

![Introduction
Document Clustering is extremely useful gizmo in
today’s world wherever a lot of textual records and
knowledge square measure keep and retrieved
electronically [Publié le lundi – 2016].
The document browsing becomes easier, friendly and
economical.
Traditional clustering methods are not effective on
textual clustering [Charu & Zha-2012].
Per-Processing and Chose appropriate Clustering
Method is Most important to get accurate Document
Clustering.](https://image.slidesharecdn.com/modelofsemantictextualdocumentclustering-181003121258/75/Model-of-semantic-textual-document-clustering-4-2048.jpg)
![Problem Statement
It is together a challenge to look out the useful data from the
large documents [Charu & Zha-2012].
The traditional document cluster unit high-dimensional about
texts. [Hemant & Cappe-2009].
The presence of logical structure clues within the document,
scientific criteria and applied math similarity measures chiefly
accustomed figure thematically coherent, contiguous text
blocks in unstructured documents [Qi Sun & Wu-2008].
Recent segmentation techniques have taken advantage of
advances in generative topic modeling algorithms, which were
specifically designed to spot topics at intervals text to cipher
word–topic distributions [J.G. Lee & Whang-2007].](https://image.slidesharecdn.com/modelofsemantictextualdocumentclustering-181003121258/75/Model-of-semantic-textual-document-clustering-5-2048.jpg)


![Related Studies (Textual Document Clustering)
Document Clustering is that the
tactic of grouping a bunch of
records into clusters
[Amanpreet Kaur & Amarpreet
Singh –2014].
Documents within each group
area unit like each other, in
different words, they belong to
same topic or subtopic.
A document clustering formula is typically captivated with the
employment of a pair-wise distance live between the individual
documents to be clustered.
Most of the techniques utilized in document clustering have an
effect on a document as a bag of words.](https://image.slidesharecdn.com/modelofsemantictextualdocumentclustering-181003121258/75/Model-of-semantic-textual-document-clustering-8-2048.jpg)


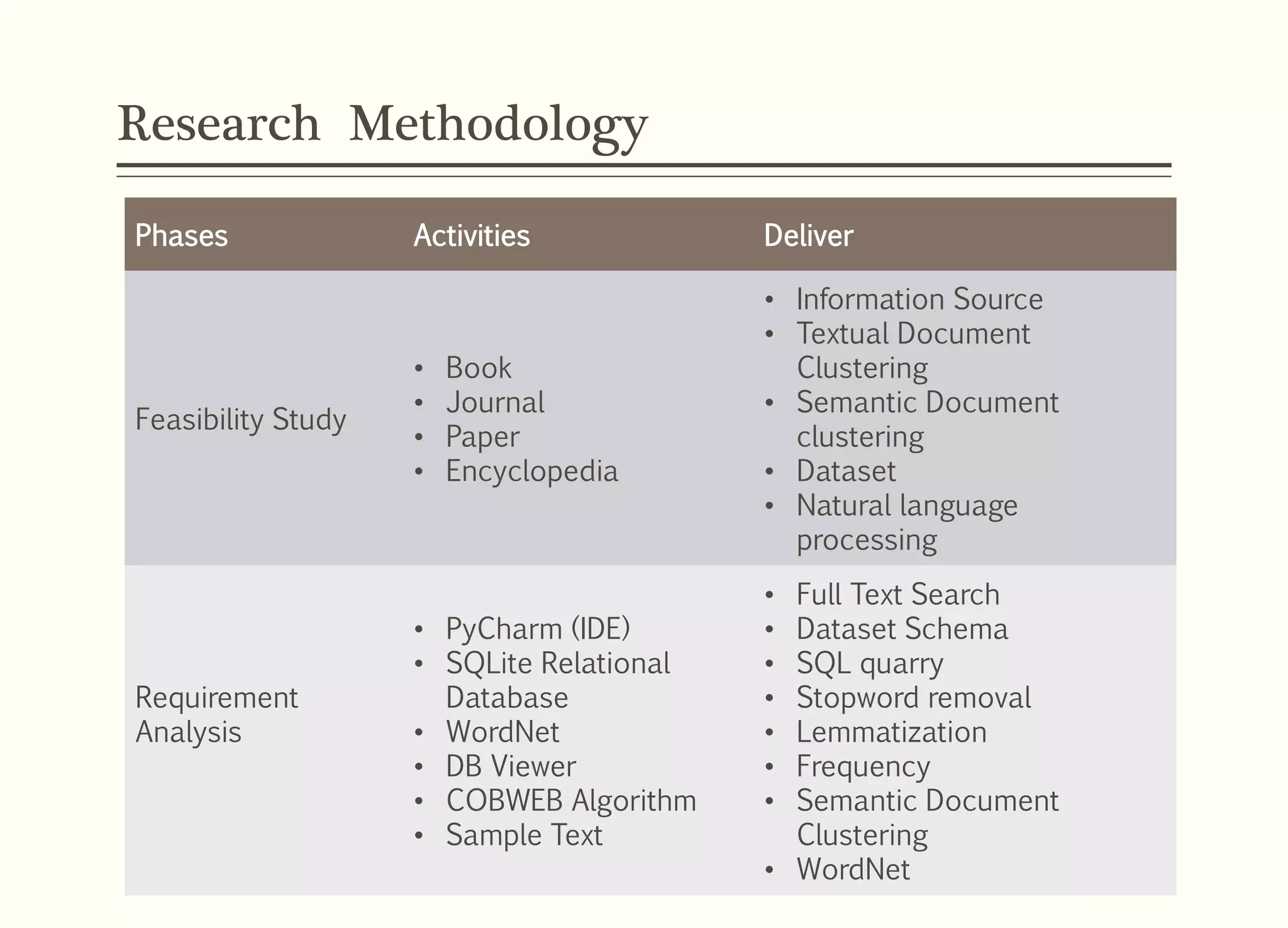






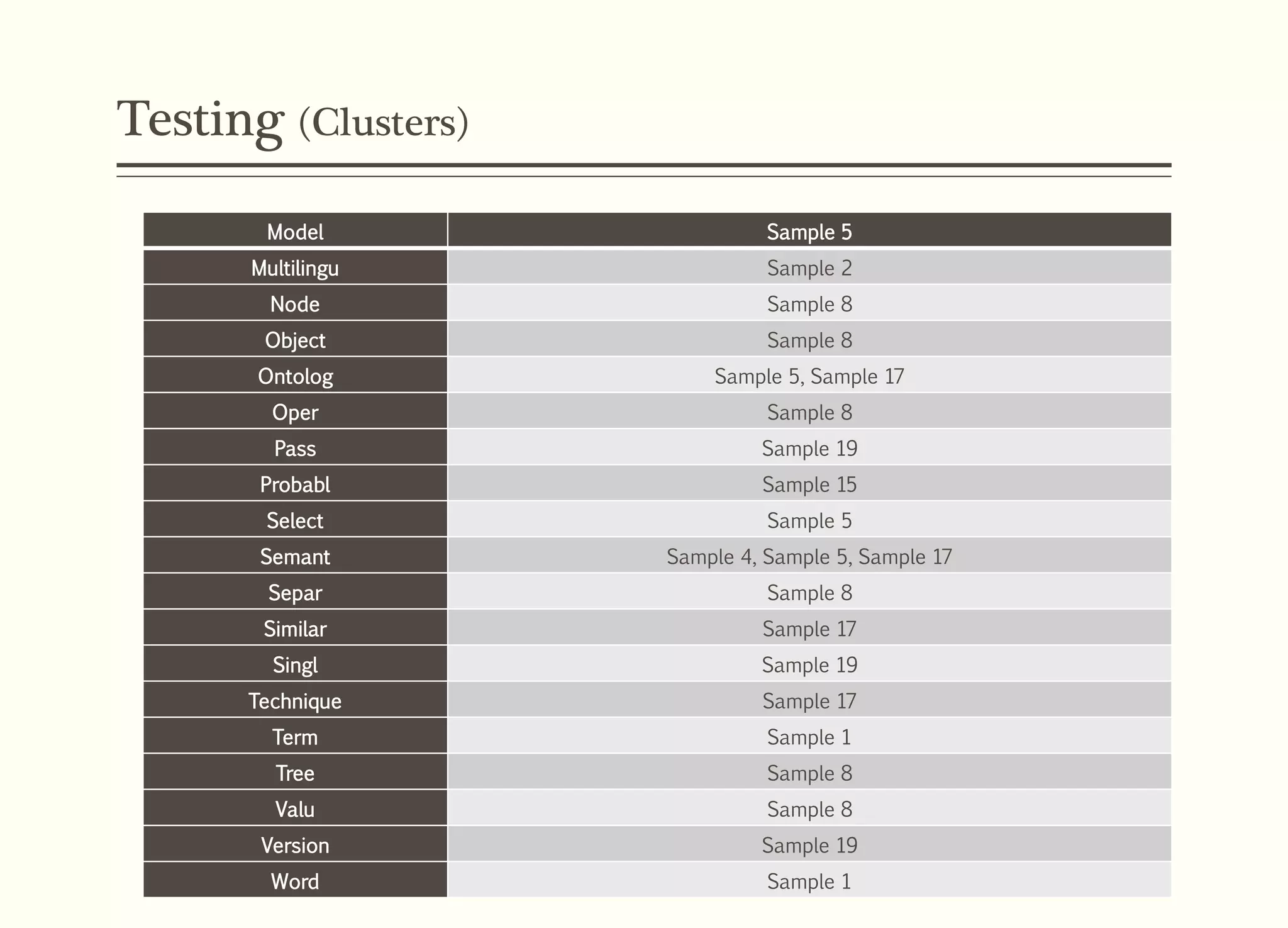






This document presents a model for semantic textual document clustering supervised by Assoc. Prof. Dr. Waelyafoozs, discussing the difficulties in retrieving information from vast unstructured textual data. It outlines a structured approach including a research problem, questions, objectives, methodology using various algorithms, and an experimental setup to evaluate clustering accuracy. The framework aims to enhance document clustering accuracy through semantic relations and wordnet integration, achieving 79.60% overall clustering accuracy.



































































