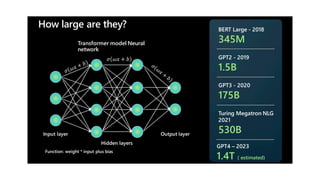
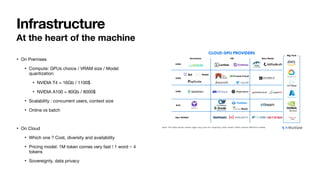
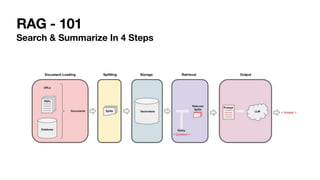
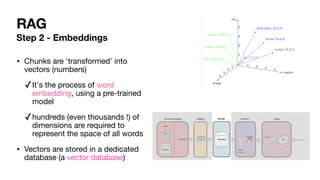
The document discusses the intricacies of generative AI and large language models (LLMs), focusing on transformer architectures and training requirements involving extensive datasets. It outlines the process of retrieval augmented generation (RAG), detailing steps from document loading to generating natural language answers, while also addressing practical considerations like model selection, cost efficiency, and data privacy. Various challenges and techniques related to performance, data handling, and user interaction in AI applications are highlighted.


































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)










