Download to read offline











![Stitch Fix Outages
Oct / Nov 2016
• (11/08/2016) Spectre unavailable for ~3 minutes [Shared Database]
• (11/05/2016) Spectre unavailable for ~5 minutes [Shared Database]
• (10/25/2016) All systems unavailable for ~5 minutes [Shared Database]
• (10/24/2016) All systems unavailable for ~5 minutes [Shared Database]
• (10/21/2016) All systems unavailable for ~3 ½ hours [DDOS attack]
• (10/18/2016) All systems unavailable for ~3 minutes [Shared Database]
• (10/17/2016) All systems unavailable for ~20 minutes [Shared Database]
• (10/13/2016) Minx escalation broken for ~2 hours [Zendesk outage]
• (10/11/2016) Label printing unavailable for ~10 minutes [FedEx outage]
• (10/10/2016) Label printing unavailable for ~15 minutes [FedEx outage]
• (10/10/2016) All systems unavailable for ~10 minutes [Shared Database]](https://image.slidesharecdn.com/sreconnewyork2019-anatomyofthreeincidents-190327161743/75/Learning-from-Learnings-Anatomy-of-Three-Incidents-12-2048.jpg)




















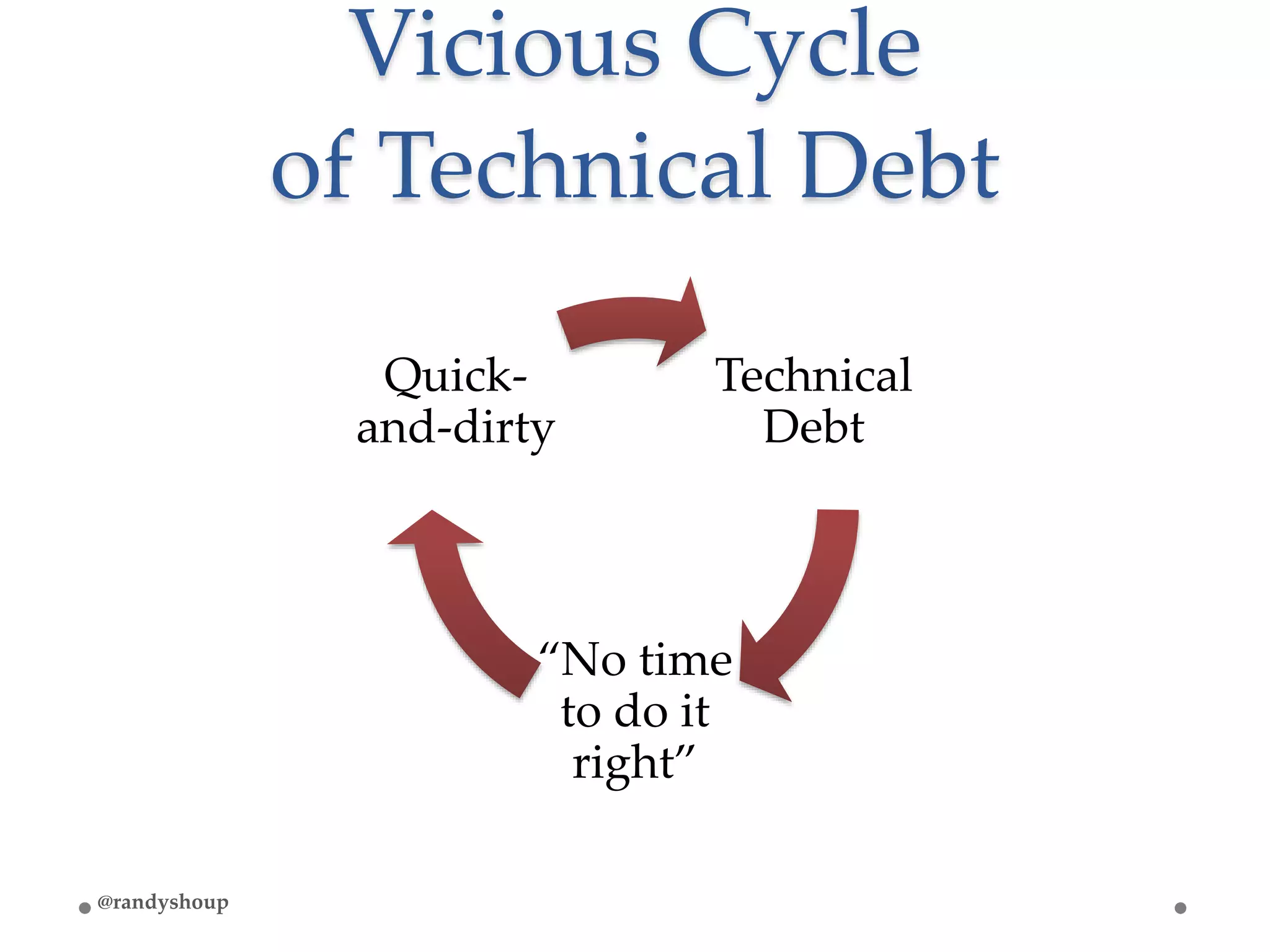
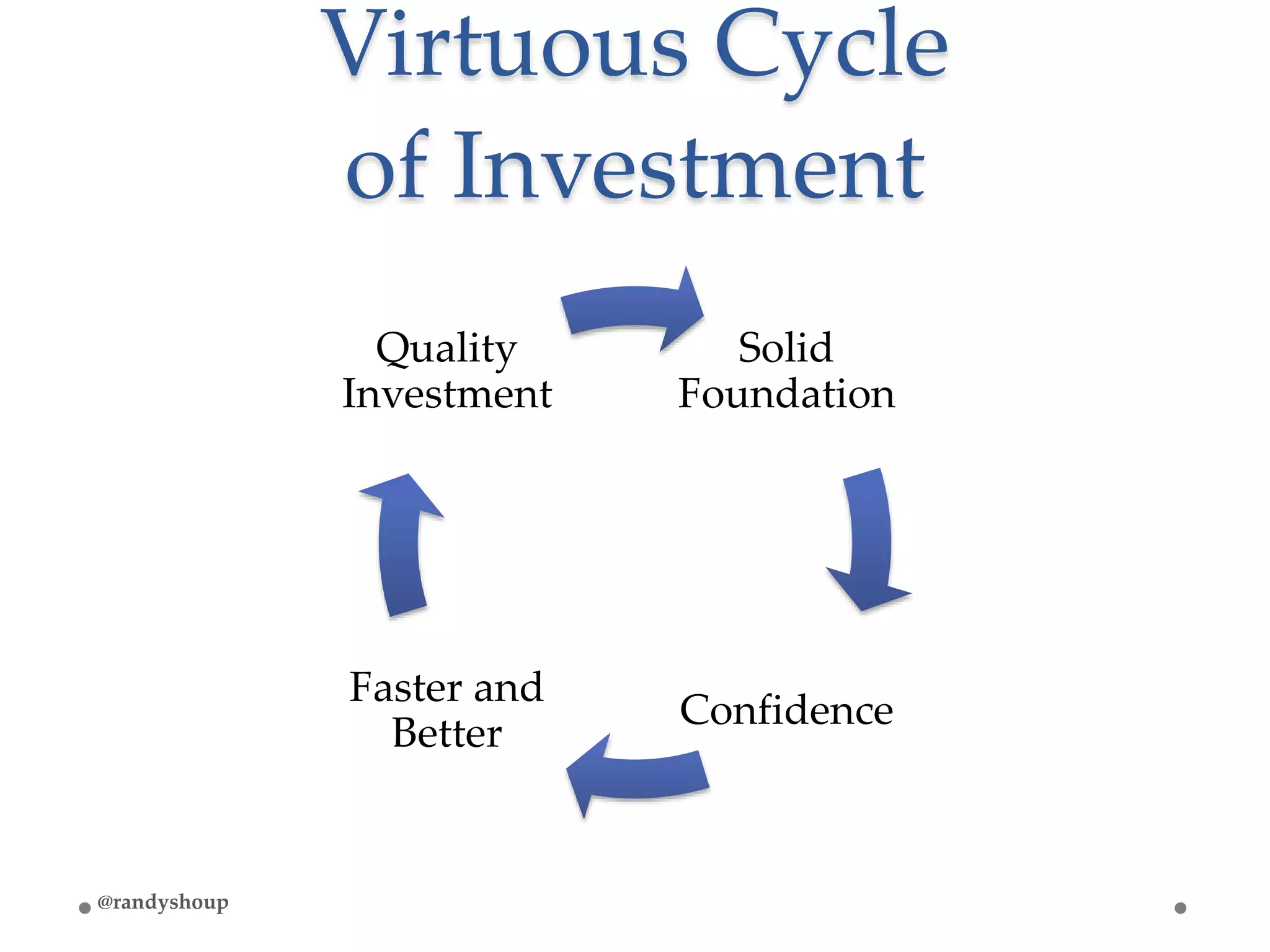








The document details a retrospective analysis of incidents affecting application reliability, focusing on a structured approach to problem identification, understanding, prioritization, and implementation across three main outages. Key lessons include the importance of leadership, collaboration, and investment in quality and reliability to address technical debt and improve system stability. Emphasizing a blameless culture, the document highlights the benefits of open discussions and cross-functional teamwork in driving long-term change.












































































