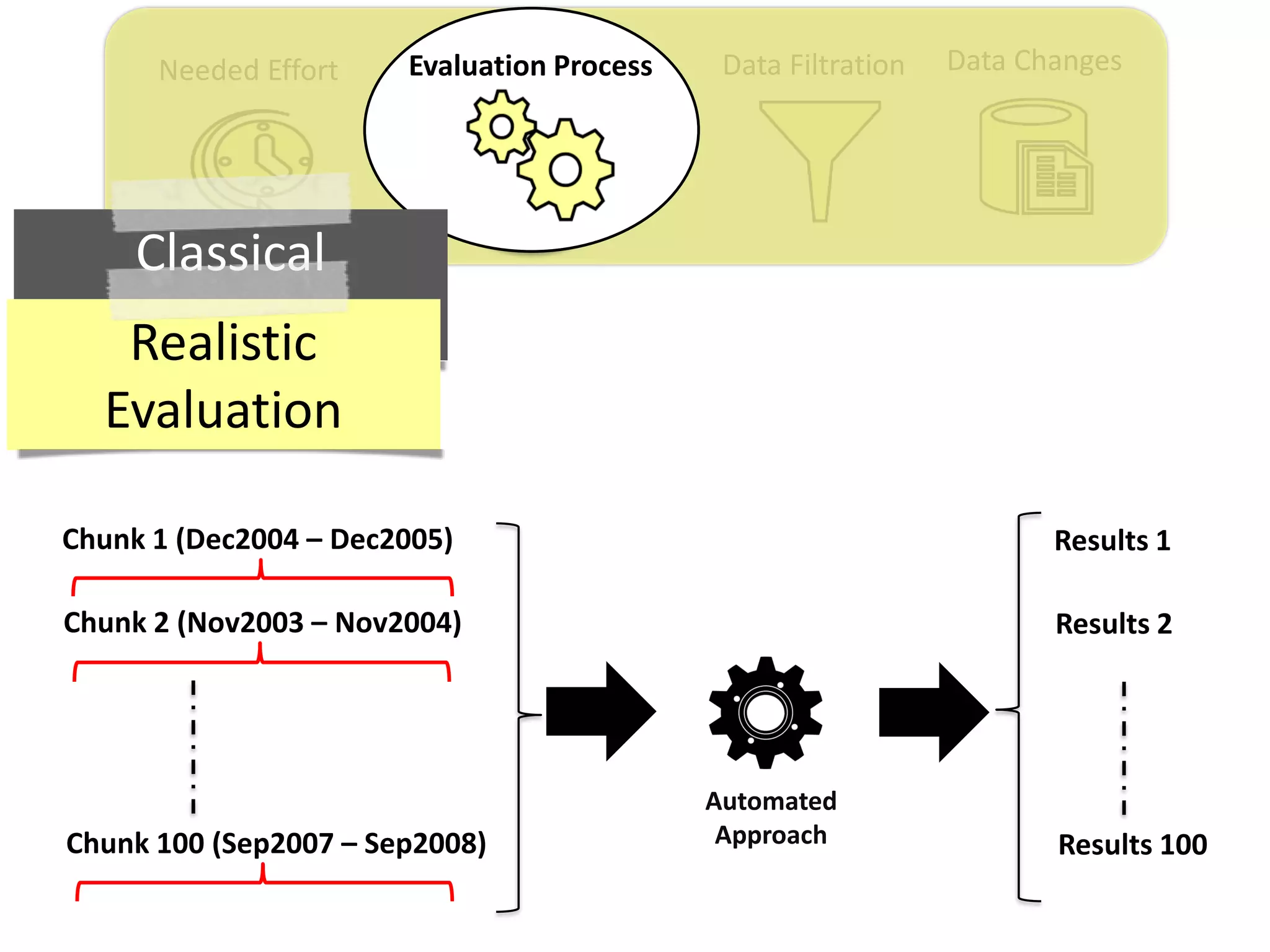
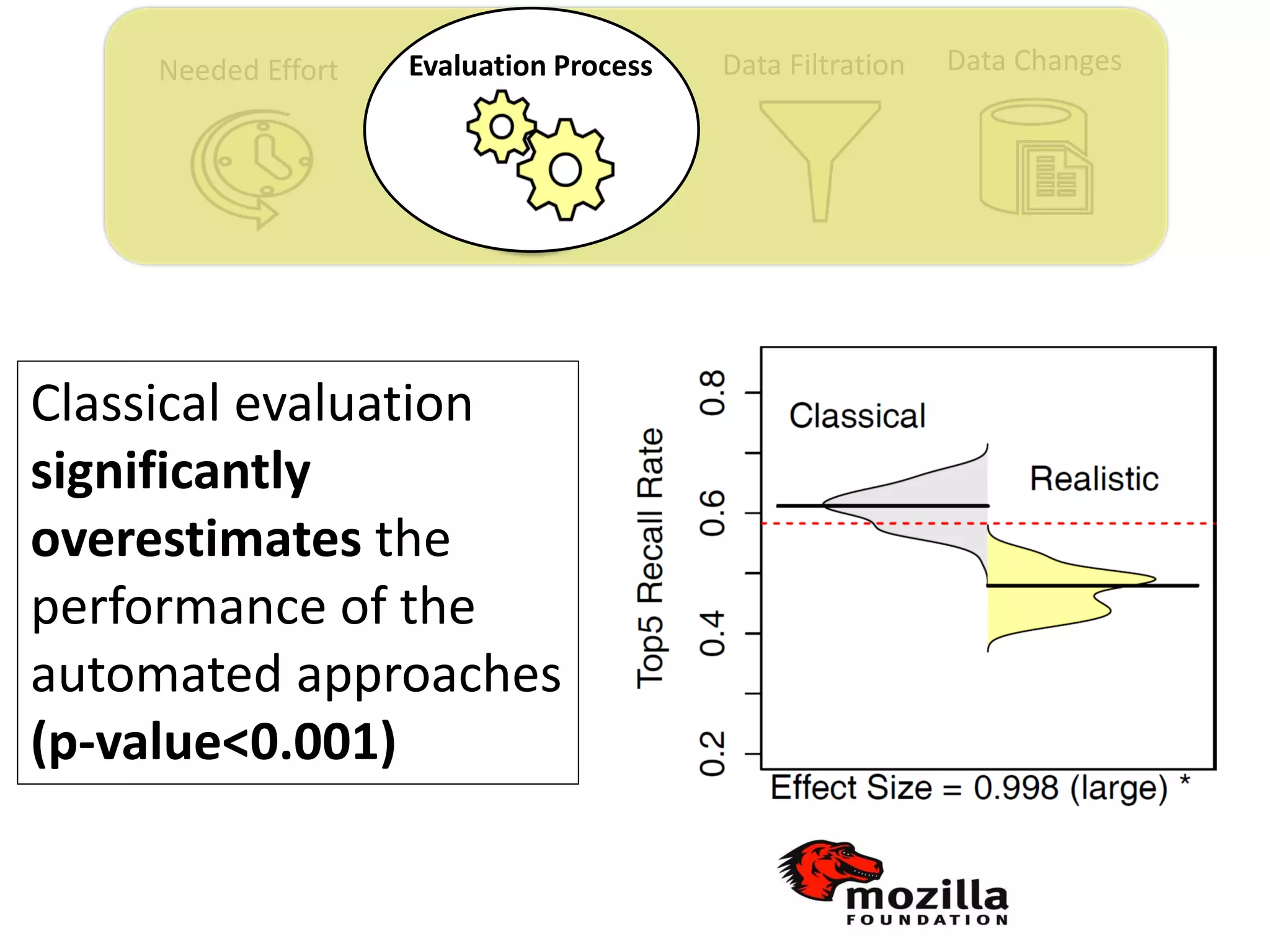
Thesis Contribution #2:
Propose a realistic evaluation for the automated
retrieval of duplicate reports, and analyze prior
findings using such realistic evaluation
[Published in TSE 2017]](https://image.slidesharecdn.com/mohamedsamirakhaphddefense-180828152040/75/Revisiting-the-Experimental-Design-Choices-for-Approaches-for-the-Automated-Retrieval-of-Duplicate-Issue-Reports-38-2048.jpg)
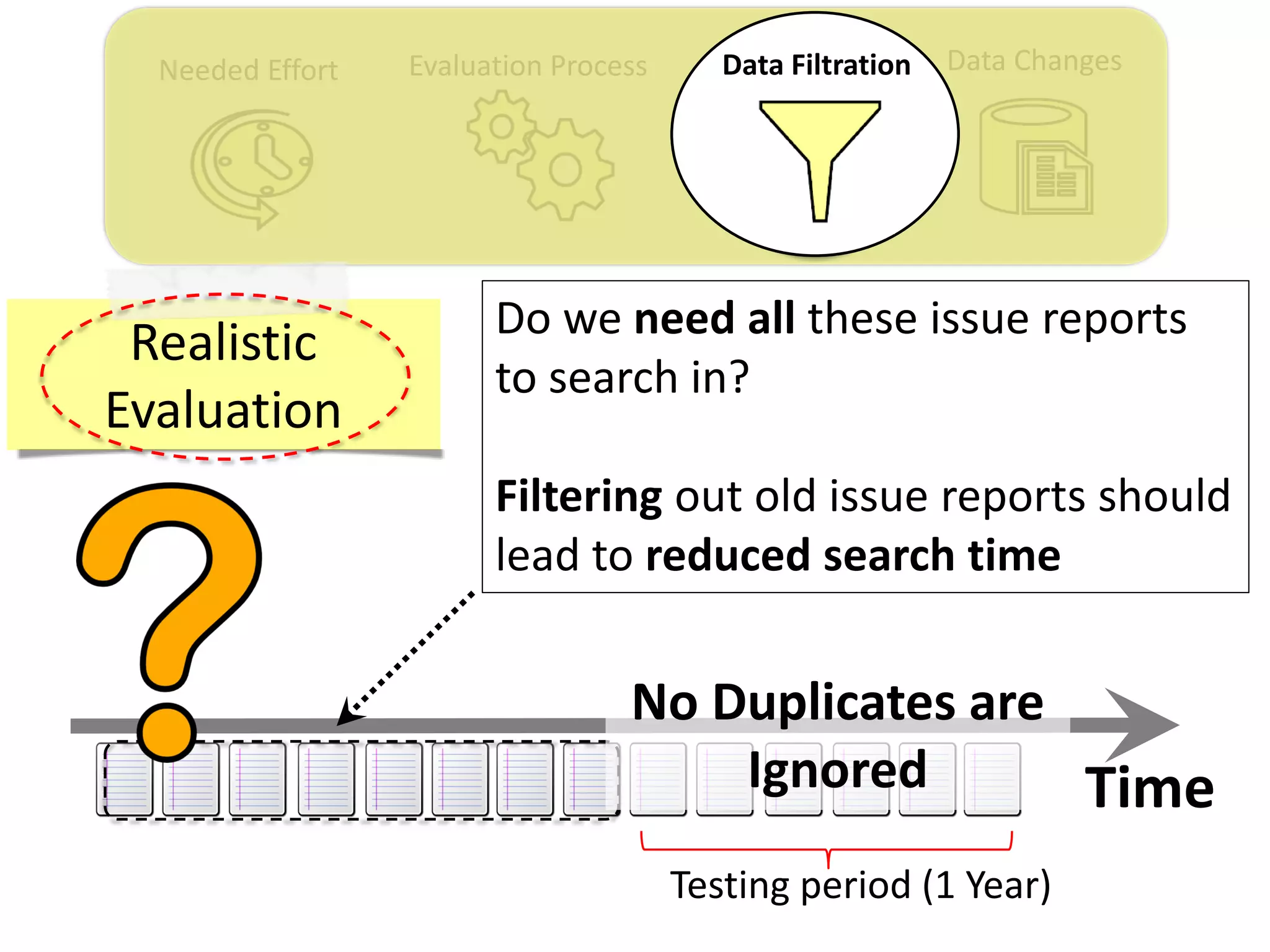
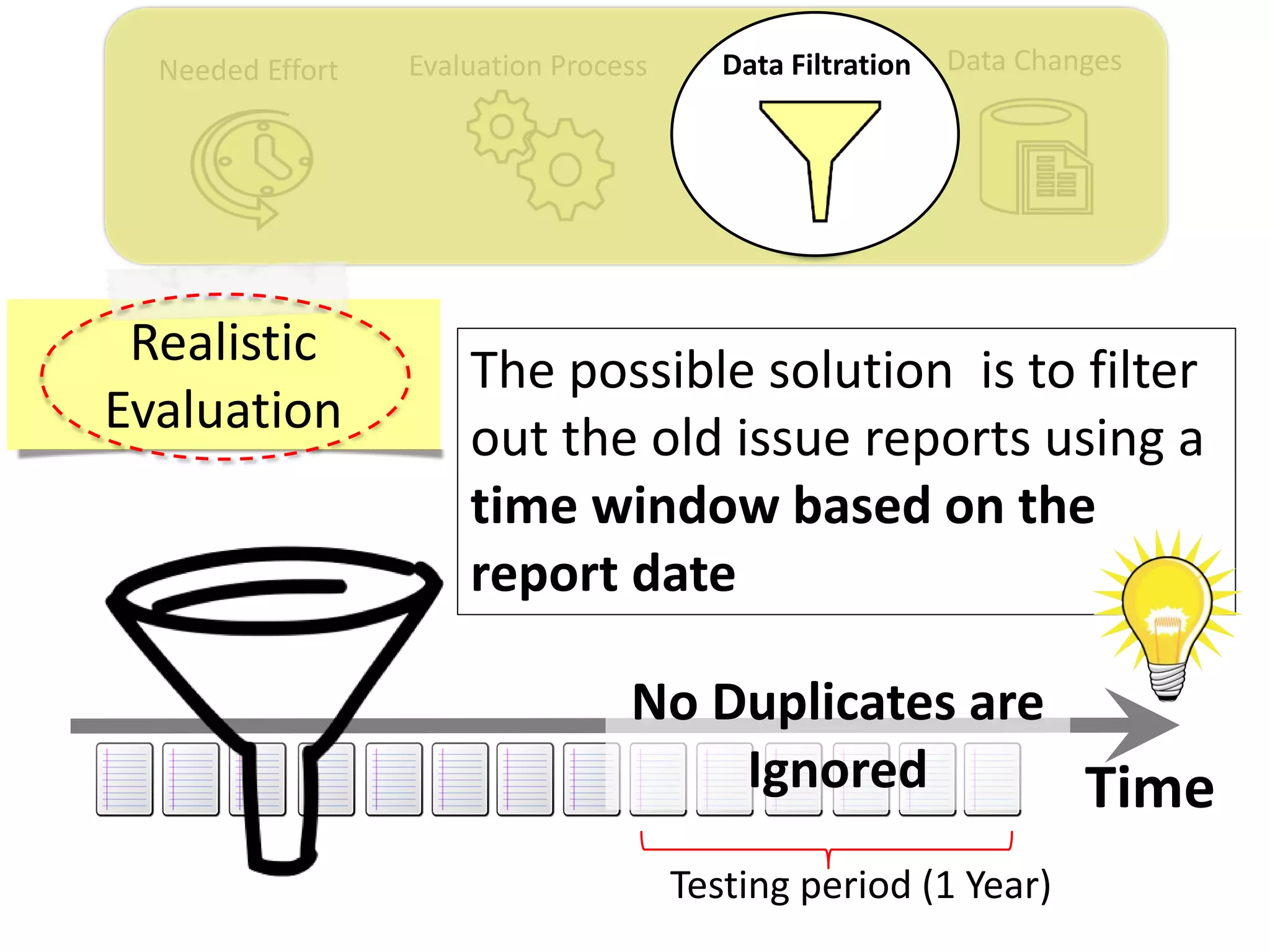
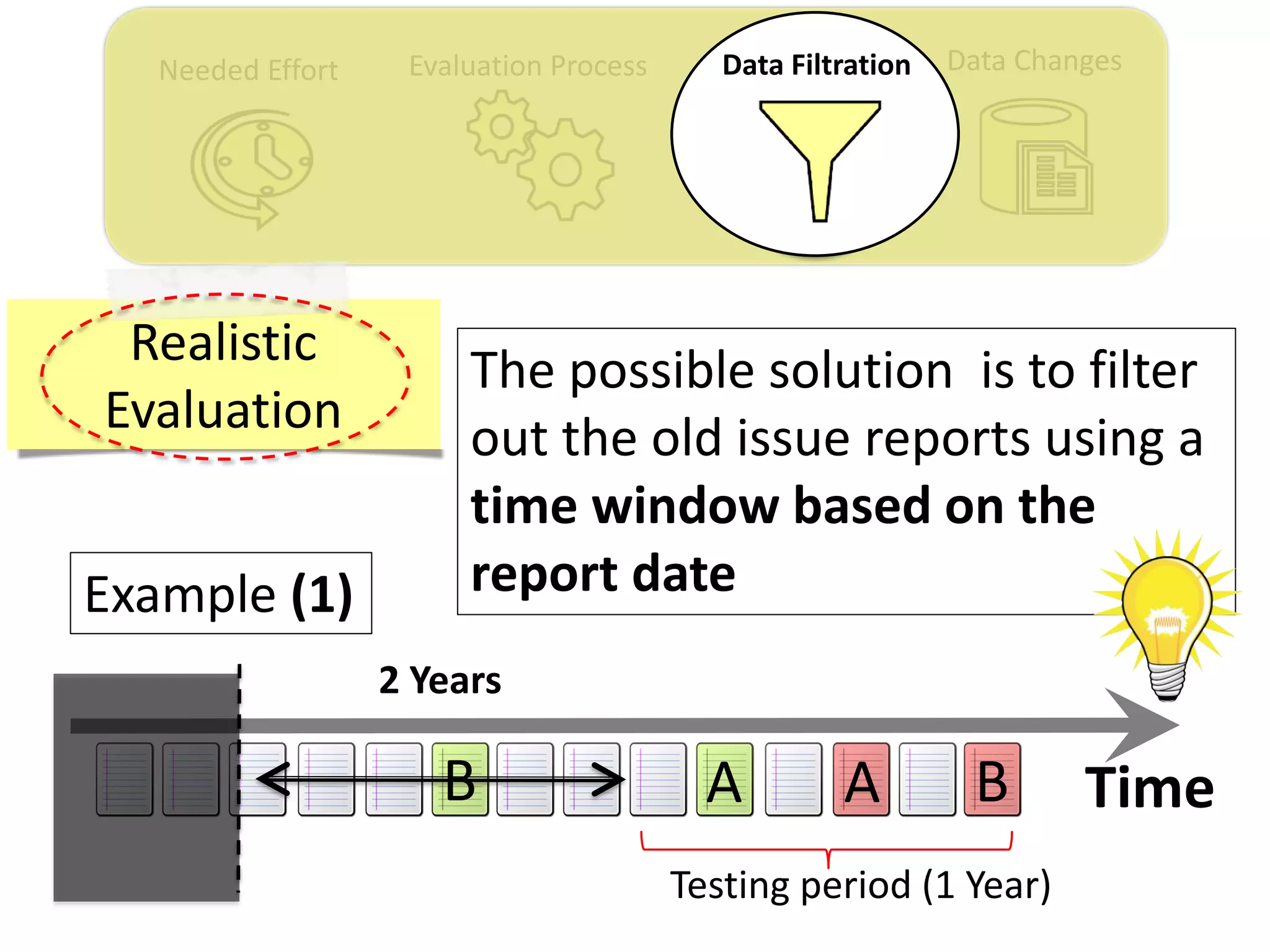
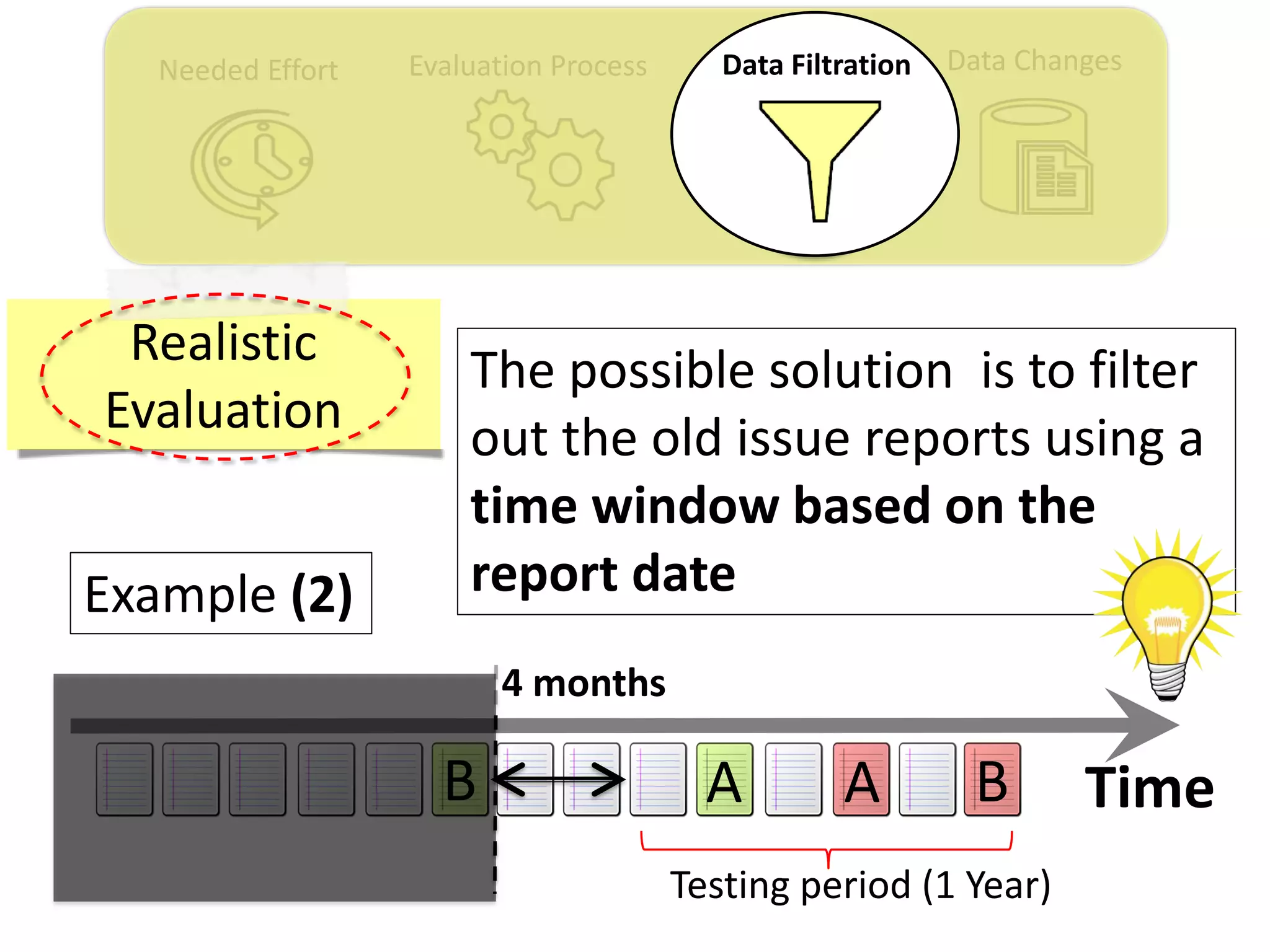
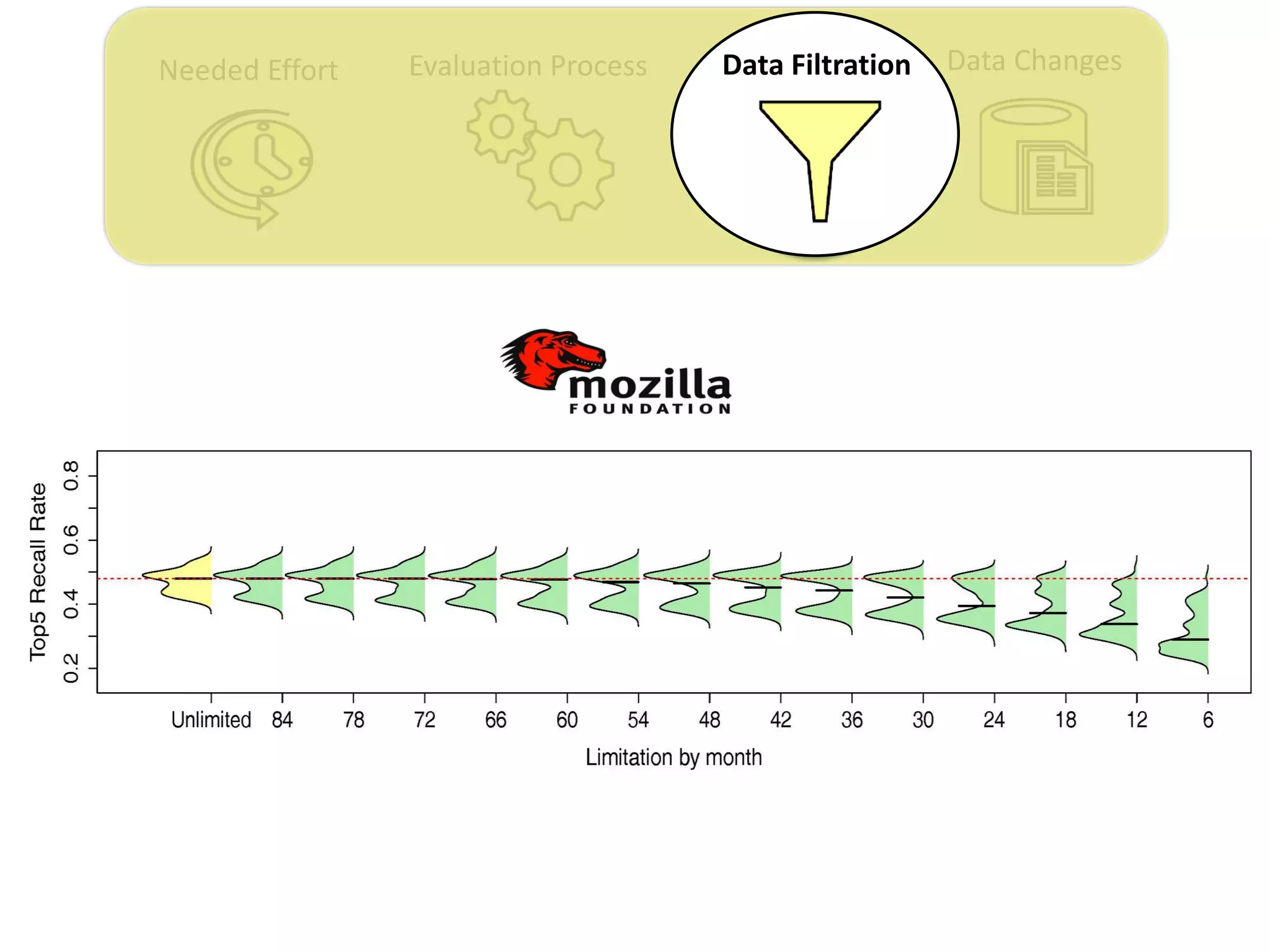
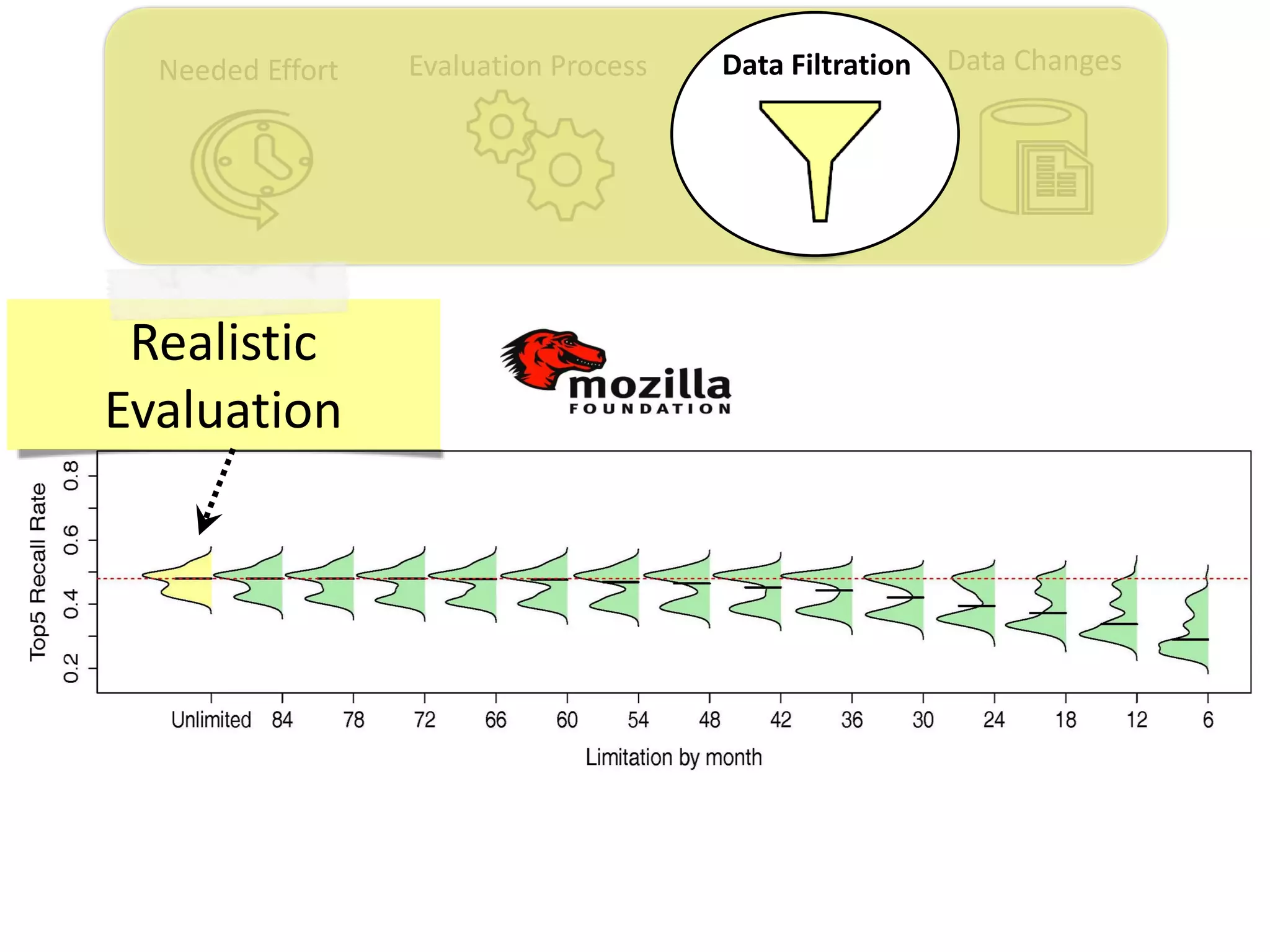
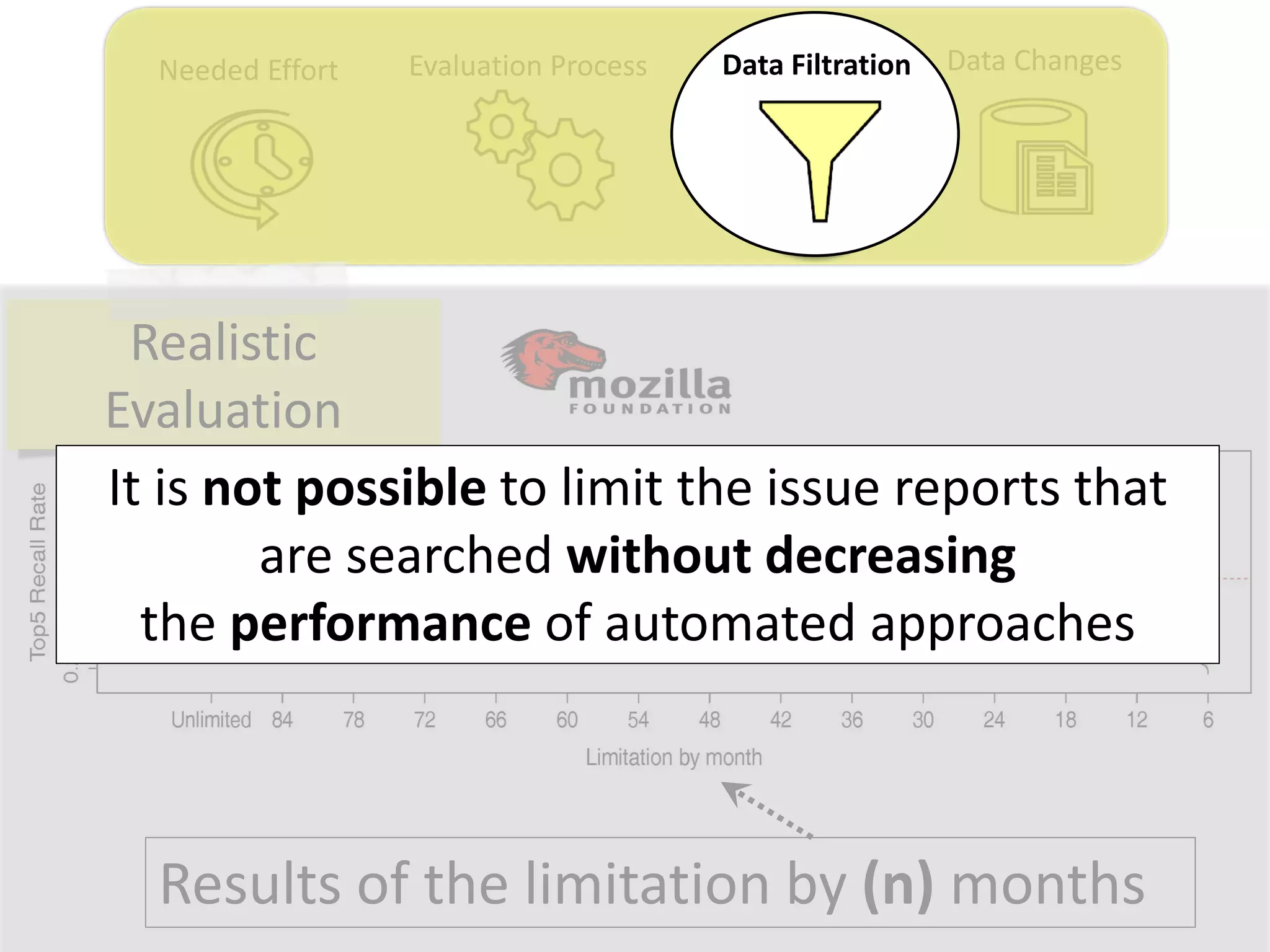
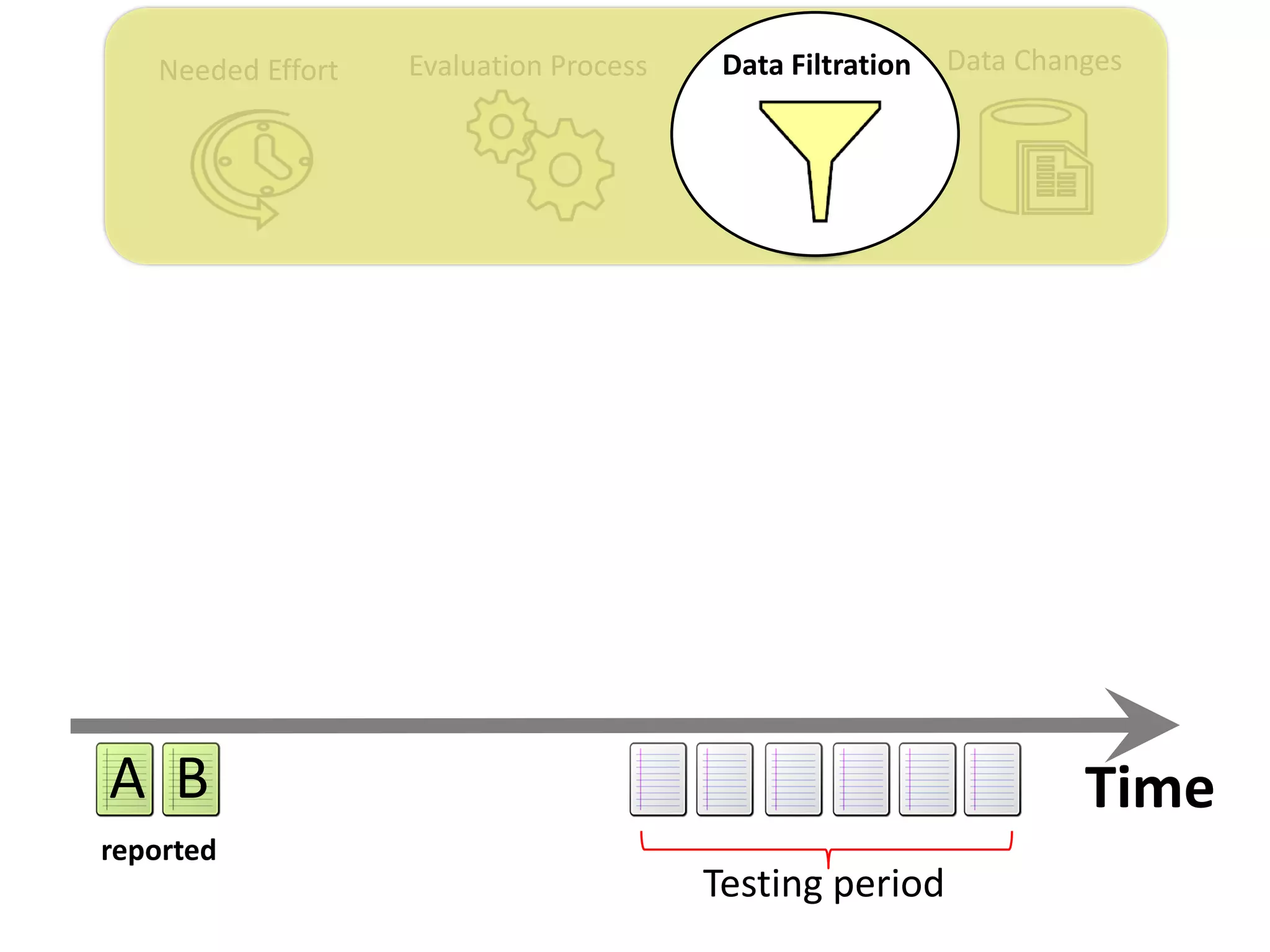
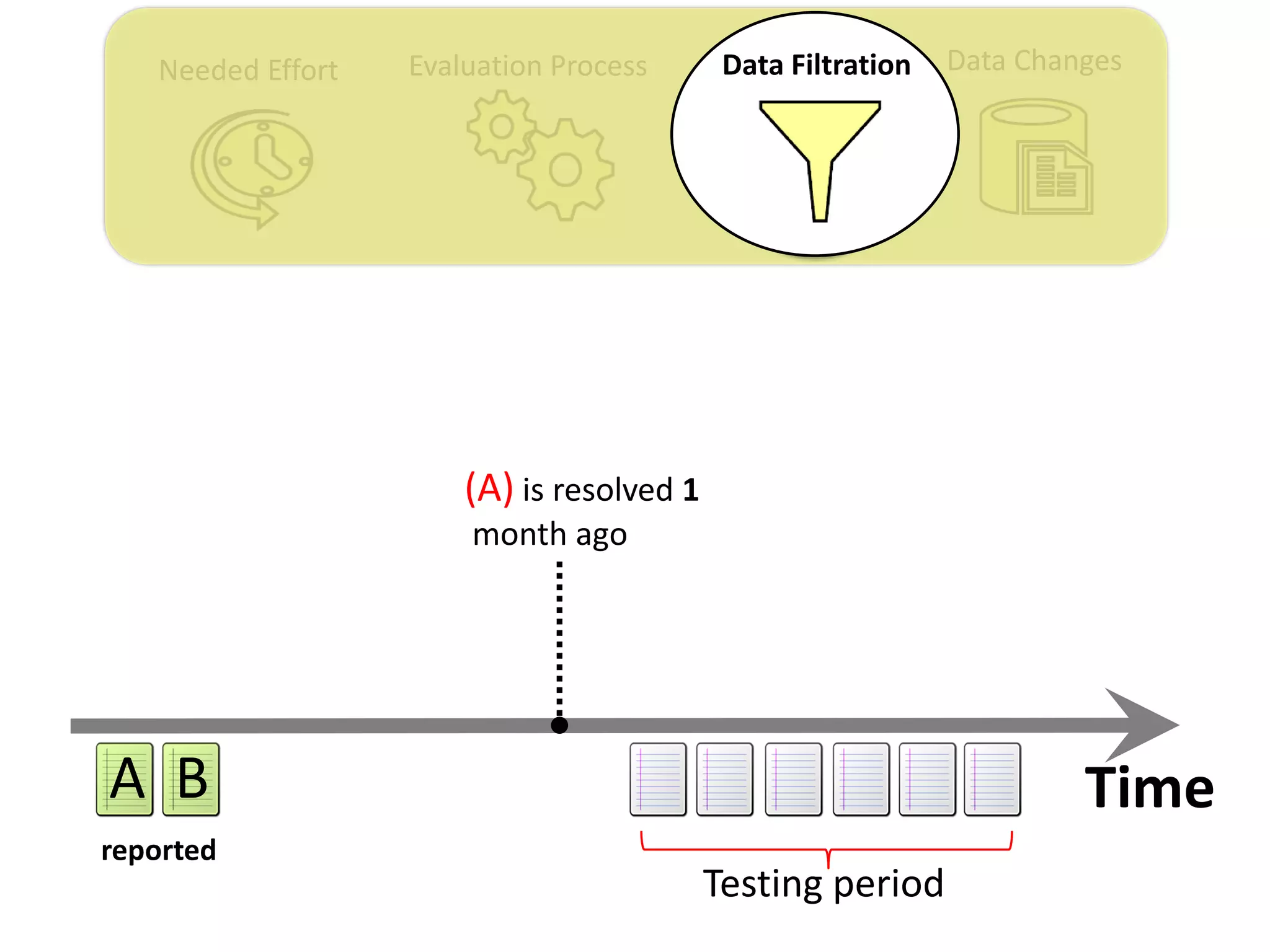
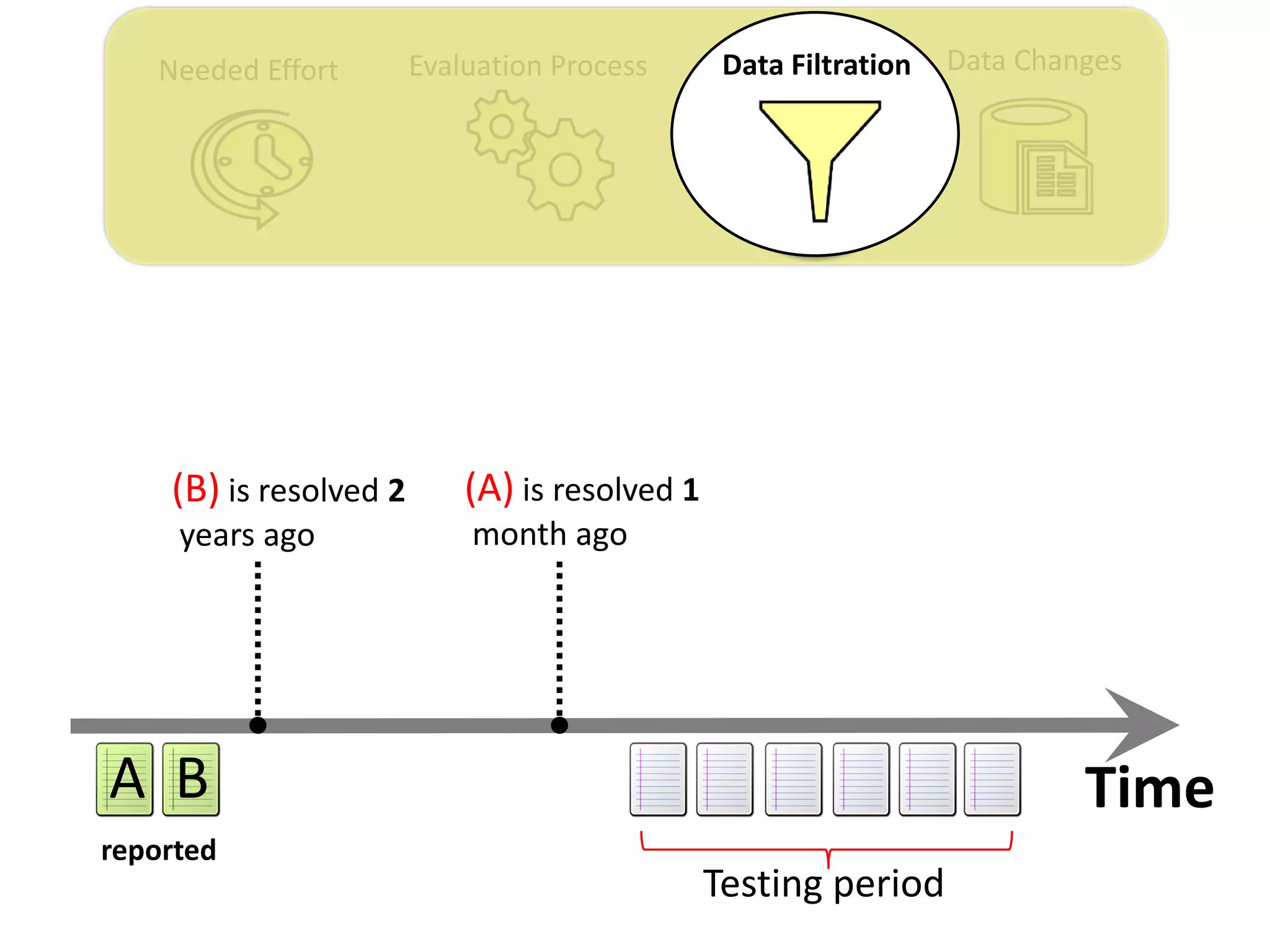
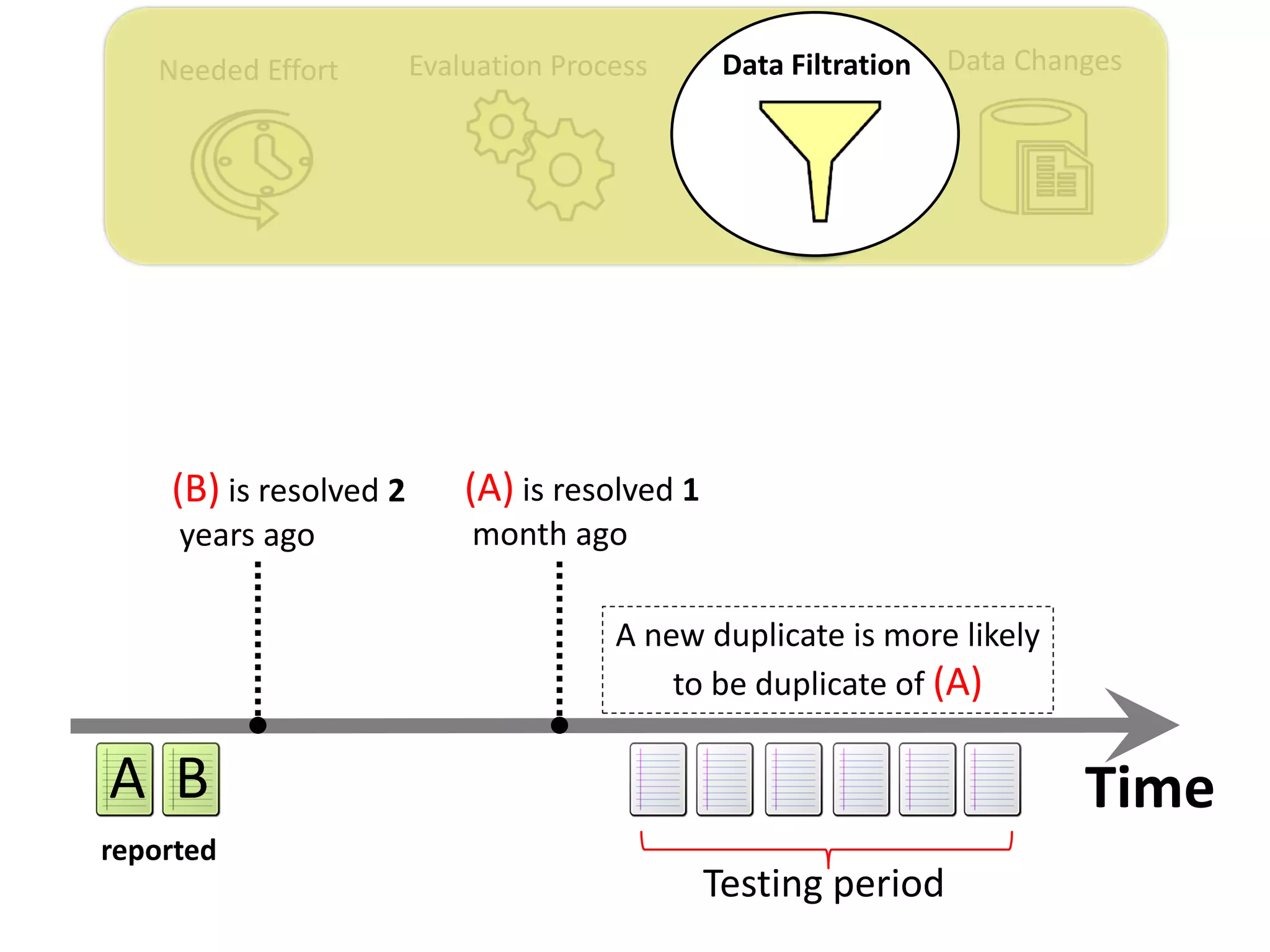
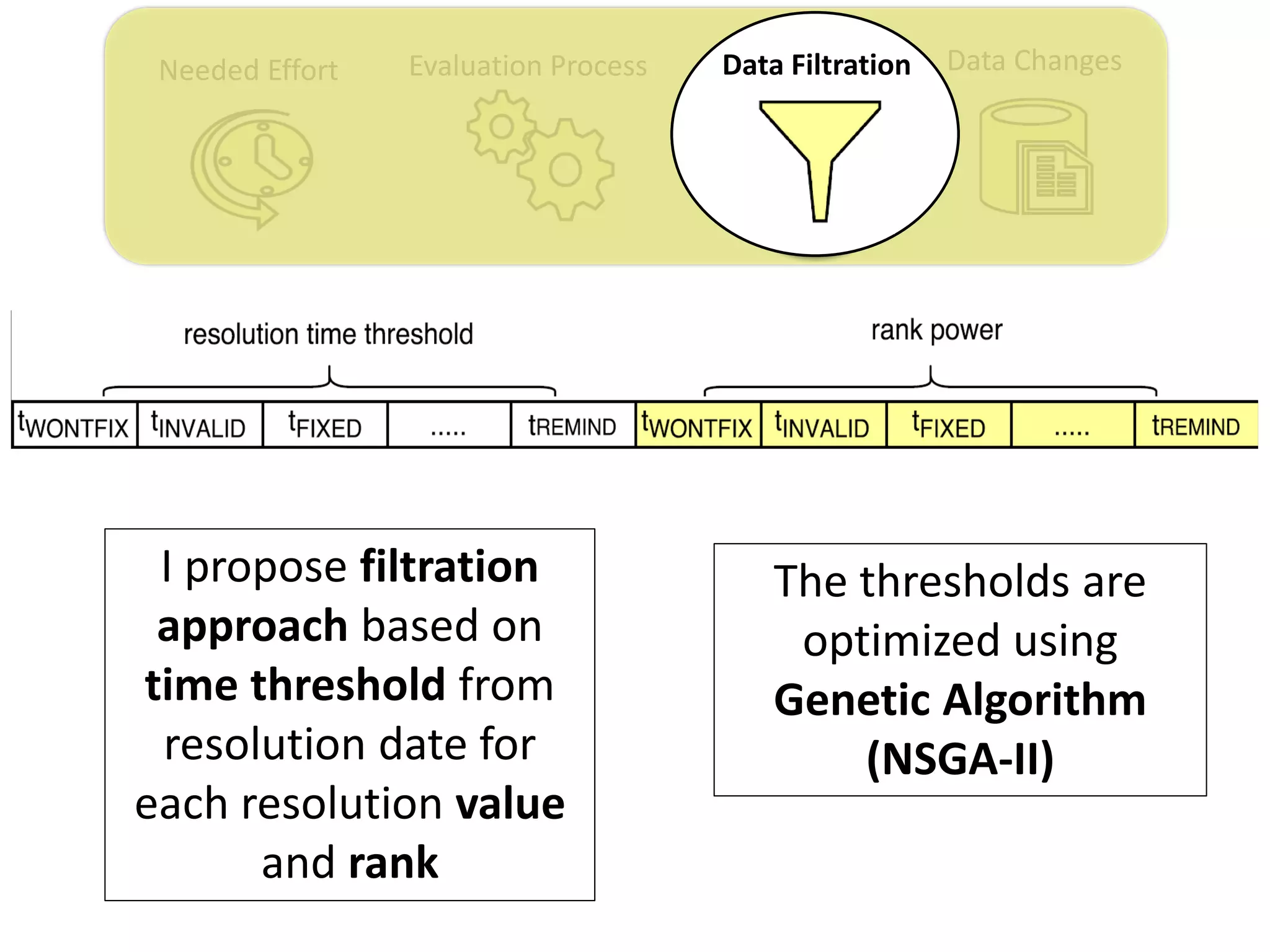
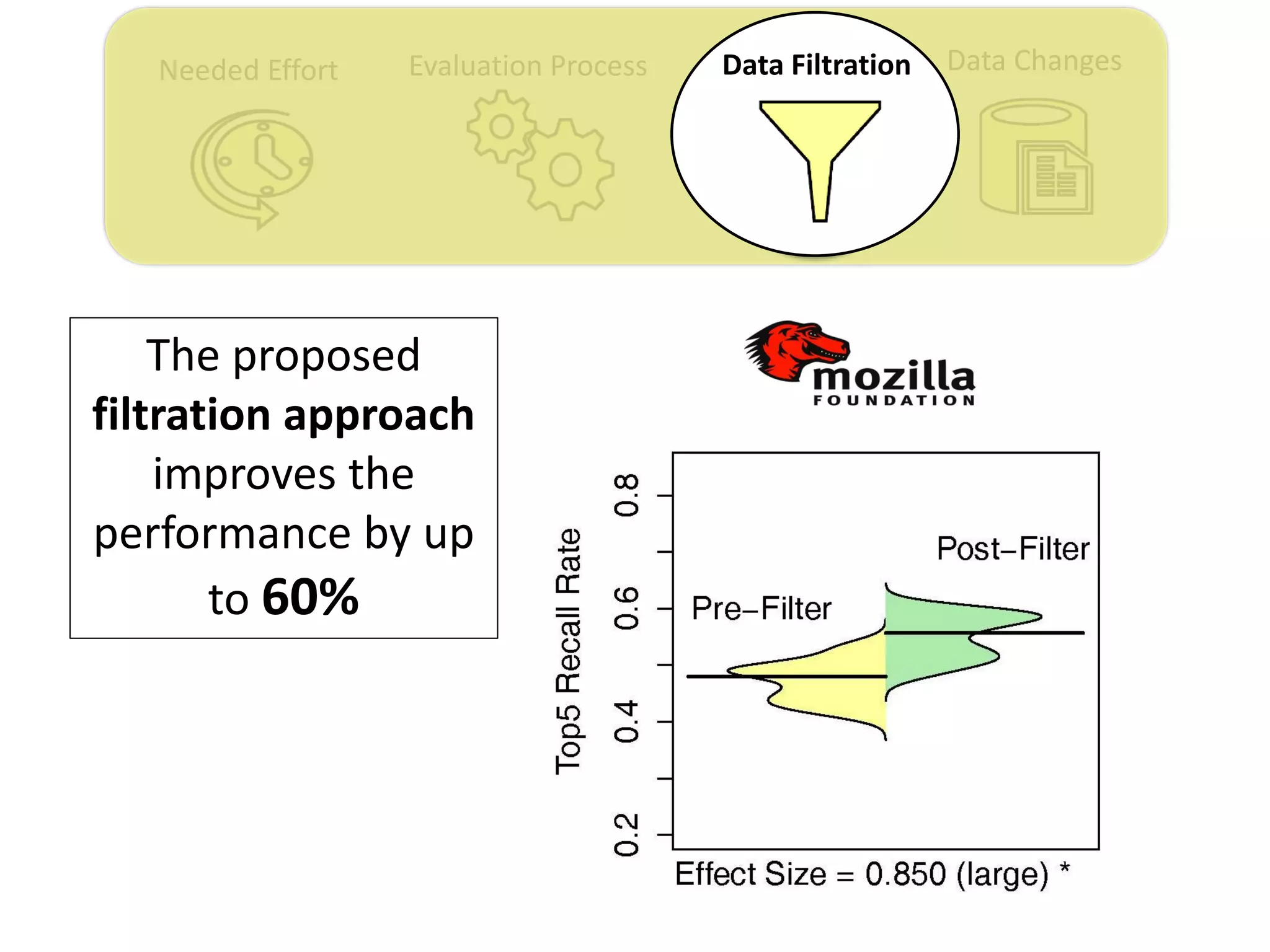
![Data ChangesNeeded Effort Evaluation Process Data Filtration
Thesis Contribution #3:
Propose a genetic algorithm based approach for
filtering out the old issue reports to improve the
performance of duplicate retrieval approaches.
[Published in TSE 2017]](https://image.slidesharecdn.com/mohamedsamirakhaphddefense-180828152040/75/Revisiting-the-Experimental-Design-Choices-for-Approaches-for-the-Automated-Retrieval-of-Duplicate-Issue-Reports-52-2048.jpg)
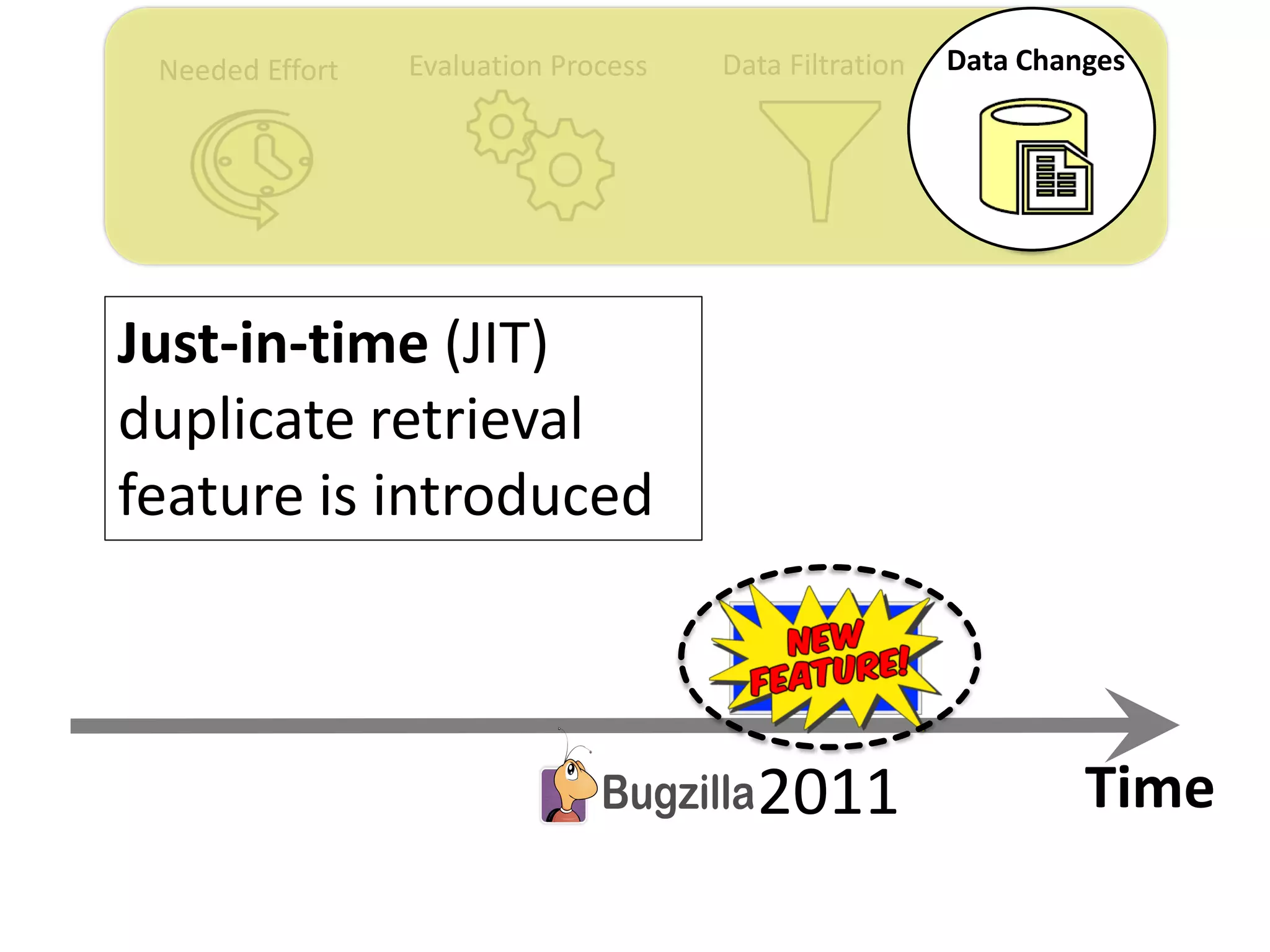
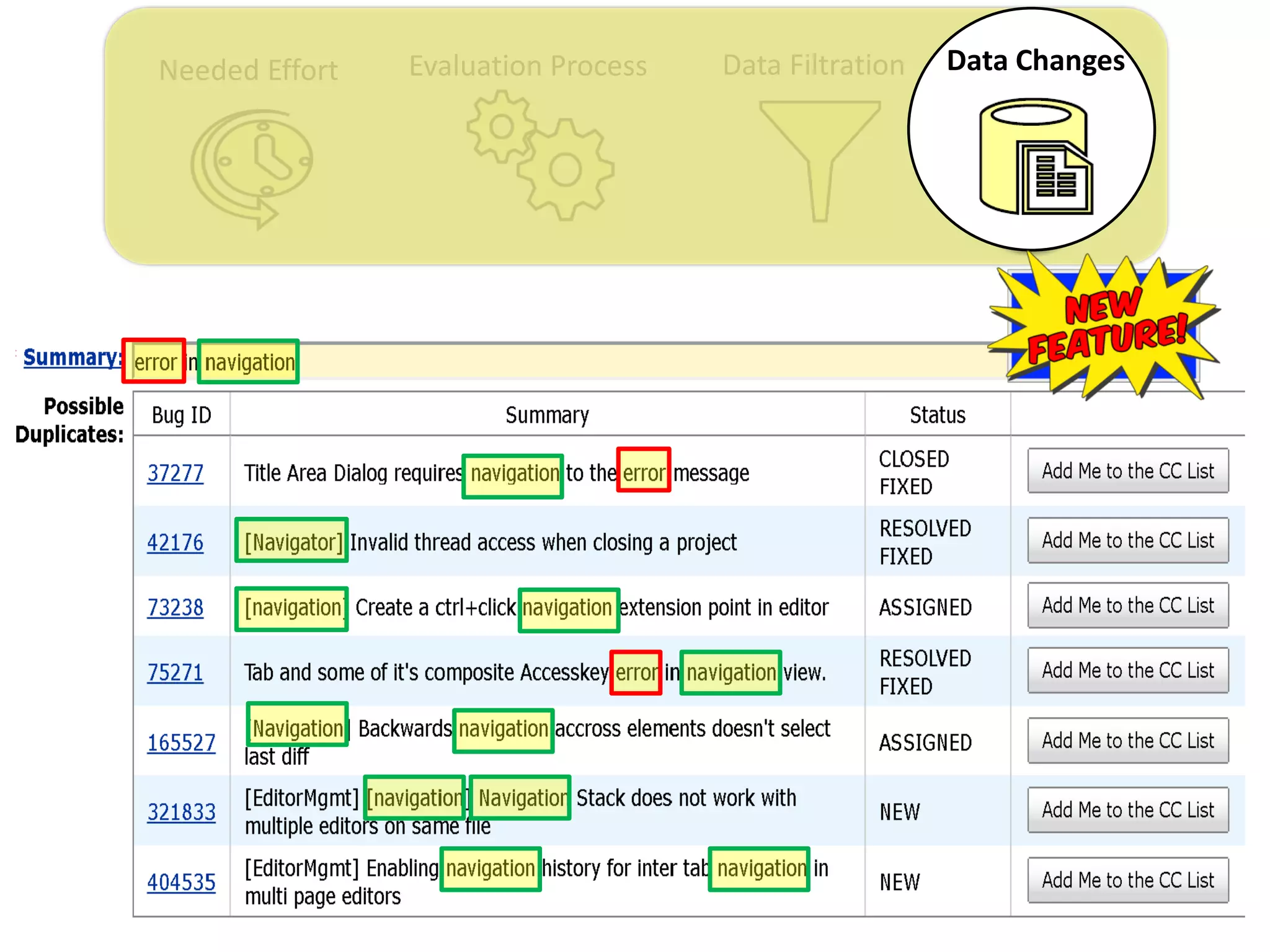
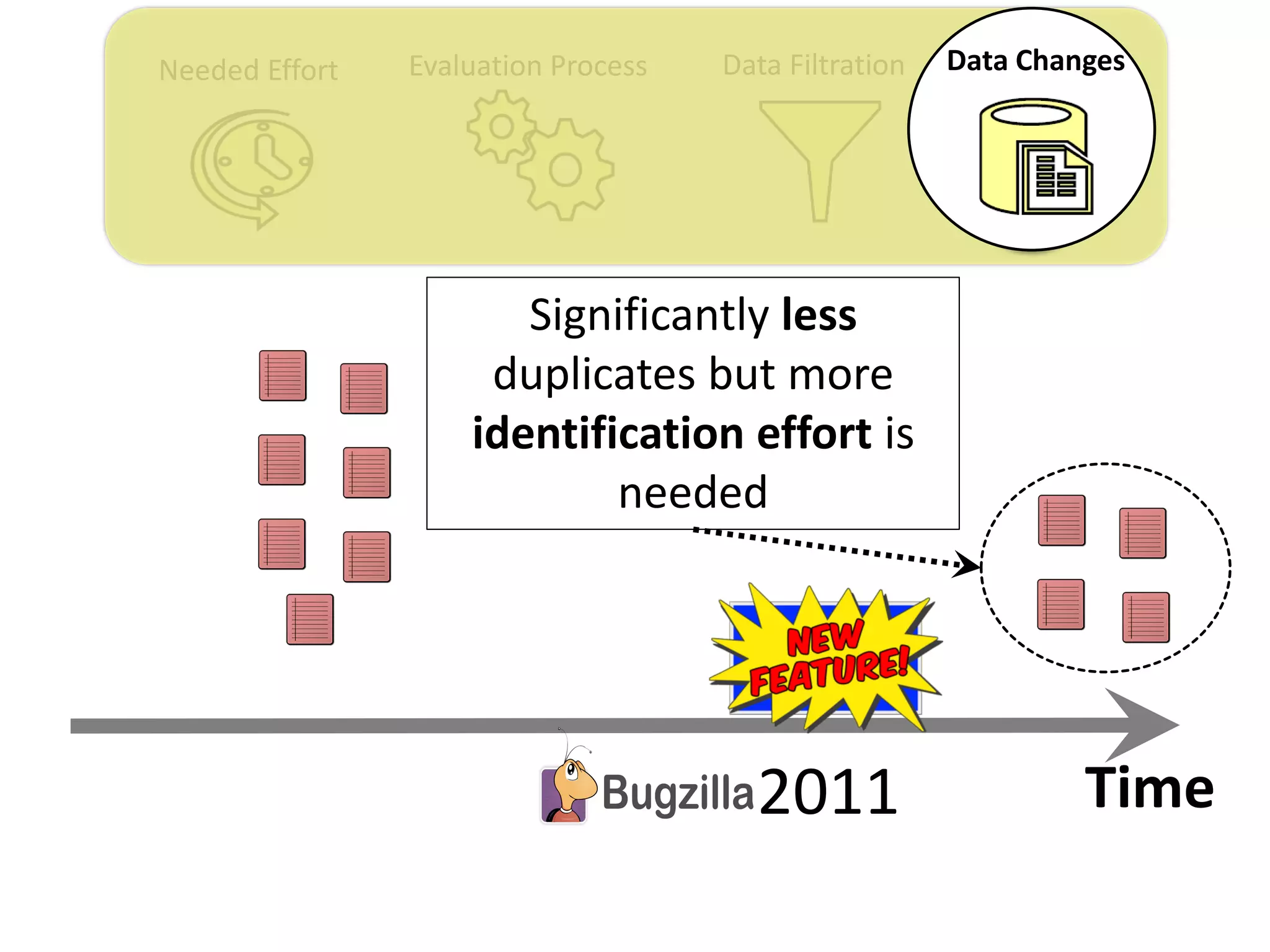
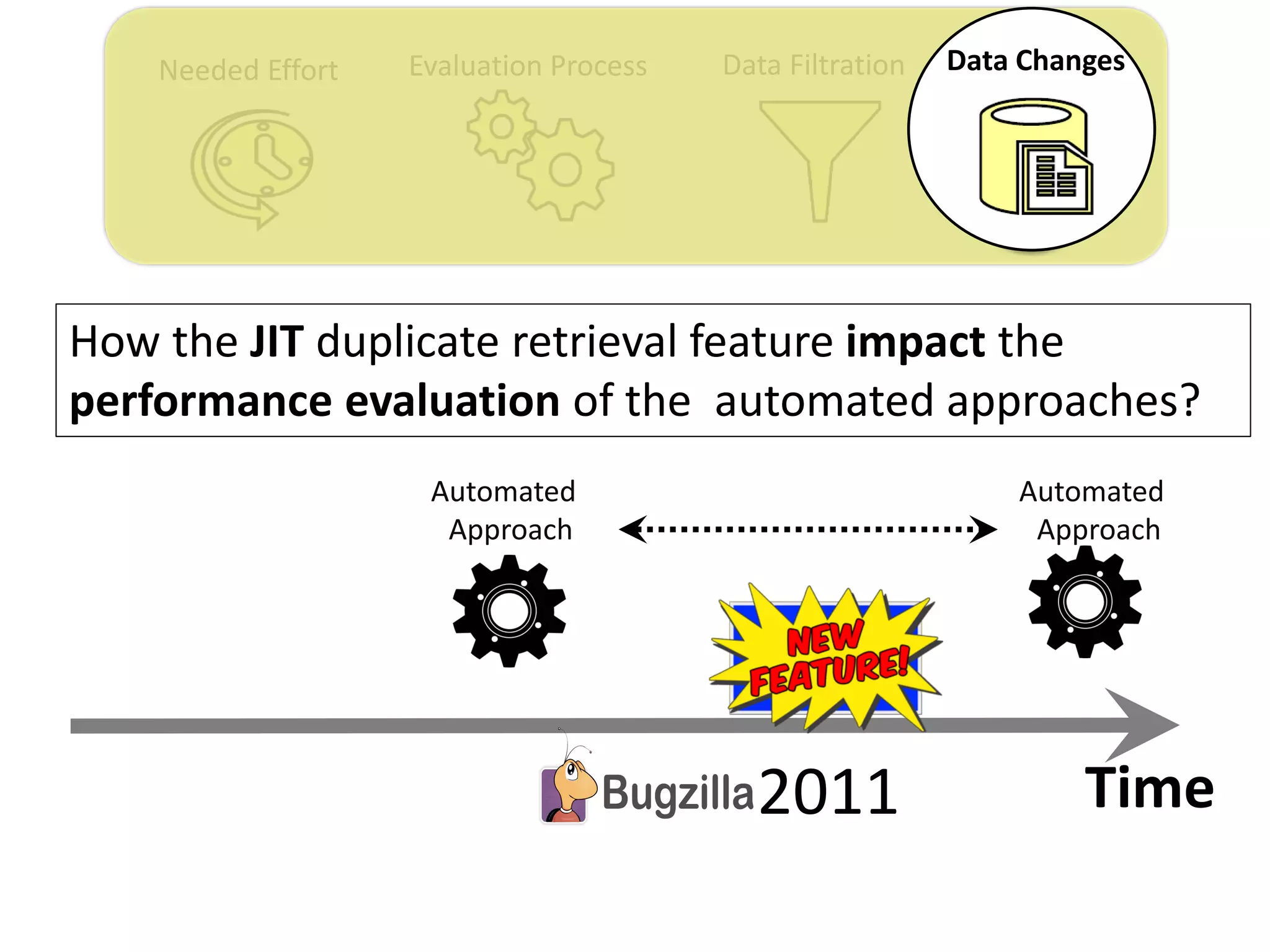
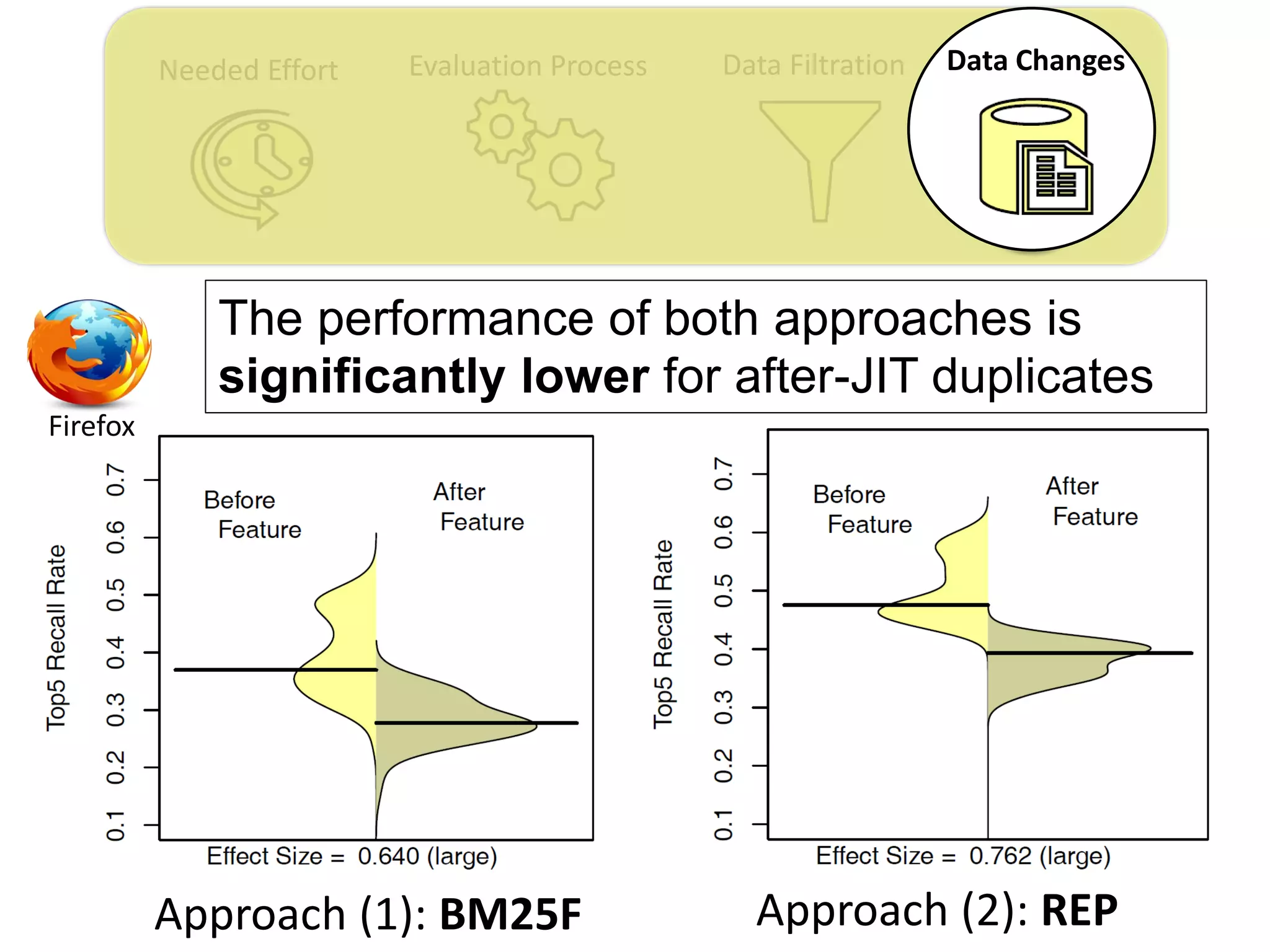
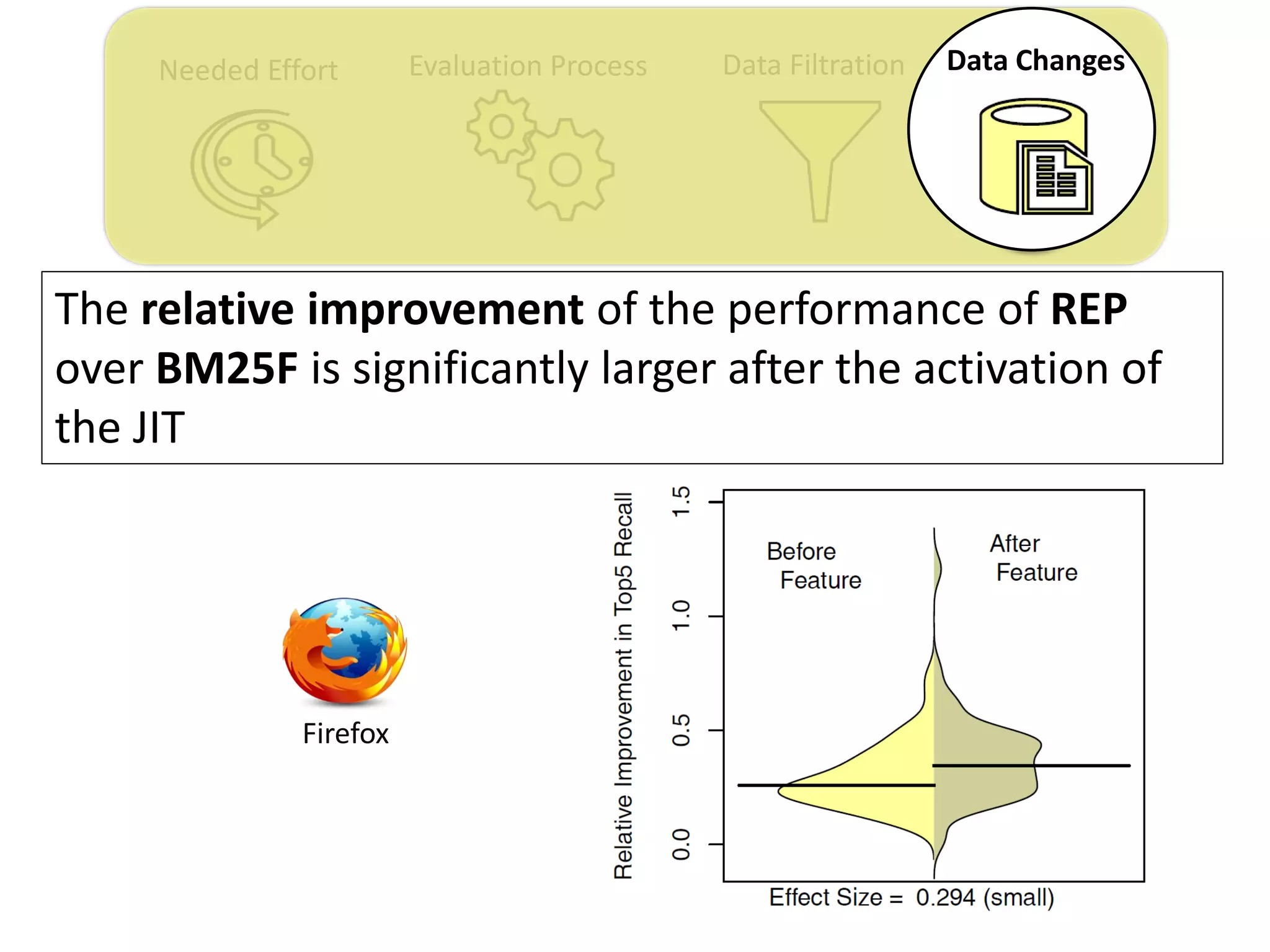
![Needed Effort Evaluation Process Data Filtration Data Changes
Thesis Contribution #4:
Highlight the impact of the “JIT” feature on the
performance evaluation of duplicate retrieval
approaches
[Submitted to EMSE] – under review](https://image.slidesharecdn.com/mohamedsamirakhaphddefense-180828152040/75/Revisiting-the-Experimental-Design-Choices-for-Approaches-for-the-Automated-Retrieval-of-Duplicate-Issue-Reports-59-2048.jpg)
![Evaluation Process Data Filtration Data ChangesNeeded Effort
Thesis Contribution #1:
Show the importance of considering the needed
effort for retrieving duplicate reports in the
performance measurement of automated duplicate
retrieval approaches
[Published in EMSE 2015]](https://image.slidesharecdn.com/mohamedsamirakhaphddefense-180828152040/75/Revisiting-the-Experimental-Design-Choices-for-Approaches-for-the-Automated-Retrieval-of-Duplicate-Issue-Reports-63-2048.jpg)
![Data ChangesData FiltrationNeeded Effort Evaluation Process
Thesis Contribution #2:
Propose a realistic evaluation for the automated
retrieval of duplicate reports, and analyze prior
findings using such realistic evaluation
[Published in TSE 2017]](https://image.slidesharecdn.com/mohamedsamirakhaphddefense-180828152040/75/Revisiting-the-Experimental-Design-Choices-for-Approaches-for-the-Automated-Retrieval-of-Duplicate-Issue-Reports-64-2048.jpg)
![Data ChangesNeeded Effort Evaluation Process Data Filtration
Thesis Contribution #3:
Propose a genetic algorithm based approach for
filtering out the old issue reports to improve the
performance of duplicate retrieval approaches
[Published in TSE 2017]](https://image.slidesharecdn.com/mohamedsamirakhaphddefense-180828152040/75/Revisiting-the-Experimental-Design-Choices-for-Approaches-for-the-Automated-Retrieval-of-Duplicate-Issue-Reports-65-2048.jpg)
![Needed Effort Evaluation Process Data Filtration Data Changes
Thesis Contribution #4:
Highlight the impact of the “JIT” feature on the
performance evaluation of duplicate retrieval
approaches
[EMSE 2017] – under review](https://image.slidesharecdn.com/mohamedsamirakhaphddefense-180828152040/75/Revisiting-the-Experimental-Design-Choices-for-Approaches-for-the-Automated-Retrieval-of-Duplicate-Issue-Reports-66-2048.jpg)




































































