





![Experiment on the English-Amharic
bilingual corpus
Mining the parallel corpus
• There are five steps to process a bilingual text corpus
used for SMT system. (by Besacier et.al, 2009):
– Raw data collection: proclamation and parallel
news corpora have been collected
– Document alignment: manual & automatic
– Tokenization: splitting and trimming
– Sentence splitting: done using the punct. [?!. ፡፡ ]
– Sentence alignment: almost completed](https://image.slidesharecdn.com/mulugebreegziabher-111208073038-phpapp02/85/Bilingual-Data-Mining-for-the-English-Amharic-Statistical-Machine-Translation-EASMT-8-320.jpg)
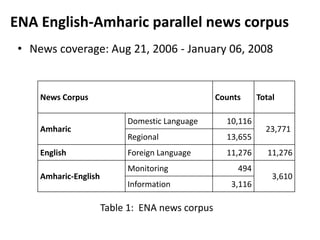
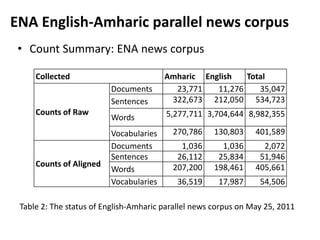


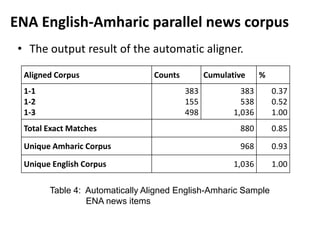

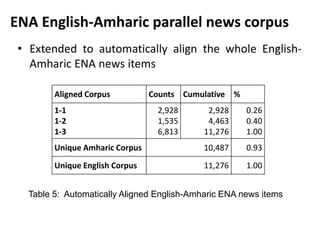


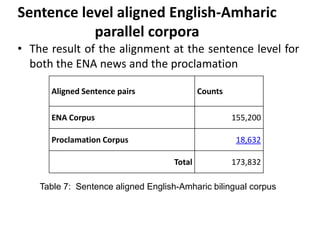



This document discusses experiments conducted on developing an English to Amharic statistical machine translation system. It summarizes the collection and processing of two parallel corpora: (1) An ENA news corpus containing over 35,000 documents and 500,000 words aligned at the sentence level. (2) A parliamentary corpus containing over 1,200 documents and 500,000 words aligned at the sentence level. The document outlines challenges in aligning the corpora and reports on automatic alignment results. It concludes that further increasing corpus size and integrating linguistic knowledge can help improve translation quality.



















































































