





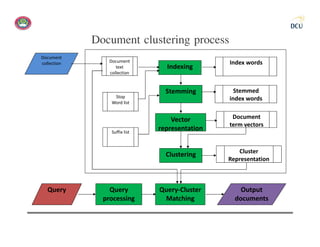

![Document clustering process
2. Document pre-processing
- Indexing the documents
- Word identification (Amharic word separators considered)
- Smoothing( characters of the same voice were mapped to a single character)
- ጸሃይ፣ ጸኅይ፣ጸሀይ፣ ፀሃይ፣ ፀኃይ፣ ፀሀይ… ፀሐይ
- Stop word removal
- Words like [ለ፣ ወደ]=to, [ከ]=from, [የ] are removed [non-content bearing
words]
- Stop words in news domain such as [ገልጿል] disclosed, [አመልክቷል] ect.
- Stop words are validated against their frequency in the document
collection [a threshold of 100 is used]](https://image.slidesharecdn.com/amharicdocumentclustering-111208072442-phpapp02/85/Amharic-document-clustering-9-320.jpg)
![Document clustering process
3. Stemming of indexed terms
- Amharic language is morphologically complex
- Nouns have inflection [prefix, and suffix]
- አስተማሩ
- አስተማረ
- አስተማረች አስተማረ
- አስተማርኩ
- Verbs have inflection[prefix, suffix and infix]
- ሰበረ
- ሰበረች
- ሰበርክ ሰበር ስብር
- ሰበርሽ
- አሰበረ
- stemming brings the word into its common form](https://image.slidesharecdn.com/amharicdocumentclustering-111208072442-phpapp02/85/Amharic-document-clustering-10-320.jpg)



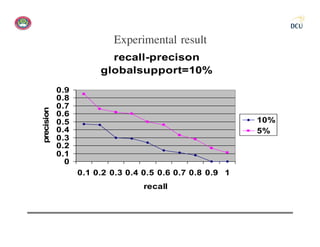
![Experimental result
• Tuning the global support to get hierarchical documents
– More than 10% global support gives flat hierarchy
– Less than 1% global support gives a single vertical hierarchy
– 5% global support shows a better performance
Global Support Width Depth Remark
>=20% < =9 0 Flat hierarchy
10% 61 2 1 level hierarchical(only for 2 classes
5% 92 10 10 level hierarchy for two classes 5 level hierarchy for five classes
<=1% >=120 25 25 level hierarchy[took too much time to cluster]](https://image.slidesharecdn.com/amharicdocumentclustering-111208072442-phpapp02/85/Amharic-document-clustering-14-320.jpg)


![Future directions
• Developing standard corpus collection
• Using ontologies as a concept map
• Standardization for Amharic language resources such as standard
stop word list
• Further research in stemming [cross domain research]
• Comparison with other document clustering algorithms
• Comparison with other information retrieval methods](https://image.slidesharecdn.com/amharicdocumentclustering-111208072442-phpapp02/85/Amharic-document-clustering-18-320.jpg)


This document discusses document clustering in the Amharic language for information browsing and retrieval. It introduces the challenges of searching and accessing information in Amharic due to the growing amount of digital documents. The document then describes the process of document clustering, which groups documents based on similarities to organize information. Key steps in the clustering process include document preprocessing, vector representation, and hierarchical clustering. Experimental results show that tuning the global support threshold is important for creating the desired hierarchy, and stemming affects cluster overlap. Future work could involve developing standard Amharic language resources and comparing different clustering and information retrieval methods.























































































