















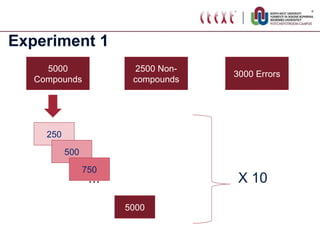



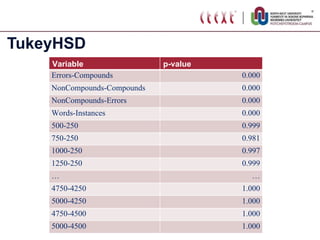
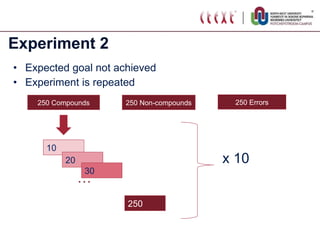
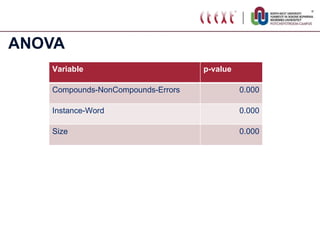
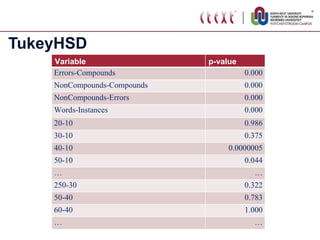




The document proposes standardizing test sets for evaluating compound analyzers by establishing parameters for a standard test set. It discusses evaluating compound analyzers on different sized test sets containing compound words, non-compound words, and error words. Experiments compare analyzer performance on test sets of varying sizes, finding sizes below 250 words are too small and sizes above 1250 words show no significant differences in results. The proposed standard test set consists of 500 examples each of compounds, non-compounds, and errors for a total of 1500 words.






















































