Downloaded 27 times
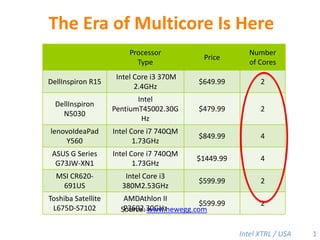







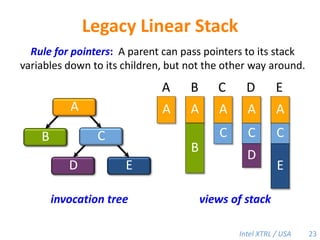

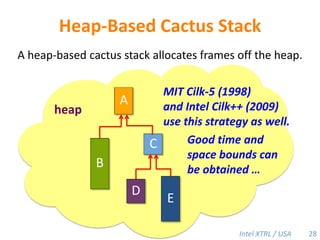





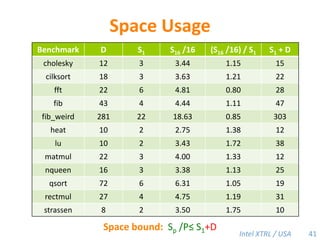

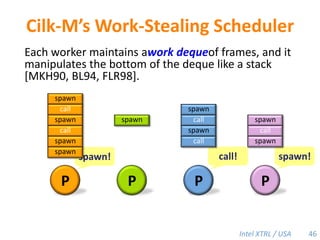
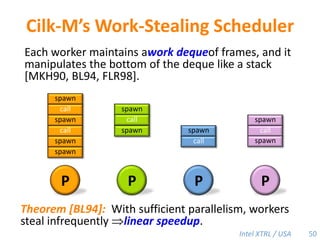

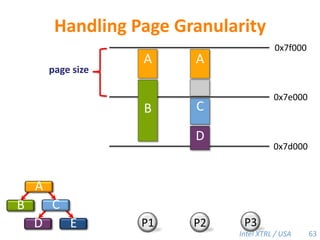

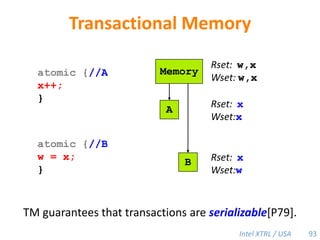
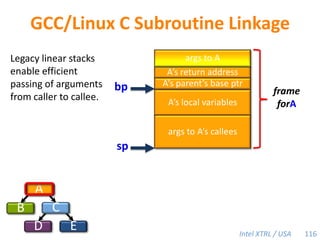
![Cilk-M’s Work-Stealing SchedulerEach worker maintains awork dequeof frames, and it manipulates the bottom of the deque like a stack [MKH90, BL94, FLR98].spawncallspawnspawnspawncallspawnspawncallPPPP43](https://image.slidesharecdn.com/mitcilk-110324143858-phpapp01/85/Mit-cilk-72-320.jpg)
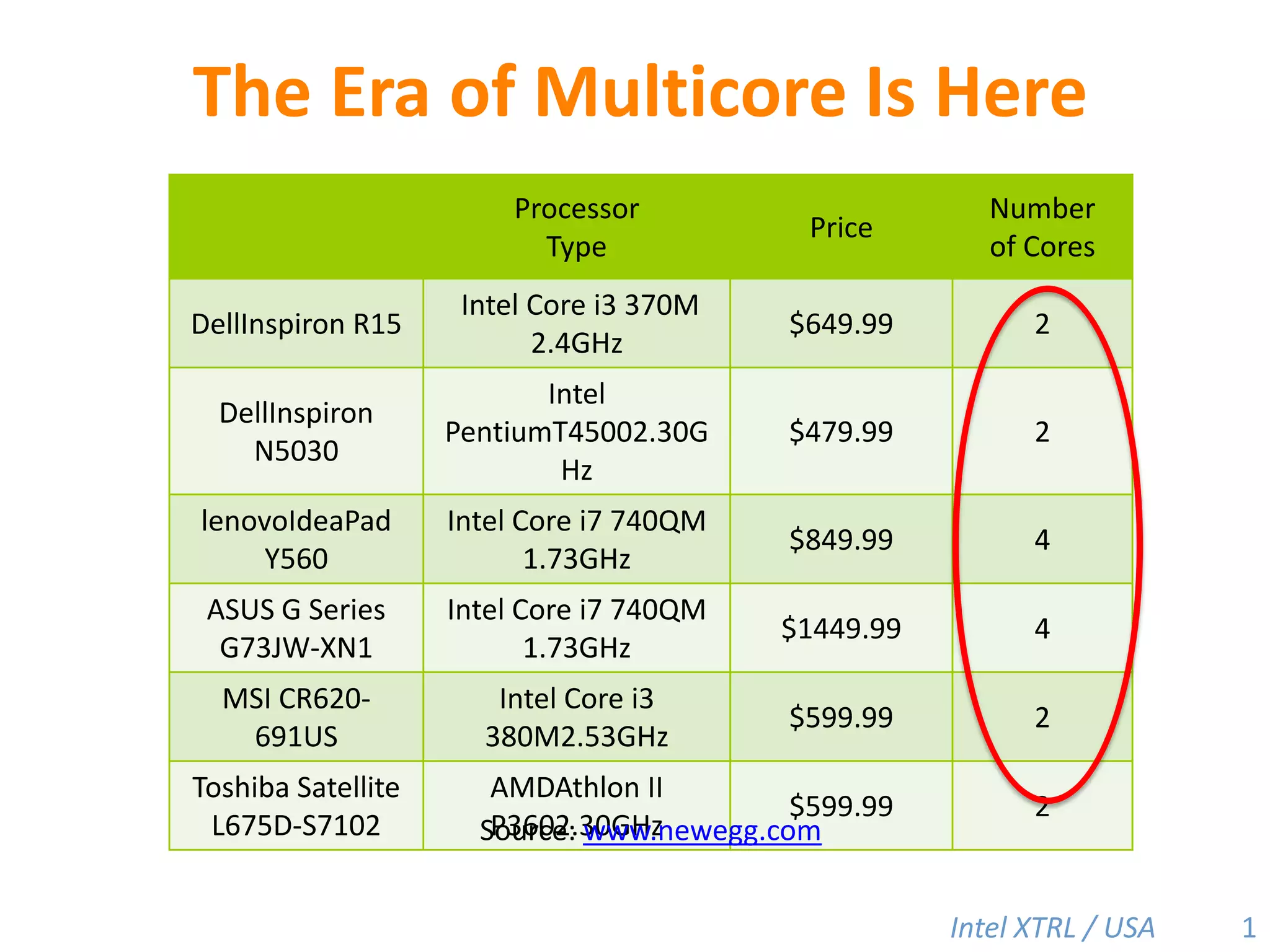
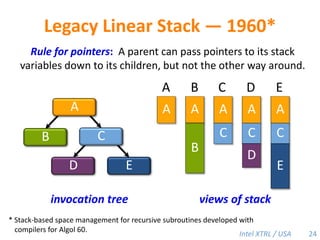
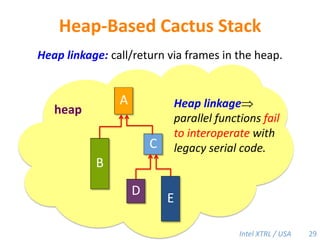
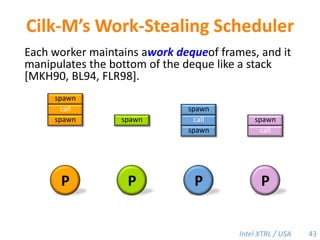
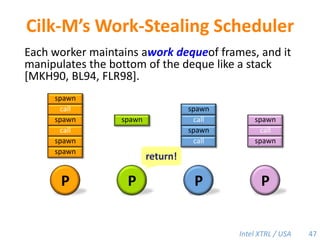
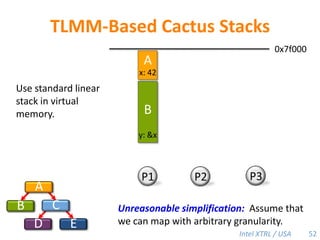
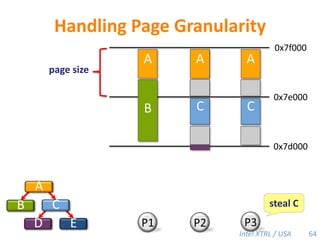
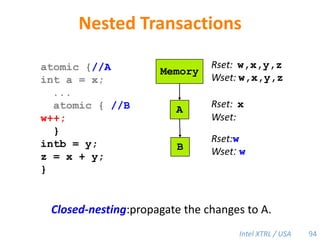
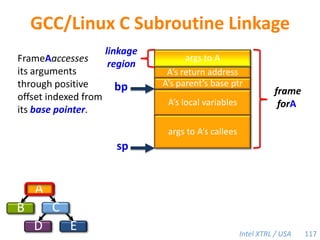
![Cilk-M’s Work-Stealing SchedulerEach worker maintains awork dequeof frames, and it manipulates the bottom of the deque like a stack [MKH90, BL94, FLR98].spawncallspawnspawnspawncallspawncallspawncallcall!PPPP44](https://image.slidesharecdn.com/mitcilk-110324143858-phpapp01/85/Mit-cilk-73-320.jpg)
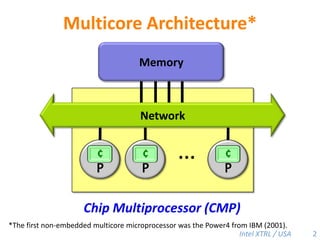
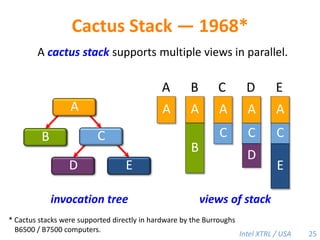
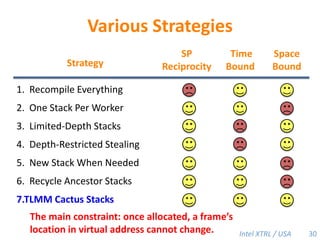
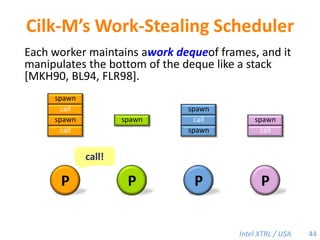
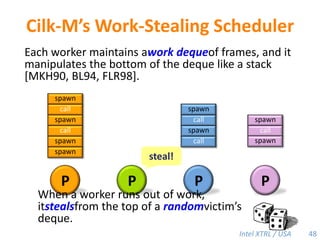
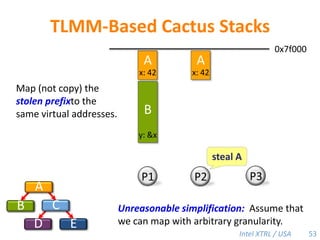
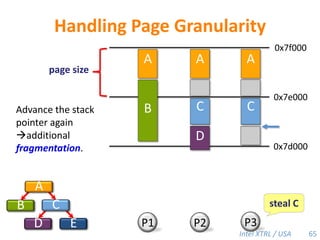
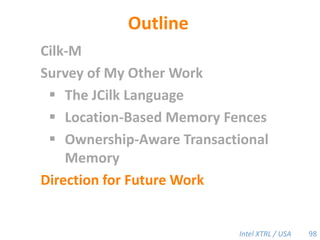
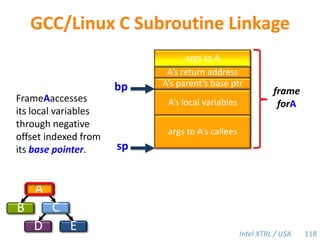
![Cilk-M’s Work-Stealing SchedulerEach worker maintains awork dequeof frames, and it manipulates the bottom of the deque like a stack [MKH90, BL94, FLR98].spawncallspawnspawnspawncallspawncallspawncallspawnspawn!PPPP45](https://image.slidesharecdn.com/mitcilk-110324143858-phpapp01/85/Mit-cilk-74-320.jpg)
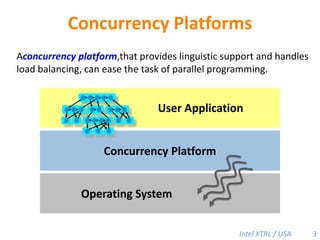
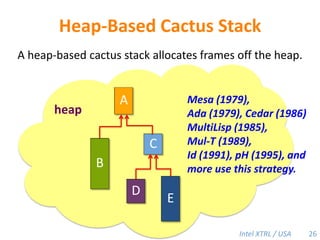
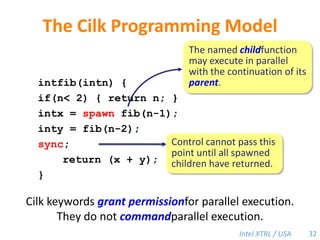
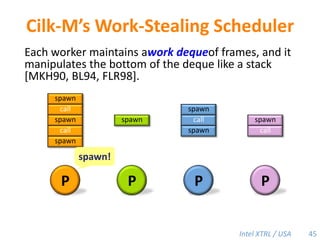
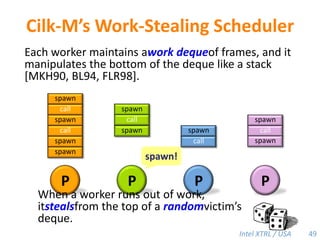
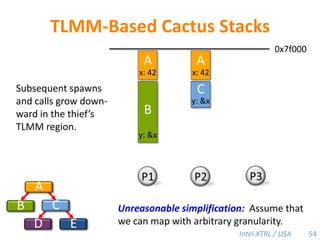
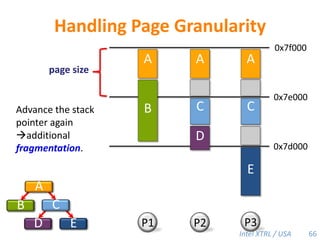
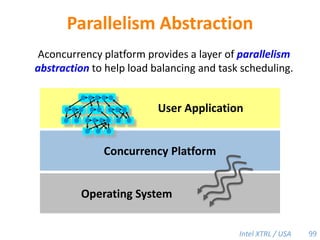
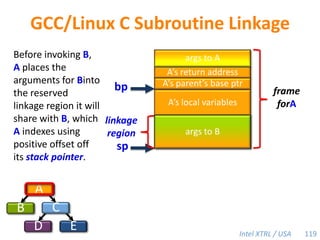
![Cilk-M’s Work-Stealing SchedulerEach worker maintains awork dequeof frames, and it manipulates the bottom of the deque like a stack [MKH90, BL94, FLR98].spawncallspawnspawnspawncallspawncallspawncallspawncallspawncall!spawn!spawn!spawnPPPP46](https://image.slidesharecdn.com/mitcilk-110324143858-phpapp01/85/Mit-cilk-75-320.jpg)
![Cilk-M’s Work-Stealing SchedulerEach worker maintains awork dequeof frames, and it manipulates the bottom of the deque like a stack [MKH90, BL94, FLR98].spawnspawncallspawncallspawnspawnspawncallcallspawncallspawnreturn!spawnPPPP47](https://image.slidesharecdn.com/mitcilk-110324143858-phpapp01/85/Mit-cilk-76-320.jpg)
![Cilk-M’s Work-Stealing SchedulerEach worker maintains awork dequeof frames, and it manipulates the bottom of the deque like a stack [MKH90, BL94, FLR98].spawnspawncallcallspawnspawnspawncallcallspawncallspawnsteal!spawnPPPPWhen a worker runs out of work, itstealsfrom the top of a randomvictim’s deque.48](https://image.slidesharecdn.com/mitcilk-110324143858-phpapp01/85/Mit-cilk-77-320.jpg)
![Cilk-M’s Work-Stealing SchedulerEach worker maintains awork dequeof frames, and it manipulates the bottom of the deque like a stack [MKH90, BL94, FLR98].spawnspawncallcallspawnspawnspawncallcallspawnspawncallspawnspawn!spawnPPPPWhen a worker runs out of work, itstealsfrom the top of a randomvictim’s deque.49](https://image.slidesharecdn.com/mitcilk-110324143858-phpapp01/85/Mit-cilk-78-320.jpg)
![Cilk-M’s Work-Stealing SchedulerEach worker maintains awork dequeof frames, and it manipulates the bottom of the deque like a stack [MKH90, BL94, FLR98].spawnspawncallcallspawnspawnspawncallcallspawnspawncallspawnspawnPPPPTheorem [BL94]: With sufficient parallelism, workers steal infrequently linear speedup.50](https://image.slidesharecdn.com/mitcilk-110324143858-phpapp01/85/Mit-cilk-79-320.jpg)

















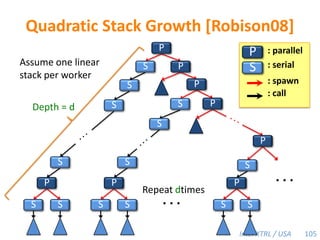
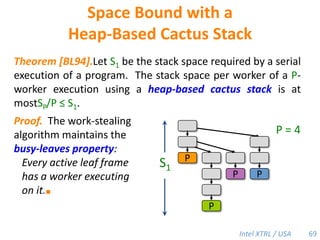
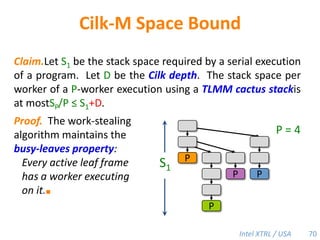
![Space Bound with a Heap-Based Cactus StackTheorem [BL94].Let S1 be the stack space required by a serial execution of a program. The stack space per worker of a P-worker execution using a heap-based cactus stack is at mostSP/P ≤ S1.Proof. The work-stealing algorithm maintains the busy-leaves property:Every active leaf frame has a worker executing on it.■P = 4S1PPPP69](https://image.slidesharecdn.com/mitcilk-110324143858-phpapp01/85/Mit-cilk-108-320.jpg)
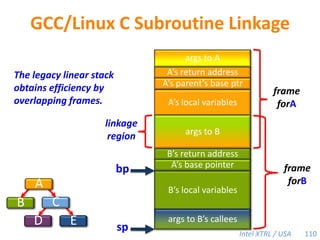
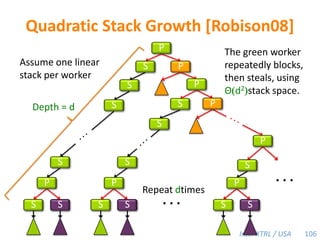
![Performance Bound with aHeap-Based Cactus StackDefinition.TP— execution time on P processorsT1— work T∞— spanT1 / T∞ — parallelismTheorem [BL94]. A work-stealing scheduler can achieve expected running timeTP=T1 / P + O(T∞)on P processors.Corollary. If the computation exhibits sufficient parallelism(P ≪T1 / T∞ ), this bound guarantees near-perfect linear speedup (T1 / Tp ≈ P). 72](https://image.slidesharecdn.com/mitcilk-110324143858-phpapp01/85/Mit-cilk-111-320.jpg)

![E.g., MCS locks [MCS91]:](https://image.slidesharecdn.com/mitcilk-110324143858-phpapp01/85/Mit-cilk-130-320.jpg)


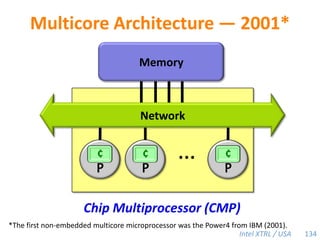
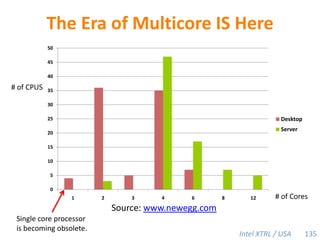
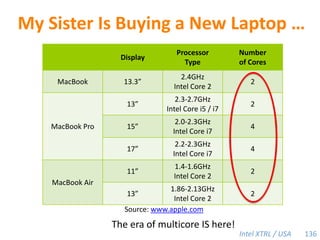

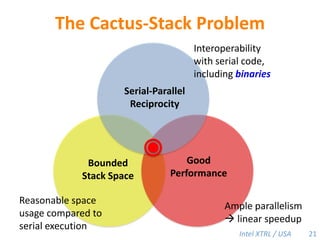
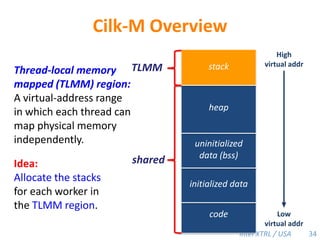
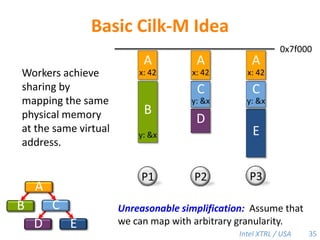
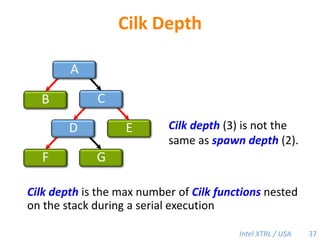
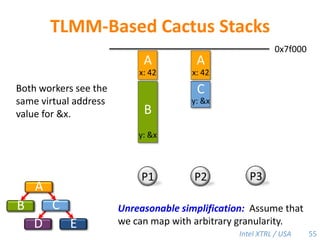
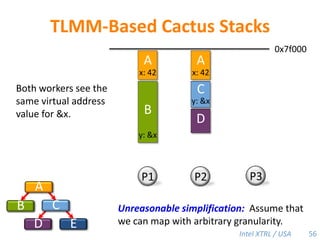
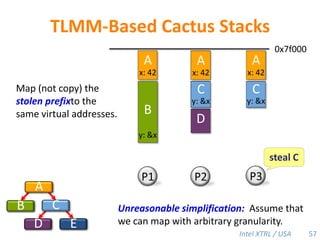
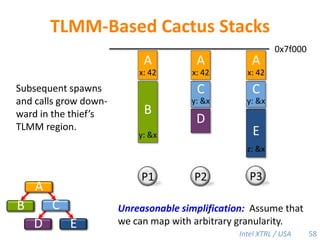
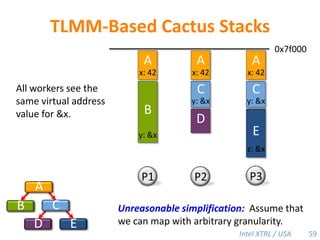
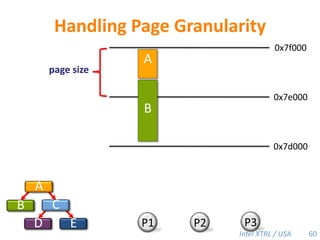
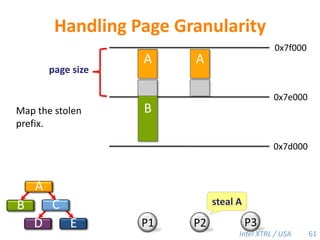
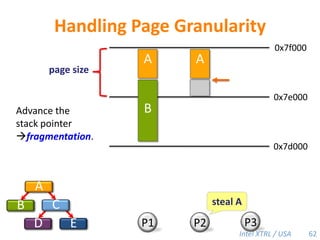
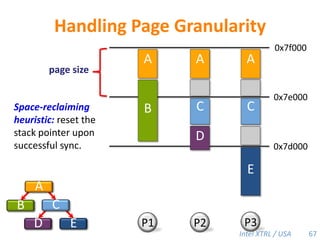
Cilk-M is a work-stealing runtime system that solves the cactus stack problem using thread-local memory mapping (TLMM). Each worker maintains its own deque of frames and manipulates the bottom of the deque like a stack. When a worker runs out of work, it steals frames from the top of a random victim's deque. This allows Cilk-M to achieve linear speedup and bounded stack space while maintaining serial-parallel reciprocity and interoperability with legacy code.















































