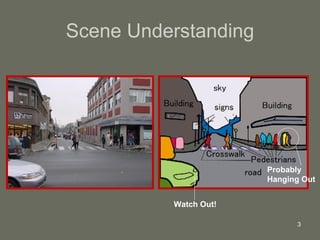
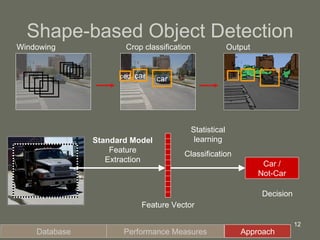
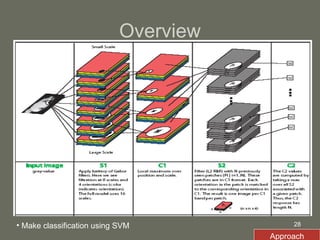
1. The document presents a framework for visual object recognition inspired by the visual cortex. It uses texture-based and shape-based pathways to recognize objects in complex scenes.
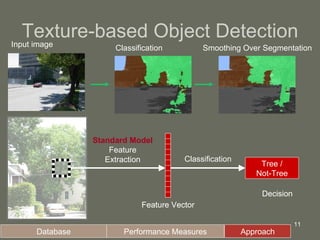
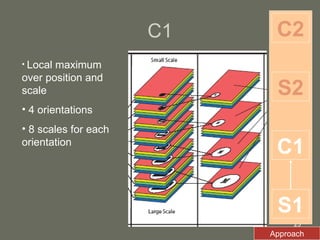
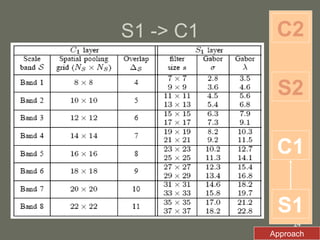
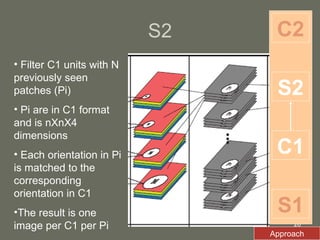
2. The model first applies Gabor filters to extract features, then uses complex cells to maximize responses locally. Simple cells then correlate the features with prototype templates before complex cells find the global maximum.
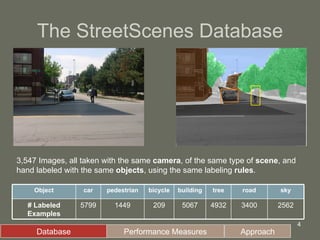
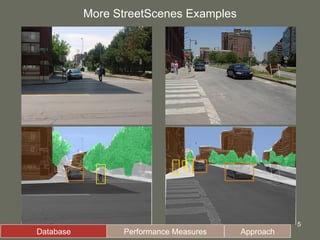
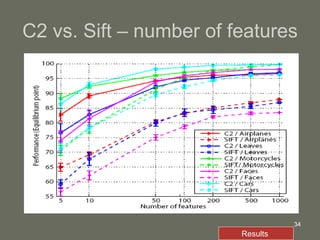
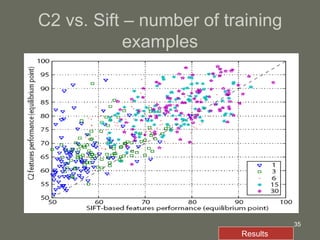
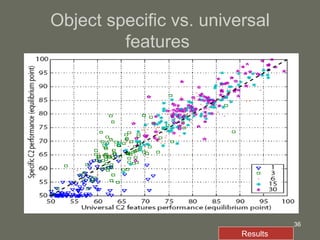
3. The model is tested on a street scene image database, showing it can learn from fewer examples than SIFT features and outperforms using object-specific versus universal features.