Download to read offline



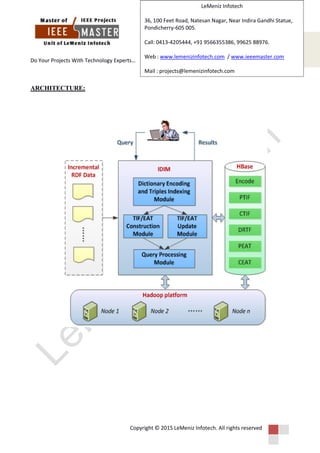


The document discusses an incremental and distributed inference method for large-scale RDF datasets using the MapReduce paradigm, aimed at enhancing reasoning and searching efficiency. It highlights the limitations of centralized reasoning on large ontologies and proposes a new method called TIF/EAT, which reduces storage and simplifies the reasoning process. The proposed system leverages MapReduce to efficiently manage data, minimizing update times and improving query responsiveness for users.







































































































